论文【Image Captioning:Transforming Objects into Words】NeuralPS 2019-yahoo research传送:
论文代码:
这篇,是想看看Image captioning咋用transformer的。
一句话说论文的主要内容:
Propose a new model named Object Relation Transformer , incorporates information about the spatial relationships between input detected objects through geometric attention .在standard Transformer模型基础上,对已经识别出来的物体设计一个「几何注意力机制」,使得模型能够在对图像编码的过程中考虑到物体在空间上的相对信息。这个模型叫「Object Relation Transformer」。
这里需要指出,原本image captioning任务的pipeline就是Encoder-Decoder:
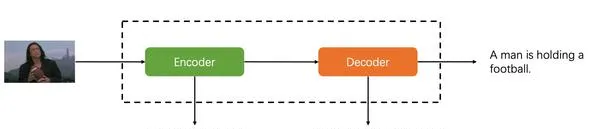
所以,Transformer很自然可以用到这个任务里,并不算一个大的idea创新,只能说Attention确实是all you need。
对于这篇论文来说,创新点主要在于cv方面,即Encoder。更细节的说,在于Encoder中的self-attention机制的改进。咋改的呢?
为了考虑图片中的spatial information,设计了geometric attention。(重点)下面来从论文的整个实现流程来具体解析:
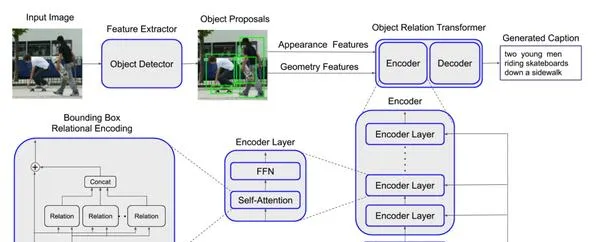
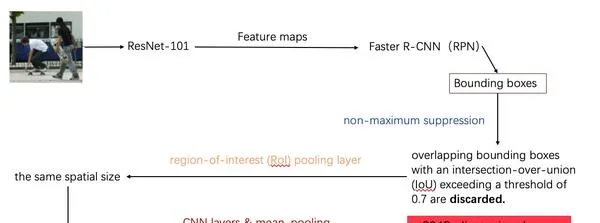
这是对图片提取特征和对象识别的过程:
- 首先使用卷积网络ResNet-101对图片做一个特征提取,得到feature maps。
- 使用Faster R-CNN的RPN对feature maps做一个对象识别,得到bounding boxes。(候选框)
- 对这些得到的bounding boxes使用最大值抑制(non-maximum suppression)对识别出来有IoU(对象识别的一个准确率评价值)阈值超过0.7的重叠bounding boxes剔除。(这一步做的是这个意思:对于图片中的同一个对象,计算机可能识别出很多个bounding boxes,但我们不能所有都留下,只选取识别准确率最大的那一个,其他与这个重叠过高的都删去。)
- 使用一个池化层将所有的bounding boxes变为同样的spatial size。
- 再使用CNN layer和mean pooling再对bounding boxes做进一步的提取,最终得到2048维度的feature vectors用来表示每一个bounding box。输入到transformer的Encoder中。
这里feature vectors实际上是图片每一个bounding box的appearence features(2048维),而我们实际上从object detector里面还获得了geometry features,对于每个bounding box的geometry features是一个4维向量:
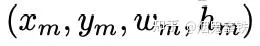
首先将上一步的appearence features输入Encoder的embedding层,将维度从2048降到512,接着跟着一个ReLU函数和dropout层,才输入到Encoder layer。论文里encoder layer共有6层。
走到这里,进入self-attention还是先按照自注意力的规则进行,得到
ΩA 是一个 N × N attention 权重矩阵, ω mn A 表示第m个和第n个token之间的注意力权重。
上一步得到了ΩA ,下面要解决的问题就是:
怎么让模型考虑到图片中物体的空间信息(spatial relationships)?
论文的方式就是:使用geometry features对ΩA进行改进。
- 首先学习一个函数对geometry features进行变换:
2.计算求得geometric attention weight:
3.将geometric attention weight融合到attention机制中:
4.得到多头注意力机制结果:

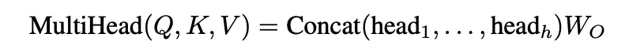
后面进行的步骤就是常规Transformer的步骤了。
参考文献:
1.【Relation-Networks-for-Object-Detection】:https:// github.com/msracver/Rel ation-Networks-for-Object-Detection
2.【Attention is all you need】:https:// proceedings.neurips.cc/ paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf










