这类算法很多。实际上,这些算法的特点就是往往在工业界实践里早就已经大规模在使用了(并且效果也都不错),但完备的数学理论要很久以后才出现。
一个简单的例子是分布式优化领域里的很多算法,比如现在很多人都很熟悉的ADMM算法(交替方向乘子法),工业界版本早在几十年前就有人用了,但完善的分析是最近几年才慢慢出现的。
不过这边说两个我个人觉得很有意思的「算法」,因为它们有着更加生动的工业应用背景,也被归类于所谓的 运营管理 (Operations Management)问题。
一、流程柔性(Process Flexibility)工艺中的长链设计(Long Chain Design)/稀疏结构设计(Sparse Design)
这个问题实际中的应用很好理解,无非是一个制造业公司设计工厂/生产线的问题。比如我们有很多种不同(但可能相近)的产品,如可口可乐的基础版可乐,无糖可乐,樱桃味可乐等等。每种不同类型的可乐都有一定的需求。我们的一个决策是:我们的几家工厂应该如何分工,比如这些工厂基础的生产线都是生产基础可乐的, 我们要不要花一些钱添置更多的生产线,让它们生产更多种类的可乐,以满足不同地区对不同可乐的需求 ,这也就是所谓的process flexibility design。
也就是说,我们的设计可以抽象看成一个 二分图 (bipartite graph)。你可以认为 右边的节点表示顾客对不同产品的需求,而左边的节点是我们的工厂们 。这里从左到右的箭头就表示,这每一条 从工厂x到产品y的arc意味着工厂x有能力生产产品y 。而工业界实践里很早就开始用的一种经验化的稀疏设计便是所谓的 long chain design (见下图左),即每个工厂的degree都是2(只需要连接2个产品),且最后整体的图上形成一个闭环(cycle),即long chain是个 closed chain (定义见下右图)。这也很直观, 每个厂就生产两种可乐,每个可乐也由两个厂来生产 !
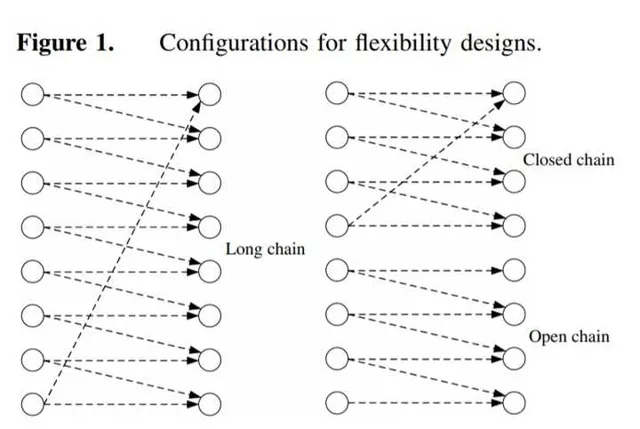
那么问题就来了,虽然工业界这套「算法」早就用了几十年,而且实际上发现在各种情况下这个long chain design相比所谓的full flexibility design(即所有的左右节点全部连起来,当然这个design的造价就很高了)表现差不多, 但理论上其实一直没有一个很好的模型可以来解释为啥这个long chain design其实就挺好 。这个问题在理论上第一次在下面的paper里提出(有个早期版本是91年发表的)。
Jordan, William C., and Stephen C. Graves. "Principles on the benefits of manufacturing process flexibility." Management Science 41.4 (1995): 577-594.
然后过了 20年左右 ,才由下面的paper 第一次在一个严格的数学框架下 (和对demand比较mild的假设下) 证明了long chain design在所有2-flexibility design中是渐进最优 (asymptotically optimal)的。这篇paper很核心的一点是利用了flexibility design在bipartite graph上的 supermodular 的。
Simchi-Levi, David, and Yehua Wei. "Understanding the performance of the long chain and sparse designs in process flexibility." Operations research 60.5 (2012): 1125-1141.
这之后,下列paper利用 半正定规划(SDP)和概率论中的优化不等式 的技巧证明了long chain design和full flexibility design 非渐进(non asymptotic)的deviation bound ,并通过数值实验表明在大多数情况下确实这个bound都很小!
Wang, Xuan, and Jiawei Zhang. "Process flexibility: A distribution-free bound on the performance of k-chain." Operations Research 63.3 (2015): 555-571.
这类模型在随机模型的queueing model里也可以有intepretation。比如可见下面的文章。
Tsitsiklis, John N., and Kuang Xu. "On the power of (even a little) resource pooling." Stochastic Systems 2.1 (2012): 1-66.
这类模型实际上包含着非常精彩的数学,从这些研究中你可以看到 概率论与随机模型,和优化理论,组合分析 的优美交叉。也因此在那几年里,这个topic成为了运筹学、管理科学的一个热门研究领域。可惜我感觉知乎上对这些topic感兴趣的人不会很多,这里就先不展开了。
二、基于两类采购(Dual Sourcing)的库存管理系统(inventory system)的最优补货策略
这又是一个物理上非常好理解的数学模型。所谓dual sourcing,就是说你(一般来说是你的角色是个零售商,retailer)的补货渠道上抽象认为有两类供应商(supplier), 一类给你补货的速度快但是收费高 (可以简单认为是 空运,express order ), 另一类给你补货的速度慢但是收费低 (可以简单认为是 陆运、海运,regular order )。这个时候我们为了应对日常的顾客需求 应该如何利用这两类供应商来进行日常的补货,使得总体的风险最低(比如断货和过多囤货),获得最高的收益呢 ?
这个问题可以写成一个多阶段的随机规划问题(multi-stage stochastic programming),或者随机动态规划(dynamic programming)。然而不幸的是,这个动态规划的最优策略长的非常奇怪,几十年中研究者都没发现有什么规律。
工业界实践来说自然不可能等你们学界这么弄,所以对这个问题也是早有一个 极易实现,著名的启发式算法 。这个策略有个好听的名字,叫做 tailored base-surge policy (TBS 策略)。简单来说,我们每个period都用 regular order进一个固定数量(constant order) ,作为我们的base,「基本盘」。然后再根据需求预测计算一个 express order的order-up-to level ,即只要我们总的进货量没到这个数,就进到这个数,不然就不使用任何express order。也就是说TBS策略你实现的时候 只要每天知道两个「数」就可以了,两边进货策略完全按照这两个数来就行 。和前面的long chain design一样, 这个「算法」实现起来简单到看起来都不像个算法 。
最早关于这类问题理论上的讨论可以追溯到:
Whittemore, Alice S., and S. C. Saunders. "Optimal inventory under stochastic demand with two supply options." SIAM Journal on Applied Mathematics 32.2 (1977): 293-305.
而这类TBS策略,经过 40多年的猜想 ,才由如下paper严格地证明,在这类随机动态规划模型下是 渐进最优 (asymptotically optimal,注意这里的渐进指订货的lead time一直增大)的。
Xin, Linwei, and David A. Goldberg. "Asymptotic optimality of Tailored Base-Surge policies in dual-sourcing inventory systems." Management Science 64.1 (2017): 437-452.
其实我也比较好奇知乎上有多少做OM的同学了,看到评论区冒个泡好么?对不了解OM这个方向的同学,这两个例子应该也算是比较生动的科普了。
应用数学也可以很有意思,不是么?










