作為RL研究從業者,我認為RL的潛力還遠遠未被開發。一個真正的AI Agent應該有應對真實世界方方面面各種挑戰的能力,特別是得要有planning和reasoning的能力,而不只是有對於下一個語言token預測的能力。
現有RL能力的結合和落地
先說一下套用現有的RL理論和技術,在實際生活中能做到什麽。我們最近其實一直著力於開發能夠幫助AI從業人員在現有RL理論和技術下開發真正擁有在實際環境下有用的RL Agent,並且最近開源了Pearl,我的團隊最新開發的開源RL AI Agent框架(首日上線就拿到了540星,目前已經近1400星,感覺大家對RL還是有熱情的)。先上Github連結(其中有包括網站和ArXiv論文):
我們認為實際落地場景中有用的RL Agent,不能局限於只有最大化cumulative reward的能力,而需要覆蓋以下的多個方向並且能夠在同一個Agent中加入任意以下能力的子集:
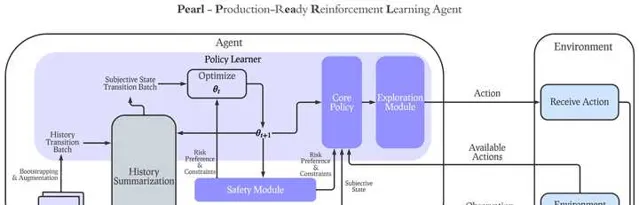
1. Dynamic Action Space (動態變化的行動空間):在真實環境中,大多數情況下每一步決策可采取的行動都是動態的,而不會在同一個問題中永遠有一樣的行動空間。比如,在推薦系統中,不可能在每一步給使用者的可推薦內容集都是一樣的。因此,在Pearl的設計中,我們著重支持了每一步的動態行動空間,並特殊設計了replay buffer,value-based演算法和actor-critic演算法來支持動態行動空間下的policy learning。
2. Offline RL transition to Online RL(線下強化學習向線上強化學習的轉變):多數的現有演算法只能顧及Offline和Online RL其中之一,而不能幫助Agent在完成Offline RL Pre-training之後做Online RL來和環境互動,從而真正學到optimal policy。Pearl的offline RL設計可以讓我們的Agent在完成offline RL後用一個參數就完成到online RL到轉變,從而幫助Agent從offline轉至online。
3. Intelligent Exploration(智能探索):很多RL Agent設計的時候都用了最最常規的epsilon-greedy或者softmax的exploration,這種情況下,RL Agent並沒有針對性地去收集他自身不確定性最高的state action的數據。這導致了很多線上收集的數據是浪費了的。在智能探索的能力下,Agent能夠最大化在每一次線上互動收集到的數據中能學到的資訊,從而提升sample-efficiency。在智能探索的能力下,我們設計了同時對neural contextual bandit和RL問題的支持。
4. Safe Decision Making (安全決策):安全一般分為兩類,一類是限制,另一類是風險。限制性的安全決策指的是在Agent的決策全過程中,總的限制性指標不能超過某個閾值。一般情況下會用CMDP相關的理論方向來解決,在Pearl的設計中,我們引進了RCPO演算法將其和任意actor-critic演算法結合,便可以保證環境設定中的限制性指標不會超過閾值。而風險性指標指的是針對在一個policy之下可能收到的總的reward的分布,來限制Agent所需要接受的風險。比如,如果需要設計一個相對比較保守的Agent,那就會取總的reward的分布的相對比較低的percentile,而如果設計的是激進的Agent,就可以相反取比較高的percentile。我們將這種風險性的安全決策和分布強化學習結合(QRDQN),來滿足相應的風險安全需求。
5. History Summarization for Partial Observability (針對部份可觀測性的歷史總結):大多數實際套用場景中,Agent的觀測都是部份觀測,而不能知道真正實際產品或者使用者的真實狀態。因此,能夠從長時間的過往觀測和Agent已經采取的行動中,估計真正的state,是對於RL實際套用至關重要的。我們在Pearl的設計中引進了sequence model來完成對過往歷史的總結,並且用巧妙的工程技巧使得任意的history summarization可以和任意policy learning的演算法結合,完成兩個模組的同時學習。
最重要的一點是,在真實的套用場景中,我們希望以上的每一個Agent能力都是模組化的。也就是說,Agent的設計者可以在他們的場景中,結合以上的能力中的任意子集和常規policy learning的演算法(比如value-based或者actor-critic)結合,來完成一個真正能夠切合實際套用場景的RL-based AI Agent。
在我們的RL落地過程中,以上的RL能力以及他們的模組化結合對於最後的成功落地至關重要。
未來的RL展望
再講講對於未來的可能方向。
第一,我自己覺得將RL的planning能力和LLM還有diffusion model的結合,應該是下一個重要的突破口,問題在於action space的設計將會在什麽程度上完成並且如何設計基於這些能力下的RL Agent的目標,會是一個很有意思的事情。
第二,multi-agent會是一個重頭戲,因為當AI Agent慢慢變得普遍化之後,如何完成de-centralized agent training會是非常重要的一環。在之後的真實環境中,隨機的環境變量可能不只是人類,可能還有agent本身帶來的隨機性。
第三,一個最近沒有那麽火的方向,但我還是覺得極其重要的,是Auxiliary Task。一般的真實環境中都會有超過一個目標需要完成,那planning就需要兼顧多個目標,這就是Auxiliary Task在RL中的作用。目前在學術界,這個方向還處於相對早期,有待更多研究的開發。
第四,Hierarchical RL可能是一個突破口。像我上文所說,在真實世界中,行動空間一般都是動態的,並且很多時候是完全沒有重合的。比如一個機器人需要去幫你掃地和幫你做飯,這些事情可能沒有任何的重合的行動空間,但是卻需要統籌安排時間,比如在燉湯的時候去掃地,來完成效率最大化,這種問題都可以用到Hierarchical RL來解,但目前Hierarchical RL理論還沒有那麽成熟。
總結
RL還處於起步階段。雖然很多人質疑RL的有效性,我還是會覺得RL是在我目前看來,帶目的性的人工智能設計中最普適也最有可能成功的。最後附上一個看到的github上給Pearl的一個issue
希望Pearl能夠幫助大家開發能夠符合實際場景需求的RL Agent並且孵化出一個超越Q*的真正智能。











