面试官 : 今天要不来聊聊Redis吧?
候选者 :好
候选者 :我个人是这样理解的:无论Redis也好、MySQL也好、HDFS也好、HBase也好,他们都是存储数据的地方
候选者 :因为它们的设计理念的不同,我们会根据不同的应用场景使用不同的存储
候选者 :像Redis一般我们会把它用作于缓存
候选者 :当然啦,日常有的应用场景比较简单,用个HashMap也能解决很多的问题了,没必要上Redis
候选者 :这就好比,有的单机限流可能应对某些场景就够用了,也没必要说一定要上分布式限流把系统搞得复杂

面试官 : 你在项目里有用到Redis吗?怎么用的?
候选者 :Redis肯定是用到的,我负责的项目几乎都会有Redis的踪影
候选者 :我举几个我这边项目用的案例呗?
面试官 :嗯
候选者 :我这边负责消息管理平台,简单来说就是发消息的
候选者 :那发完消息肯定我们是得知道消息有没有下发成功的,是吧?
候选者 :于是我们系统有一套完整的链路追踪体系
候选者 :其中实时的数据我们就用Redis来进行存储,有实时肯定就会有离线的嘛(离线的数据我们是存储到Hive的)
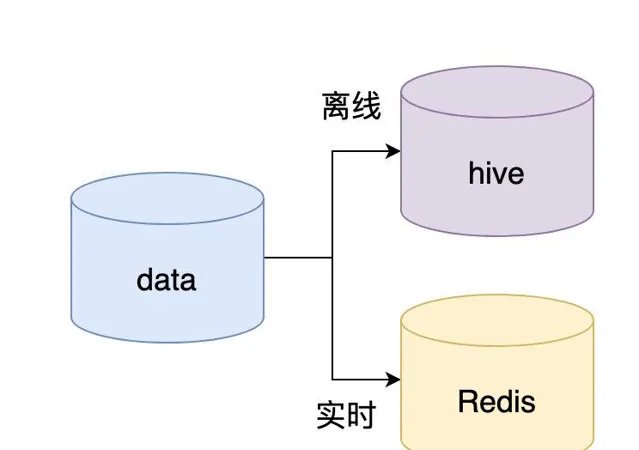
候选者 :对消息进行实时链路追踪,我这边就用了Redis好几种的数据结构
候选者 :分别有Set、List和Hash
面试官 :嗯….
候选者 :我再稍微铺垫下链路追踪的背景吧~
候选者 :要在消息管理平台发消息,首先得在后台新建一个「模板」,有模板自然会有一个模板ID
候选者 :对模板ID进行扩展,比如说加上日期和固定的业务参数,形成的ID可以唯一标识某个模板的下发链路
候选者 :在系统上,我这边叫它为UMPID
候选者 :在发送入口处会对所有需要下发的消息打上UMPID,然后在关键链路上打上对应的点位

面试官 :嗯,你继续吧
候选者 :接下来的工作就是清洗出统一的模型,然后根据不同维度进行处理啦。比如说:
候选者 :我要看某一天下发的所有模板有哪些,那只要我把清洗出来后数据的,将对应UMPID扔到了Set就好了
候选者 :我要看某一个模板的消息下发的整体链路情况,那我以UMPID为Key,Value是Hash结构,Key是state,Value则是人数
候选者 :这里的state我们在下发的过程中打的关键点位,比如接收到消息打个51,消息被去重了打个61,消息成功下发了打个81…

候选者 :以UMPID为Key,Hash结构的Key(State)进行不断的累加,就可以实现某一个模板的消息下发的整体链路情况
候选者 :我要看某个用户当天下发的消息有哪些,以及这些消息的整体链路是如何。
候选者 :这边我用的是List结构,Key是userId,Value则是UMPID+state(关键点位)+processTime(处理时间)
面试官 :嗯….
候选者 :简单来说,就是通过Redis丰富的数据结构来实现对下发消息多个维度的统计
候选者 :不同的应用场景选择不同的数据结构,再等到透出做处理的时候,就变得十分简单了
候选者 :消息下发过程中去重或者一般正常的场景就直接Key-Value就能符合需求了
候选者 :像bitmap、hyperloglogs、sortset、steam等等这些数据结构在我所负责的项目用得是真不多
候选者 :要是我有机会去到贵公司,贵公司有相关的应用场景,我相信我也很快就能掌握

候选者 :这些数据结构底层都由对应的object来支撑着,object记录对应的「编码」
候选者 :其实就是会根据key-value存储的数量或者长度来使用选择不同的底层数据结构实现
候选者 :比如说:ziplist压缩列表这个底层数据结构有可能上层的实现是list、hash和sortset
候选者 :Hash结构的底层数据结构可能是hash和ziplist
候选者 :在节省内存和性能的考量之中切换
候选者 :Redis还是有点屌的啊。

面试官 : 就你上面那个实时链路场景,可以用其他的存储替代吗?
候选者 :嗯,理论上是可以的(或许可以尝试用HBase),但总体来说没这么好吧
候选者 :因为Redis拥有丰富的数据结构,在透出的时候,处理会非常的方便。
候选者 :如果不用Redis的话,还得做很多解析的工作
候选者 :并且,我那场景的并发还是相当大的(就一条消息发送,可能就产生10条记录)
候选者 :监控峰值命令处理数会去到20k+QPS,当然了,这场景我肯定用了Pipeline的(不然处理会慢很多)
候选者 :综合上面并发量和实时性以及数据结构,用Redis是一个比较好的选择

面试官 :嗯…. 你觉得为什么Redis可以这么快?
候选者 :首先,它是纯内存操作,内存本身就很快
候选者 :其次,它是单线程的,Redis服务器核心是基于非阻塞的IO多路复用机制,单线程避免了多线程的频繁上下文切换问题
候选者 :至于这个单线程,其实官网也有过说明(:表示使用Redis往往的瓶颈在于内与和网络,而不在于CPU
面试官 :了解。

【Java开源】消息推送平台
我推荐一个 拥有从零开始的文档的项目 ,既能用于毕设又可以在面试的时候大放异彩。
该项目业务极容易理解,代码结构还算是比较清晰,最可怕的是几乎每个方法和每个类都带有中文注释
拥有非常全的文档,作者从零搭建的过程一一都有记录,项目使用了蛮多的可靠和稳定的中间件的,包括并不限于SpringBoot、SpringDataJPA、MySQL、Docker、docker-compose、Kafka、Redis、Apollo、prometheus、Grafana、GrayLog、xxl-job等等。在使用每一个技术栈之前都讲述了为什么要使用,以及它的业务背景。我看过,他所说的场景是完全贴合线上环境的。
跟着README文档的部署使用姿势就能跑起来,一步一步debug挺有意思的,作者还搞了个前端后台管理系统就让整个系统变得更好理解了。并且在GitHub或者Gitee提的Issue几乎都会有回复,也非常乐于合并开发者们的pull request,会让人参与感贼强。
我相信在校、工作一年左右或常年做内网CRUD后台的同学去看看肯定会有所启发,作者会经常在群里回答该项目相关的问题和代码设计思路。
B站也在开始更新消息推送平台的视频哟!
目前这个项目GitHub和Gitee加起来已经 5K stars 了,我相信破万是迟早的事情。 嗯,没错。这个项目叫做austin, 是我写的
消息推送平台-Austin就是 奔着真实互联网线上项目 去设计和实现的,将项目克隆下来把中间件换成目前公司在用的,完善下基础建设它就能成为线上项目

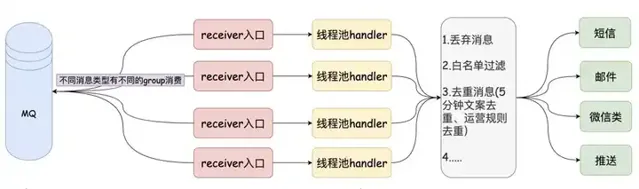
austin项目 核心功能 :统一的接口发送各种类型消息,对消息生命周期全链路追踪
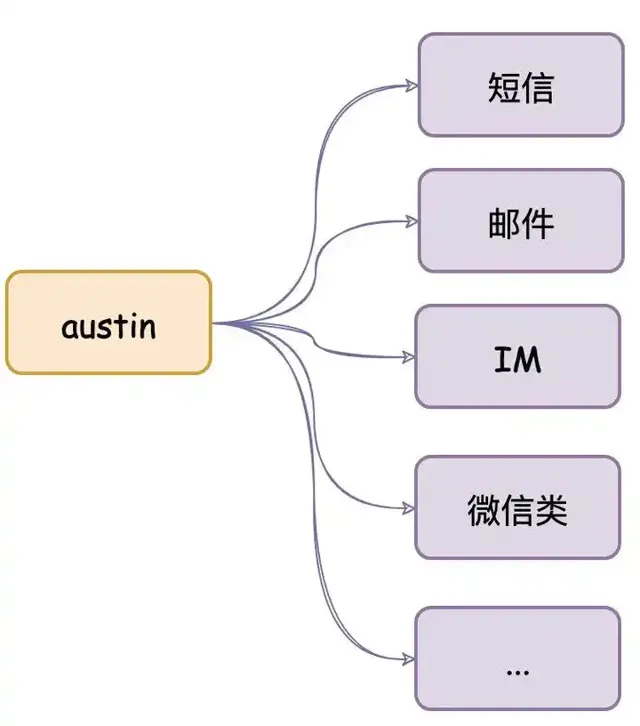
项目出现意义 :只要公司内有发送消息的需求,都应该要有类似austin的项目,对各类消息进行统一发送处理。这有利于对功能的收拢,以及提高业务需求开发的效率
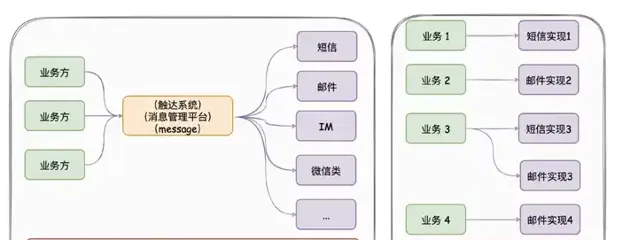
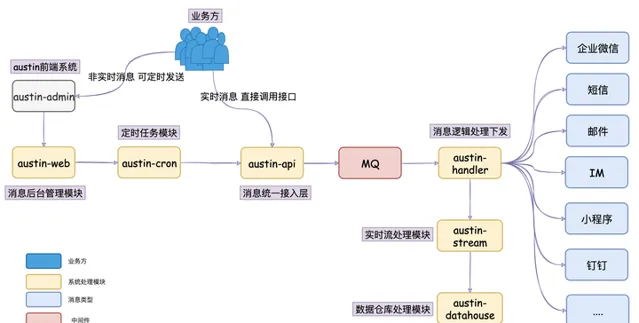
austin项目 核心流程 :austin-api接收到发送消息请求,直接将请求进MQ。austin-handler消费MQ消息后由各类消息的Handler进行发送处理


项目Gitee链接:
项目GitHub链接:










