首先說一下結論:RL 及其相關演算法 是 大(語言)模型真正智能的主流賽道。
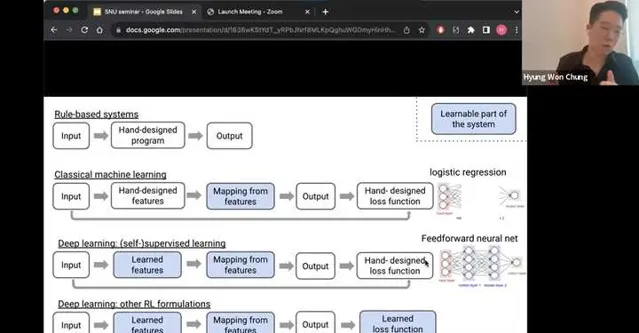
我粘一個圖來闡述一下我的李姐,圖片來自於Hyung Won Chung (OpenAI)的一個talk,在這個talk的最末尾給出了這麽一張圖闡述了他對於智能系統的展望。之所以貼上這個圖,是因為我自己也做了一個類似的,但是表達的沒有他的清晰。
有興趣看全集的可以參考這個影片:
RL被引入到自監督學習(SSL)之後,除了增加了就業崗位之外,其實在loss function這一塊還是給了更強的通用智能一個很不錯的方向的。我們這些年,從深度學習開始爆發開始,智能的演進差不多也經歷了這些過程,所謂機器學習真正學習到的是這些:
1. 傳統機器學習:收集輸入輸出,手動設計feature,手動設計loss function,最後讓機器學習的是從feature到output的一個mapping 。傳統的機器學習,包括了大量feature engineering的內容,同時feature的選擇依賴人工經驗。
2. 深度(自監督)學習:到了這個階段,手動的feature設計也被替代了,tokenizer和learnable的embedding成為了大語言模型的標配,模型的大小在數據和AI infra的加持下迅速scale up。
3. 深度(強化)學習:以ChatGPT,Claude,Llama2,Qwen等為代表的RLHF及RLAIF派,把深度自監督學習裏的手工loss function也變成了可學習的部份。透過reward model代理表征人類喜好等方式,將學習目標從增強下一個token的likelihood,轉變成提升模型有用性&無害性等目標。
如果您贊同這個技術趨勢,那麽RL確實能夠朝著通用智能的方向前進;像我一樣的工程師也一定能在艱難求索AI落地的過程中,從行業中分到一杯羹。

這麽說當然有為了給市場打氣,然後哄擡RLer身價的嫌疑,但是在這個話題下有一些特別fundamental的事情想要和各位討論,這些事情也是我自己最近一個階段的職業興趣所在,歡迎各位點評。
Maximum likelihood is too strong of an inductive biasChatGPT已經出現了一年了,演算法工程師的日子不是變好了,而是變壞了,因為本質上演算法工程師善於體現價值的領域實際上是圖中白色的部份。在大模型時代,留給演算法工程師的空間其實主要就是在Input,Output階段了,不管是在做預訓練還是在做有監督微調,大量的時間和工作都貢獻給了數據。同時籠罩著的烏雲是,采用next token maximum likelihood的方式在打造行業模型,本身就存在很強的bias,非常難以scale到很大的規模,同時難以transfer到不同的領域。如果僅僅堅持在自監督的範式裏,整個大模型產業會迅速內卷並且塌陷到原始的AI小作坊時代。
Learning the objective function is a different paradigm and there is a lot of room for improvementRLHF實際上也沒有直接解決alignment裏的所有問題,首先人類的偏好就是非常noisy的訊號,作為一個代理而言很難以表征「智能」這個終極的目標。其次RL的效率問題,我從2021年開始覺得是一個比較大的問題:
從事後來看,Deepmind和OpenAI效率和規模的進步著實實作了RL的「大力出奇跡」,其余業界基本都是follower。當前的LLM中的RLHF實際上和2021年的主流RL框架的MFU差不多,因為整個系統牽涉到了多個模型的訓練推理等流轉的過程。原理上也是暴力的trail & error方法,不斷增加正向reward的probability,降低負向reward的probability。
If something is so principled, we should keep at it until it works基於下一個token的預測到底為什麽能創造智能,他的原理是什麽,上限在哪裏,為什麽在語言的層面可以做到這件事,到底能不能夠透過自博弈的方式提升語言模型的智能的上限。這些問題都太過於重要,以至於現在的很多工作都不敢挑戰這些宏達的命題。通用智能從一個學術界大家都避之不及的話題,到了今天的工業界傾註海量資源,最終作為RLer和AI從業者keep at it until it works也許是一個最好的選擇。
最後我再多嘴兩句最近提的特別火的 Q* , Q(s,a) 表示的是在給定的狀態 s 下,如果采取行動 a 能夠獲取到的 reward期望。如果一個問題在給定的狀態 s 下,可以準確且快速地得到其action space中的行動 a 的獎勵,那麽就可以透過Q learning的方式從當前步(step)持續最佳化到未來的所有步,以獲得一個最優的policy。那麽就有兩個問題,一是那些領域的reward值比較好弄到,二是Greg所說的next-step到底表示的是什麽呢?












