作为一个非常有意思的初等面经题,这个问题只要稍微有学那么一丢丢基础,应该都不至于答不上来,但出于开题的目的,我还是简简单单说一下最为常用的除余法
比如我们又一个数字n,想要转为m进制的数
只需要用n不断地去整除m直到整除结果是0,最后把所有结果的余数从下到上连起来,就可以了,比如10进制的15转换成2进制
- 15/2=7....1
- 7/2=3.....1
- 3/2=1.....1
- 1/2=0.....1

所以15的二进制就是1111。代码写起来也非常简单
void
toBinary
(
int
n
)
{
if
(
n
>
1
)
{
toBinary
(
n
/
2
);
}
printf
(
"%d"
,
n
%
2
);
}
但上面这个显然不够怎么「有意思」
如果我们想让这个题目可玩性变高点,我们可以假设n是一个非常大的数字,这种进制转换就可能从一个初等面经题过渡到中等面经题。昨天在Bi站上刚好刷到了这个问题

例如,题目中值为2的1919810次方,这个问题在计算上并不复杂,在二进制中只需要对1向左移位1919810次就可以了,仅仅只是一个数据的表示问题。
而如何把二进制值变为一个超长的十进制,则会复杂的多。但我们还是有一些手段去优化计算,例如我们想要计算2的32次方,我们完全可以用
2^{32}=2^{16}*2^{16}
然后
2^{16}=2^{8}*2^{8}
这样原本32次的乘法只需要5次来完成,也就是说如果不考虑乘法复杂度,我们把原本需要32次的乘法变成了5次。
现在的问题是,按照这个思路如果一个数字很大,两个十进制大数相乘我们如何实现呢,我们先举个简单点的例子,比如
114*514=?
显然的,我们可以使用小学就会的竖式计算,比如:
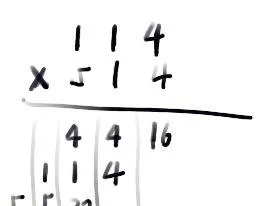
如果你按照这种思路计算,那么,完成2的1919810次方大概就和开头的速度差不多, 大约需要50秒的时间。
那么,还能不能够快一点。
如果我们观察上述的计算,我们会发现这不就是离散信号[1,1,4]和[5,1,4]卷积操作么。这个时候,课上老师一句重复了无数遍的话又响了起来
"信号时域的卷积等于频域的乘积"
你想啊,卷积好算还是乘积好算,当然是乘积好算,要是我们把两个数看作两个不同的离散信号序列,变换到频域后乘起来,然后再变换回时域,之后不就只要算进位运算了么。
那怎么把时域和频域间互相转换呢,显然的,我们首先想到了傅里叶变换,快速傅里叶变换通过蝶形运算可以降低时间复杂度又称为快速傅里叶变换,所以,两个大数相乘我们可以按照下面的步骤来:
所以你看,能够简化运算的本质上是快速傅里叶变换的蝶形交叉算法配合复频域的复数运算性质在起作用,恰好和傅里叶变换撞到了一块儿,甚至可以说还有其它具有类似算法性质的非傅里叶时频变换也可以用来做简化运算操作。
那么,原本复杂度为 O(n^2) 的大数乘法运算,通过快速傅里叶变换就变成了 O(nlogn) ,如果你完成这个运算,大概需要0.5秒-1秒左右的时间,快了50-100倍
实际上上面的多项式优化,在需要大数运算的数学库中是相当普遍的做法,如果你是acm,oj党,应该是多多少少有学过
但是,到这一步仍然只是"有点意思",如果在面试中,仍然达不到震惊面试官一下午的程度。
还能不能够再快一点?
让我们回到除余法,现在,让我们来看看二进制除法

如果你动手试一试,你会发现,在竖式计算中,我们求得十进制其中一位:
本质上不就是除数和被除数之间的减卷积操作么,被除数就是其中的卷积核,卷积的结果,再用相同的卷积核再次进行卷积。
这个时候,我们就把一个简单的二进制转换十进制问题,成功过度到计算机组成原理的问题,但是比较遗憾的是CPU体系天生就不适合处理这种卷积操作。
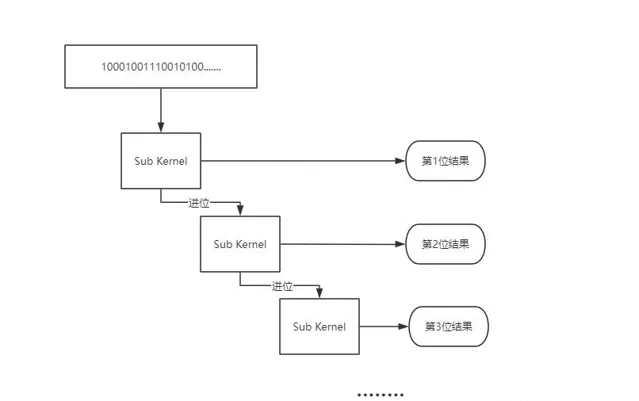
所以,我们得考虑verilog语言来编写这个卷积核了,观察下面的硬件处理架构,及Sub Kernel的verilog代码
`timescale
1
ns
/
1
ps
module
b2d_cell
(
input
wire
i_wire_clock
,
input
wire
i_wire_resetn
,
input
wire
i_wire_data
,
output
wire
o_wire_data
,
output
wire
[
3
:
0
]
o_wire_dec
);
reg
[
3
:
0
]
reg_data
;
assign
o_wire_data
=
reg_data
>
4
'd4
;
assign
o_wire_dec
=
reg_data
;
always
@(
posedge
i_wire_clock
or
negedge
i_wire_resetn
)
begin
if
(
!
i_wire_resetn
)
reg_data
<=
4
'b0000
;
else
begin
if
(
reg_data
>=
4
'd5
)
reg_data
<=
((
reg_data
<<
1
)
|
i_wire_data
)
-
4
'd10
;
else
begin
reg_data
<=
(
reg_data
<<
1
)
|
i_wire_data
;
end
end
end
endmodule
每一个Sub Kernel都有一个4位的寄存器,当寄存器的值大于或等于5时(每个时钟左移位一次),则进行一次减法,并拉高进位寄存器。在顶层模块中,将每个Sub Kernel模块级联在一起
`timescale 1ns / 1ps
module b2d_top #(
parameter dec_length = 8
)
(
input wire i_wire_clock,
input wire i_wire_resetn,
input wire i_wire_data
);
wire[dec_length-1:0] wire_cell_data;
wire[dec_length-1:0] wire_cell_out_data;
wire[3:0] wire_cell_out_dec[dec_length-1:0];
genvar i;
generate
for(i=0; i<dec_length; i=i+1)
begin : RTL
b2d_cell cell_inst(
.i_wire_clock(i_wire_clock),
.i_wire_resetn(i_wire_resetn),
.i_wire_data(wire_cell_data[i]),
.o_wire_data(wire_cell_out_data[i]),
.o_wire_dec(wire_cell_out_dec[i])
);
if(i==0)
begin
assign wire_cell_data[i] = i_wire_data;
end
else
begin
assign wire_cell_data[i] = wire_cell_out_data[i-1];
end
end
endgenerate
endmodule
最后,我们只需要需要转换的数据送到顶层模块中,当我们完成所有数据的传输后,就可以在下一个时钟内,从每一个sub kernel中取得十进制各位的bcd码值了
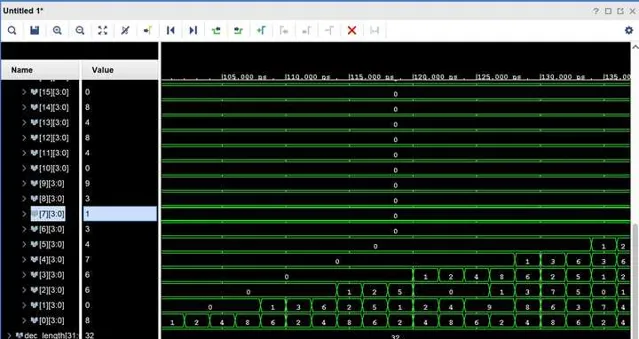
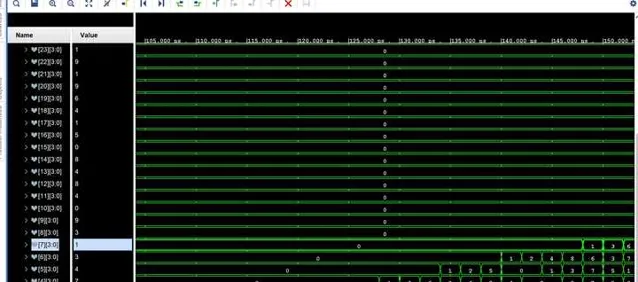
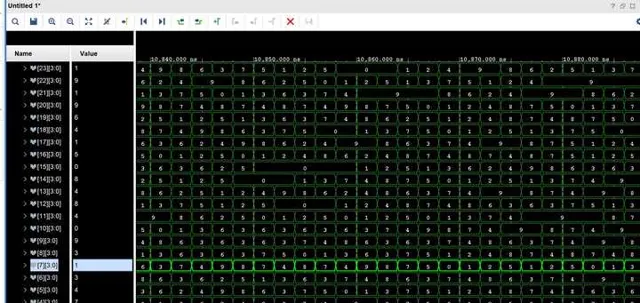
最后,耗时是多少呢?因为每个kernel的时延是确定的,就是1个clock,运算速度几乎等价于数据传输的串行理论带宽,所以如果按照目前中等性能家用CPU的工作主频5Ghz来算的话,2的1919810次方的转换只需要0.00038秒就能够计算完成,足足比快速傅里叶法快了1000倍,比暴力计算快了100000倍。











