作者:何建军 王国政|零跑科技
关于零跑
浙江零跑科技股份有限公司(leapmotor)作为一家科技型企业,是国内极少数拥有智能电动汽车完整自主研发能力并掌握核心技术的新能源汽车厂家,由浙江大华技术股份有限公司及其主要创始人共同投资成立,始终坚持核心技术的全域自研,为用户的出行和生活创造最大价值,致力成为值得尊敬的世界级智能电动车企品牌。
一直以来,在数据存储上我们的选择都是MongoDB和HBase,但是随着业务的加速扩张,写入速度太慢、支撑成本过高等问题也逐渐显现,具体来说,主要有以下几处痛点:
从降本增效的角度考虑,我们决定在C11新车型上试用下其他的数据库,在分析数据特点后,最终确定采用时序数据库。但市面上时序数据库产品众多,之所以选择TDengine,一是由于它比较突出的性能和成本管控能力,其次也是由于我和它的一些渊源。
为什么选择TDengine?
在接触一个新的数据库产品时,通常大家比较关注的无非就是两点:性能强、成本低,这也是我们选择TDengine的主要原因。
另外和TDengine的渊源要追溯到我的上一份工作,那时我对它就有过一些比较深入地了解,进入零跑要进行时序数据库选型时,发现大家都没有接触过,心里也都挺没有底的,我就把这段经历讲了出来,包括对TDengine的一些看法和见解。
我有多年大数据行业的工作经验,在了解到时序数据库后,也对市面上一些流行产品如OpenTSDB、InfluxDB都进行了一些调研。 对比之后发现TDengine是专门针对物联网、车联网业务场景去设计的,在解决这些行业数据问题上更有针对性,它不仅安装包很小,对集群资源消耗也很少,并且它创新的「一个数据采集点一张表」的数据模型,特别适合物联网这种多设备且信息量存储非常大的数据场景 。
因为有我之前的实践佐证,大家一致觉得这款数据库相对会更有保障,在各方的大力推动下,我们就开始搭载TDengine运作新业务了。
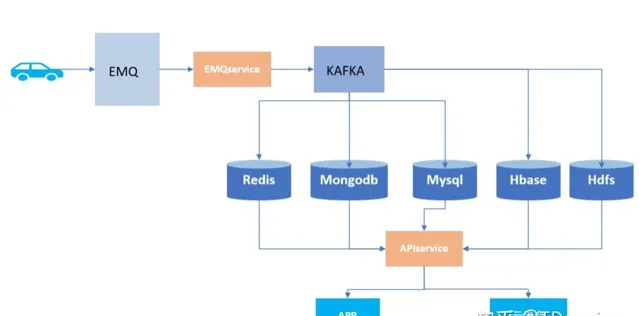
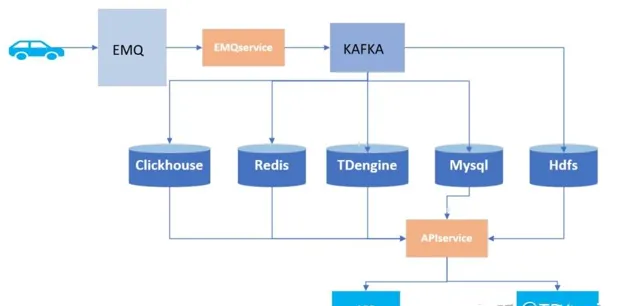
在搭载了TDengine之后,我们收获了以下的四点进步:
存在的问题和优化的空间
当然问题也是不可避免会存在的,对于我们来说TDengine是一款很新的数据库,相比较而言HBase肯定会在使用上更加稳定一些。我们的业务场景数据列本身就比较宽,有3000多列,而TDengine之前都是针对几十列。此外,还存在因开发集群时钟不准导致集群频繁重启、因数据量太大导致查询报错、连接资源超时等诸多在实际落地时遇到的问题。
但我们并不认为遇到问题就要一棍子打死,相反愿意给TDengine时间去进行优化。因为使用模式不一样,肯定会遇到诸多问题,如果基于此就放弃使用的话,那这款跟物联网场景非常契合的数据库就要和我们擦肩而过了。TDengine失去了一个经典的应用场景案例,我们也会因此失去一个更好的选择。
在TDengine小伙伴的支持下,上述问题也得到了很好的解决。我们前期使用taosdemo工具进行插入性能的测试,能达到200万每秒的入库性能。在查询这块,因为都是内部用户在使用,云平台查询并发并不高,所以没有进行非常深入的测试,其查询性能也能完美匹配我们的需求。
此外,在副本构建上他们也从专业角度给出了一些建议,我放在本文中,给有同样问题的同学们一些参考:
具体选择几个副本还是要看读写比,从现有架构出发的话,写入性能要求更高,两副本加一个冷备会相对更稳妥一些;之后如果查询性能要求提上来了,可以考虑扩充成三个副本,三副本下读的性能以及并发能力会比两副本更强,因为最终的需求还是满足在线的实时业务,而不是数仓型业务。所以此时双副本和三副本的体验差别不大。
零跑+TDengine的未来展望
早在2018年我就开始关注TDengine了,到2021年它已经发展了三年时间,相对来说也变得更加成熟和稳定了,也因此我们选择了它,而它也真的在帮助我们节省成本、提高速度。
当然如果我们选择市面上其他的数据库产品的话,可能也能胜任,但是却很难达到这样一种性能和成本的最优化。 尤其我们做的是汽车这样一种产品,数据量之大难以想象,如果没有一款能够实现高效存储的数据库,服务器成本会非常的高。这从运行节点的数量上就可窥一二,如果使用HBase,估计需要建立十多个节点,而搭载TDengine的情况下三个节点就能搞定,节点少了运维起来自然也会变得更加轻松一些。
目前我们的数据会在TDengine上存半年,另外每天都会同步到数仓进行为时两年的存储。大部分涉及到APP、云平台的业务,像车速、温度、充电使用情况、电池健康度等信号值现在都是存储在TDengine上。此前使用MongoDB进行业务处理时,需要先将数据存到MongoDB文档中,稍显复杂,现在使用TDengine可以直接进行提取展示。对比来看,TDengine在达到我们预期的前提下,在使用上也更加方便。
在未来的规划中,我们希望能够引入TDengine的使用特性到更多的业务中去,比如说热更新、温度曲线、测速曲线、电极转速等,用更多新的特性减少客户端CPU的消耗,也期待TDengine有更多更好的功能加入。











