它,是迄今為止世界最大的芯片!

眼前的這塊產品,凝聚著數量驚人的技術
如果用老黃的話說,它就是「全世界迄今為止制造出來的最復雜、效能最高的電腦。」
8年內,1.8萬億參數GPT-4的訓練能耗,直接瘋狂降到1/350;而推理能耗則直接降到1/45000
輝達產品的叠代速度,已經徹底無視摩爾定律。

就如網友所言,無所謂,老黃有自己的摩爾定律。
一手硬件,一手CUDA,老黃胸有成竹地穿過「計算通貨膨脹」,放出豪言預測道——在不久的將來,每一個處理密集型套用都將被加速,每一個數據中心也肯定會被加速。
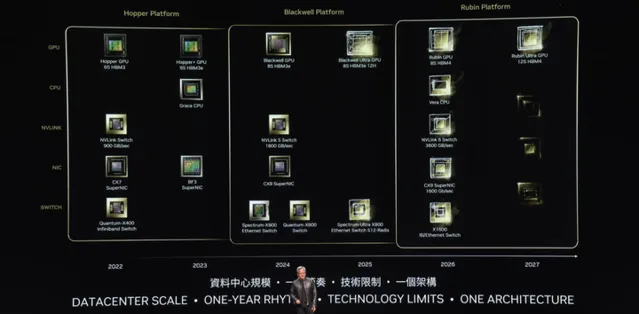
同時公開的Blackwell後三代路線圖:Blackwell Ultra(2025年),Rubin(2026年),Rubin Ultra(2027年)
「買得越多,省得越多」的黃式數學公式,也再次亮相。
全新計算時代開啟
演講開篇,老黃最先放出了一個Omniverse模擬世界中的演示。
他表示,「輝達正處於電腦圖形模擬和人工智能的交叉點上。這是我們的『靈魂』」。

這一切都是物理世界中的模擬,它的實作,得益於兩項基本的技術——加速計算和人工智能,將重塑電腦產業。
到目前為止,電腦行業已有60多年的歷史,而現在,一個全新的計算時代已然開始。
1964年,IBM的System 360首次引入了CPU,通用計算透過作業系統將硬件和軟件分離。架構相容性、回溯相容性等等,所有我們今天所了解的技術,都是從這個時間點而來。
直到1995年,PC革命開啟讓計算走進千家萬戶,更加民主化。2007年,iPhone推出直接把「電腦」裝進了口袋,並實作了雲端連結。
可以看出,過去60年裏,我們見證了2-3個推動計算行業轉變的重要技術節點。

加速計算:一手GPU,一手CUDA
而如今,我們將再一次見證歷史。老黃表示,「有兩個最基礎的事情正發生」。
首先是處理器,效能擴充套件已經大大放緩,而我們所需的計算量、需要處理的數據都在呈指數級增長。
按老黃的話來說,我們正經歷著「計算通貨膨脹」。
過去的20年裏,輝達一直在研究加速計算。比如,CUDA的出現加速了CPU負載。事實上,專用的GPU效果會更好。
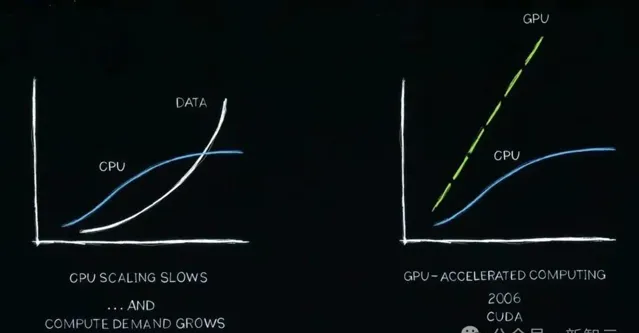
當我們執行一個應用程式,不希望是一個執行100秒,甚至是100個小時的APP。
因此,輝達首創了異構計算,讓CPU和GPU並列執行,將過去的100個時間單位,加速到僅需要1個時間單位。
可見,它已經實作了100倍速率提升,而功耗僅增加的3倍,成本僅為原來的1.5倍。

輝達同時為價值十億美元的數據中心,配備了5億美元的GPU,讓其變成了「AI工廠」。
有了加速計算,世界上許多公司可以節省數億美元在雲端處理數據。這也印證了老黃的「數學公式」,買得越多,省得越多。
除了GPU,輝達還做了業界難以企及的事,那就是重寫軟件,以加速硬件的執行。
如下圖所示,從深度學習cuDNN、物理Modulus、通訊Aerial RAN、基因序列Parabricks,到QC模擬cuQUANTUM、數據處理cuDF等領域,都有專用的CUDA軟件。

也就是說,沒有CUDA,就等同於電腦圖形處理沒有OpenGL,數據處理沒有SQL。
而現在,采用CUDA的生態遍布世界各地。就在上周,谷歌宣布將cuDF加入谷歌雲中,並加速世界上受歡迎的數據科學庫Pandas。
而現在,只需要點選一下,就可以在CoLab中使用Pandas。就看這數據處理速度,簡直快到令人難以置信。
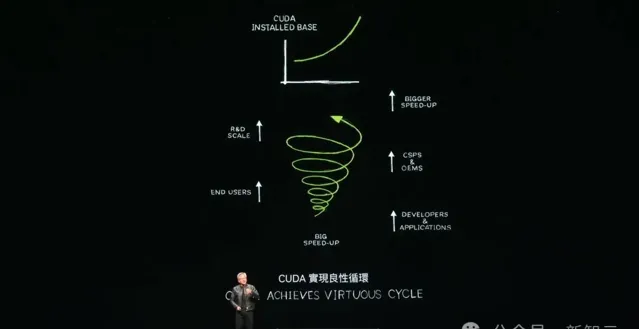
老黃表示,要推行一個全新的平台是「蛋和雞」的困境,開發者和使用者,缺一不可。
但是經過20年的發展,CUDA已經打破了這個困境,透過全球500萬開發者和無數領域的使用者實作了良性迴圈。
有越多人安裝CUDA,執行的計算量越大,他們就越能據此改進效能,叠代出更高效、更節能的CUDA。
「AI工廠」全棧重塑
2012年,神經網絡AlexNet的誕生,將輝達第一次與AI聯系起來。我們都知道,AI教父Hinton和高徒當時在2個輝達GPU上完成AlexNet的訓練。
深度學習就此開啟,並以超乎想像的速度,擴充套件幾十年前發明的演算法。

但由於,神經網絡架構不斷scaling,對數據、計算量「胃口」愈加龐大,這就不得不需要輝達重新發明一切。
2012年之後,輝達改變了Tensor Core,並行明了NvLink,還有TensorRT、Triton推理伺服器等等,以及DGX超算。
當時,輝達的做法沒有人理解,更沒人願意為之買單。
由此,2016年,老黃親自將輝達首個DGX超算送給了位於舊金山的一家「小公司」OpenAI。
從那之後,輝達在不斷擴充套件,從一台超算、到一個超大型數據中心。
直到,2017年Transformer架構誕生,需要更大的數據訓練LLM,以辨識和學習一段時間內連續發生的模式。
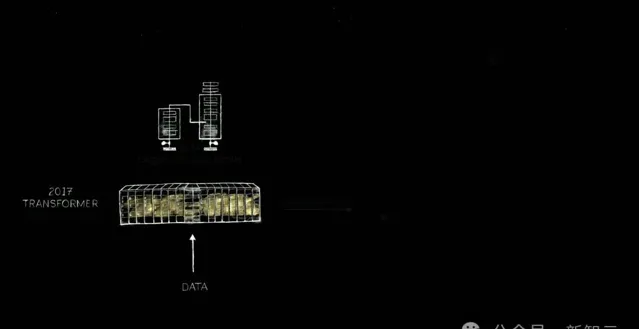
之後,輝達建造了更大的超算。2022年11月,在輝達數萬個GPU上完成訓練的ChatGPT橫空出世,能夠像人類一樣互動。
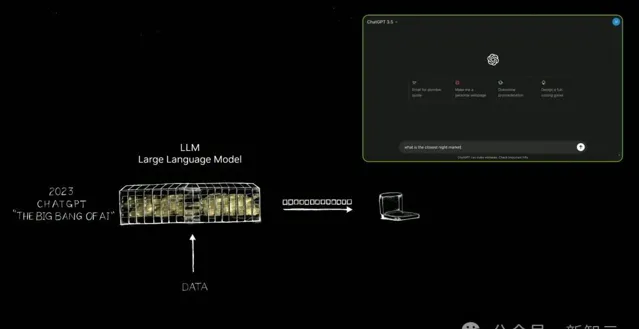
這是世界第一次看到了生成式AI。它會一次輸出一個token,可以是影像、語音、文字、影片,甚至是天氣token,全部都是關於生成。
老黃表示,「我們可以學習的一切,現在都可以生成。我們現在已經進入了一個全新的生成式AI時代」。
當初,那個作為超算出現的電腦,已經變成了數據中心。它可以輸出token,搖身一變成為了「AI工廠」。
而這個「AI工廠」,正在創造和生產巨大價值的東西。
19世紀90年代末,尼古拉·特斯拉發明了AC Generator,而現在,輝達正創造可以輸出token的AI Generator。
輝達給世界帶來的是,加速計算正引領新一輪產業革命。
人類首次實作了,僅靠3萬億美元的IT產業,創造出能夠直接服務於100萬億美元產業的一切東西。

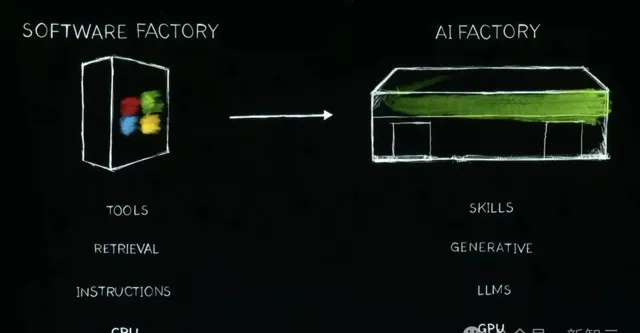
傳統的軟件工廠,到如今AI工廠的轉變,實作了CPU到GPU,檢索到生成,指令到大模型,工具到技能的升級。
可見,生成式AI推動了全棧的重塑。
從Blackwell GPU到超級「AI工廠」
接下來就讓我們看看,輝達是如何將一顆顆地表最強的Blackwell芯片,變成一座座超級「AI工廠」的。



註意看,下面這塊是搭載了Blackwell GPU的量產級主機板。
老黃手指的這裏是Grace CPU。

而在這裏,我們可以清晰地看到,兩個連在一起的Blackwell芯片。

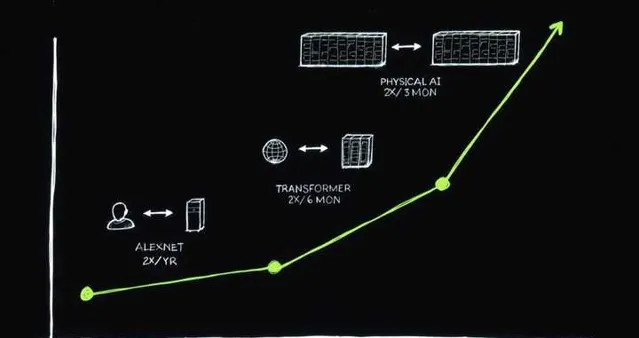
在8年裏,每一代輝達芯片的Flops,都增長了1000倍。
與此同時,摩爾定律在這8年裏,卻似乎逐漸失效了。
即使和摩爾定律最好的時刻相比,Blackwell算力的提升也是驚人的。
這將直接導致的結果,就是成本的顯著下降。
比如,訓練一個1.8萬億參數、8萬億token的GPT-4所用的能耗,直接降至1/350!
Pascal需要消耗的,是1000吉瓦時,這就意味著,它需要一個1000吉瓦的數據中心。(1吉瓦=1000兆瓦)
而且如果這樣的數據中心真的存在的話,訓練也GPT-4也需要整整一個月的時間。
而100兆瓦的數據中心,大概需要一年。
這也就是為什麽,ChatGPT這樣的LLM, 在八年前是根本不可能存在的。
如今有了Blackwell,過去的1000吉瓦時直接可以降到3吉瓦時。
可以說,Blackwell就是為了推理,為了生成token而生的。它直接將每token的能量降低了45000倍。
在以前,用Pascal產生1個token的消耗,相當於兩個200瓦的燈泡執行2天。讓GPT-4生成一個單詞,大概需要3個token。這根本不可能讓我們得到如今和GPT-4聊天的體驗。
而現在,我們每個token可以只使用0.4焦耳,用很少的能量,就能產生驚人的token。

它誕生的背景,正是運算模型規模的指數級增長。
每一次指數級增長,都進入一種嶄新的階段。
當我們從DGX擴充套件到大型AI超算,Transformer可以在大規模數據集上訓練。
而下一代AI,則需要理解物理世界。然而如今大多數AI並不理解物理規律。其中一種解決辦法,是讓AI學習影片資料,另一種,則是合成數據。
第三種,則是讓電腦互相學習!本質上就和AlphaGo的原理一樣。
巨量的計算需求湧來,如何解決?目前的辦法就是——我們需要更大的GPU。
而Blackwell,正是為此而生。
Blackwell中,有幾項重要的技術創新。
第一項,就是芯片的尺寸。
輝達將兩塊目前能造出來的最大尺寸的芯片,用一條10TB/s的鏈路連結起來;然後再把它們放到同一個計算節點上,和一塊Grace CPU相連。
在訓練時,它被用於快速檢查點;而在推理和生成的場景,它可以用於儲存上下文記憶體。
而且,這種第二代GPU還有高度的安全性,我們在使用時完全可以要求伺服器保護AI不受偷竊或篡改。
並且,Blackwell中采用的是第5代NVLink。
而且,它是第一代可信賴、可使用的引擎,
透過該系統,我們可以測試每一個晶體管、觸發器、片上記憶體和片外記憶體,因此我們可以當場確定某個芯片是否出現故障。
基於此,輝達將擁有十萬個GPU超算的故障間隔時間,縮短到了以分鐘為單位。
因此,如果我們不發明技術來提高超算的可靠性,那麽它就不可能長期執行,也不可能訓練出可以執行數月的模型。
如果提高可靠性,就會提高模型正常的執行時間,而後者顯然會直接影響成本。
最後,老黃表示,解壓縮引擎的數據處理,也是輝達必須做的最重要的事之一。
透過增加資料壓縮引擎、解壓縮引擎,就能以20倍的速度從儲存中提取數據,比現在的速度要快得多。

超強風冷DGX & 全新液冷MGX
Blackwell是一個重大的躍進,但對老黃來說,這還不夠大。
輝達不僅要做芯片,還要制造搭載最先進芯片的伺服器。擁有Blackwell的DGX超算,在各方面都實作了能力躍升。
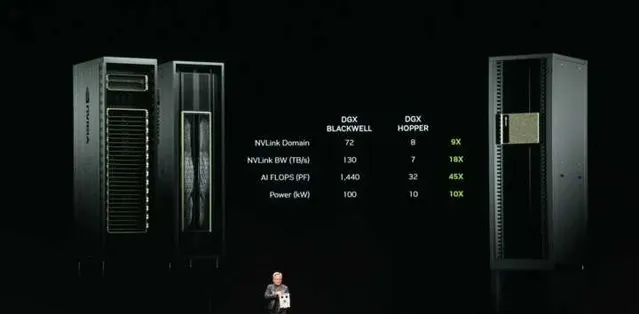
整合了Blackwell芯片的最新DGX,能耗僅比上一代Hopper提升了10倍,但FLOPS量級卻提升了45倍。
下面這個風冷的DGX Blackwell,裏面有8個GPU。

而對應散熱器的尺寸也很驚人,達到了15kW,並且是完全的風冷。
如果你喜歡部署液冷系統呢?輝達也有新型號MGX。
單個MGX同時整合72個Blackwell GPU,且有最新的第五代NVLink每秒130TB的傳輸速度。
介紹完芯片,老黃特意提到了輝達研發的NVLink技術,這也是輝達的主機板可以越做越大的重要原因。
由於LLM參數越來越多、越來越消耗記憶體,想要把模型塞進單個GPU已經幾乎是不可能的事情,必需搭建集群。其中,GPU通訊技術的重要性不亞於計算能力。
輝達的NVLink,是世界上最先進的GPU互連技術,數據傳輸速率可以堪稱瘋狂!
因為如今的DGX擁有72個GPU,而上一代只有8個,讓GPU數直接增加了9倍。而頻寬量,則直接增加了18倍,AI FLops增加了45倍,但功率僅僅增加了10倍,也即100千瓦。
下面這個NVLink芯片,也堪稱是奇跡。
人們之所以意識到它的重要性,是因為它將所有這些不同的GPU連線在一起,從而能夠讓十萬億參數的LLM執行起來。
500億個晶體管,74個埠,每個埠400GB,7.2TB每秒的橫截面頻寬,這本身就是個奇跡。
而更重要的是,NVLink內部還具有數學功能,可以實作歸約。對於芯片上的深度學習,這尤其重要。

有趣的是,NVLink技術,大大拓寬了我們對於GPU的想象。
比如在傳統的概念中,GPU應該長成這樣。

但有了NVLink,GPU也可以變成這麽大。

支撐著72個GPU的骨架,就是NVLink的5000根電纜,能夠在傳輸方面節省20kw的功耗用於芯片計算。

老黃拿在手裏的,是一個NVLink的主幹,用老黃的原話說,它是一個「電氣機械奇跡」
NVLink做到的僅僅是將不同GPU芯片連線在一起,於是老黃又說了一句「這還不夠宏大」。
要連線超算中心內不同的主機,最先進的技術是「無限頻寬」(InfiniBand)。
但很多數據中心的基礎設施和生態,都是基於曾經使用的乙太網路構建的,推倒重來的成本過高。
因此,為了幫助更多的數據中心順利邁進AI時代,輝達研發了一系列與AI超算適配的以太交換機。
網絡級RDMA、阻塞控制、適應力路由、雜訊隔離,輝達利用自己在這四項技術上的頂尖地位,將乙太網路改造成了適合GPU之間點對點通訊的網絡。
由此也意味著,數百萬GPU數據中心的時代,即將到來。

全球2800萬開發者,即時部署LLM
在輝達的AI工廠中,執行著可以加速計算推理的新型軟件——NIM。

老黃表示,「我們建立的是容器裏的AI」。
這個容器裏有大量的軟件,其中包括用於推理服務的Triton推理伺服器、最佳化的AI模型、雲原生堆疊等等。

現場,老黃再一次展示了全能AI模型——可以實作全模態互通。有了NIM,這一切都不是問題。
它可以提供一種簡單、標準化的方式,將生成式AI添加到應用程式中,大大提高開發者的生產力。

現在,全球2800萬開發者都可以下載NIM到自己的數據中心,托管使用。
未來,不再耗費數周的時間,開發者們可以在幾分鐘內,輕松構建生成式AI應用程式。
與此同時,NIM還支持Meta Llama 3-8B,可以在加速基礎設施上生成多達3倍的token。
這樣一來,企業可以使用相同的計算資源,生成更多的響應。
而基於NIM打造的各類套用,也將迸發湧現,包括數碼人、智能體、數碼孿生等等。
老黃表示,「NVIDIA NIM整合到各個平台中,開發人員可以隨處存取,隨處執行 —— 正在幫助技術行業使生成式 AI 觸手可及」。
智能體組隊,萬億美元市場
而智能體,是未來最重要的套用。
老黃稱,幾乎每個行業都需要客服智能體,有著萬億美元的市場前景。
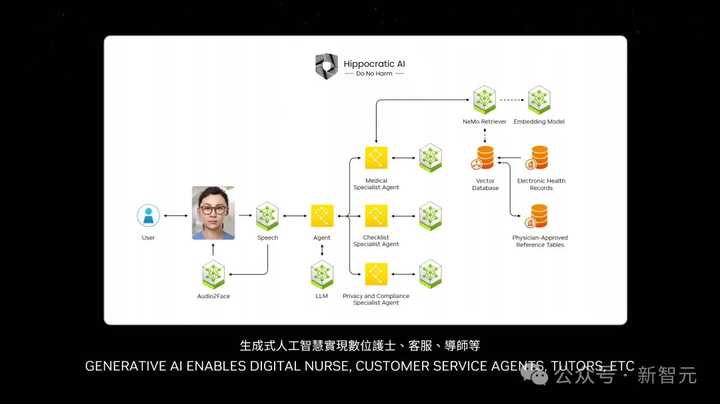
可以看到,在NIM容器之上,大多數智能體負責推理,去弄清任務並將其分解成多個子任務。還有一些,它們負責檢索資訊、搜尋,甚至是使用工具等。
所有智能體,組成了一個team。
未來,每家公司都將有大量的NIM智能體,透過連線起來組成一個團隊,完成不可能的任務。
GPT-4o軀殼,老黃做出來了
在人機互動這方面,老黃和Sam Altman可以說是想到一起了。
他表示,雖然可以使用文字或語音形式的prompt給AI下達指令,但很多套用中,我們還是需要更自然的、更類人的互動方式。
這指向了老黃的一個願景——數碼人。相比現在的LLM,它們可以更吸引人,更有同理心。
GPT-4o雖是實作了無法比擬的類人互動,但缺少的是一個「軀體」。
而這次,老黃都幫OpenAI想好了。

未來,品牌大使也不一定是「真人」,AI完全可以勝任。

從客戶服務,到廣告、遊戲等各行各業,數碼人帶來的可能將是無限的。
連線Gen AI的CG技術,還可以即時渲染出逼真的人類面部。
低延遲的數碼人處理,遍及全球超過100個地區。

這是由輝達ACE提供的魔力,能夠為建立栩栩如生的數碼人,提供相應的AI工具。
現在,輝達計劃在1億台RTX AI個人電腦和筆記電腦上,部署ACE PC NIM微服務。

這其中包括輝達首個小語言模型——Nemotron-3 4.5B,專為在器材上執行而設計,具備與雲端LLM相似的精度和準確性。
此外,ACE數碼人類AI新套件還包括基於音軌生成身體手勢——NVIDIA Audio2Gesture,即將推出。
老黃表示,「數碼人類將徹底改變各個行業,ACE提供的多模態LLM和神經圖形學的突破,使我們更接近意圖驅動計算的未來,與電腦的互動將如同與人類的互動一樣自然」。
預告下一代芯片Rubin
Hopper和Blackwell系列的推出,標誌著輝達逐漸搭建起完整的AI超算技術棧,包括CPU、GPU芯片,NVLink的GPU通訊技術,以及NIC和交換機組成的伺服器網絡。
如果你願意的話,可以讓整個數據中心都使用輝達的技術。
這足夠大、足夠全棧了吧。但是老黃表示,我們的叠代速度還要加快,才能跟上GenAI的更新速度。
輝達在不久前就曾放出訊息,即將把GPU的叠代速度從原來的兩年一次調整為一年一次,要用最快的速度推進所有技術的邊界。
今天的演講中,老黃再次實錘官宣GPU年更。但是他又緊跟著疊了個甲,說自己可能會後悔。
無論如何,我們現在知道了,輝達不久後就會推出Blackwell Ultra,以及明年的下一代的Rubin系列。

從孿生地球,到具身AI機器人
除了芯片和超算伺服器,老黃還釋出了一個所有人都沒有想到的專案——數碼孿生地球「Earth-2」。
這也許是世界範圍內最有雄心的專案(甚至沒有之一)。
而且根據老黃的口吻推測,Earth-2已經推進了數年,今年取得的重大突破才讓他覺得,是時候亮出來了。

為什麽要為建造整個地球的數碼孿生?是要像小紮的元宇宙那樣,把社交和互動都搬到線上平台嗎?
不,老黃的願景更宏偉一些。
他希望在Earth-2的模擬,可以預測整個星球的未來,從而幫我們更好地應對氣候變遷和各種極端天氣,比如可以預測台風的登陸點。

Earth-2結合了生成式AI模型CorrDiff,基於WRF數值模擬進行訓練,能以12倍更高的解析度生成天氣模型,從25公裏範圍提高到2公裏。
不僅解析度更高,而且相比物理模擬的執行速度提高了1000倍,能源效率提高了3000倍,因此可以在伺服器上持續執行、即時預測。
而且,Earth-2的下一步還要將預測精度從2公裏提升到數十米,同時考慮城市內的基礎設施,甚至可以預測到街道上什麽時候會刮來強風。

而且,輝達想數碼孿生的,不止是地球,還有整個物理世界。
對於這個狂飆突進的AI時代,老黃大膽預測了下一波浪潮——物理AI,或者說是具身AI。

它們不僅需要有超高的認知能力,可以理解人類、理解物理世界,還要有極致的行動力,完成各種現實任務。
想象一下這個賽博龐克的未來:一群機器人在一起,像人類一樣交流、協作,在工廠裏創造出更多的機器人。
而且,不僅僅是機器人。一切能移動的物體都會是自主的!

在多模態AI的驅動下,它們可以學習、感知世界,理解人類指令,並前進演化出計劃、導航以及動作技能,完成各種復雜任務。
那要怎樣訓練這些機器人呢?如果讓他們在現實世界橫沖直撞,代價要比訓練LLM大得多。
這時,數碼孿生世界就大有用武之地了。

正像LLM可以透過RLHF進行價值觀對齊一樣,機器人也可以在遵循物理規律的數碼孿生世界中不斷試錯、學習,模仿人類行為,最終達到通用智能。
Nvidia的Omniverse可以作為構建數碼孿生的平台,整合Gen AI模型、物理模擬以及動態即時的渲染技術,成為「機器人健身房」。

誌在做全棧的輝達也不僅僅滿足於作業系統。他們還會提供用於訓練模型的超算,以及用於執行模型的Jetson Thor和Orin。

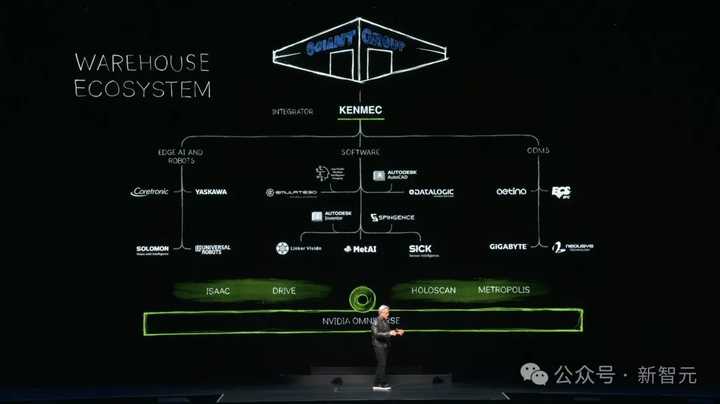
為了適應不同套用場景下的機器人系統,輝達的Omniverse將逐步擴充套件為Warehouse生態系。
這個生態將無所不包,從搭配應用程式的SDK和API,到執行邊緣AI計算的介面,再到最底層的可客製芯片。
在全棧產品方面,輝達就是想要做自己的「全家桶」,讓別人無路可走。
為了讓這個AI 機器人時代看起來更真實,演示的最後,9個和老黃有同樣身高的機器人一同登場。

正如老黃所說的,「這不是未來,這一切都正在發生」。











