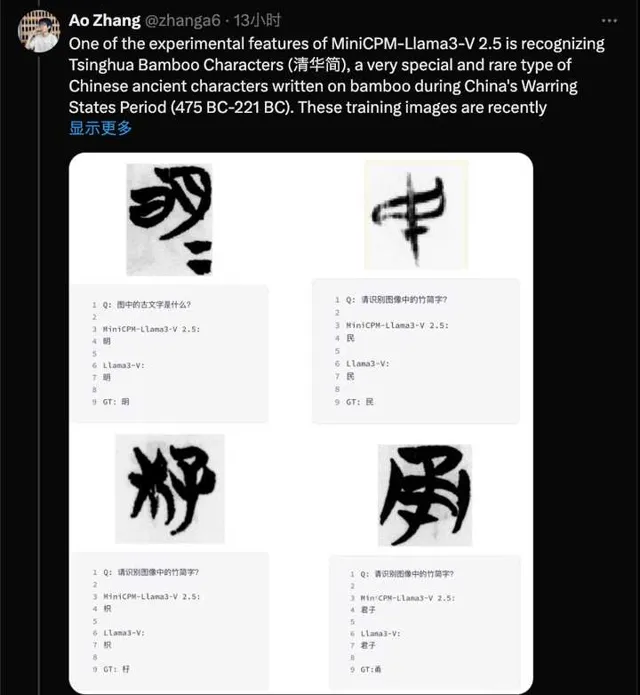
有感而发说几句。已经比较确信Llama3-V是对我们MiniCPM-Llama3-V 2.5套壳,比较有意思的证据是MiniCPM-Llama3-V 2.5研发时内置了一个彩蛋,就是对清华简的识别能力。这是我们从清华简逐字扫描并标注的数据集,并未公开,而Llama3-V展现出了一模一样的清华简识别能力,连做错的样例都一样。
人工智能的飞速发展离不开全球算法、数据与模型的开源共享,让人们始终可以站在SOTA的肩上持续前进。我们这次开源的 MiniCPM-Llama3-V 2.5 就用到了最新的Llama3 作为语言模型基座。而开源共享的基石是对开源协议的遵守,对其他贡献者的信任,对前人成果的尊重和致敬,Llama3-V团队无疑严重破坏了这一点。他们在受到质疑后已在Huggingface删库,该团队三人中的两位也只是斯坦福大学本科生,未来还有很长的路,如果知错能改,善莫大焉。
OpenBMB团队是开源社区的受益者,也一直是积极的贡献者,从最初的CPM模型、BM Infra系列,到后来的Ultra对齐技术、ChatDev等Agent项目系列,再到今年的MiniCPM。这次看到大家在twitter、github和pyq上对我们的支持和声援,让我们倍感欣慰,给我们更大的动力和信心继续拥抱开源共享。
这次事件还让我感慨的是过去十几年科研经历的斗转星移。回想2006年我读博时,大家的主要目标还是能不能在国际顶级会议上发篇论文;到2014年我开始做老师时,就只有获得国际著名会议的最佳论文等重要成果,才有机会登上系里的新闻主页;2018年BERT出来时,我们马上看到了它的变革意义,做出了知识增强的预训练模型ERNIE发在ACL 2019上,当时以为已经站到国际前沿了;2020年OpenAI发布了1700+亿参数GPT-3,让我们清醒认识到与国际顶尖成果的差距,知耻而后勇开始了「大模型」的探索;2022年底OpenAI推出的ChatGPT,让大众真切感受到AI领域国内外的差距,特别是2023年Llama等国际开源模型发布后,开始有「国外一开源、国内就自研」说法;而到了2024年的今天,我们也应该看到国内大模型团队如智谱-清华GLM、阿里Qwen、DeepSeek和面壁-清华OpenBMB正在通过持续的开源共享,在国际上受到了广泛的关注和认可,这次事件也算侧面反映我们创新成果受到的国际关注。

所以,从横向来看,我们显然仍与国际顶尖工作如Sora和GPT-4o有显著差距;同时,从纵向来看,我们已经从十几年的nobody,快速成长为人工智能科技创新的关键推动者。面向即将到来的AGI时代,我们应该更加自信积极地投身其中。
前段时间OpenBMB周年纪念,写过一段寄语,与大家共勉:「通用人工智能,是人类文明的共同梦想;人人为我、我为人人的开源精神,正是人类文明之光,迈向通用人工智能之路必须也必将由全人类智慧的开源共享而铸就。OpenBMB正是抱着这样的使命和愿景一路走来。星星之火,可以燎原,希望未来OpenBMB不断壮大,与全球AI从业者携手,加速迈向通用人工智能的星辰大海。」
欢迎关注点赞我们的MiniCPM-V项目:
github:https:// github.com/OpenBMB/Mini CPM-V
huggingface:openbmb/MiniCPM-Llama3-V-2_5 · Hugging Face











