好問題。時隔一年再來答這個題,也許大家看這個問題會更客觀。
還是先上結論。我認為 AlphaGo理解圍棋,而且AlphaGo比人類對圍棋的理解高一個層次。
這個問題下面, @SIY.Z 的答案對我很有啟發,推薦大家可以看看。
這位答主提到,
你或許還是不能接受AlphaGo這個樣子,我想這是因為,人們下圍棋,一定要先理解「圍棋」什麽東西,下面才可以操作。但是AlphaGo卻是在不知道(或者沒有被提供數據)「圍棋是一種2個人的,而且兩個人面對面做的,對抗的,零和的,棋盤19*19的,棋盤是方的,上面是打格子的,格子也是方的,有黑白兩個子的,黑子先下的,兩個輪流下的,要下在格點而不是格子中間的,有限時要求的,棋子數量足夠的,一個棋子不會占超過一格的,棋子是圓的,兩邊凸起的,中國古代發明的,一種博弈遊戲」中的任何一點的時候,可以戰勝人類。說得好。不過,AlphaGo眼裏其實是有「圍棋」這個概念的。電腦圍棋界有基於中國規則的Tromp-Taylor規則(Tromp-Taylor Rules)。詳細的條文就不在這裏貼了,我簡單轉述一下。Tromp-Taylor規則定義,圍棋是一個在19*19格點上進行,兩個玩家「小黑」、「小白」,輪流分別把棋盤上的某一個格點染成黑色或白色的遊戲。再加上提子和禁迴圈的規則,以及終局判斷,就是完整的Tromp-Taylor規則。請各位想一想,這樣的圍棋,和我們眼中的圍棋,有什麽本質區別嗎?如果不考慮圍棋文化,那麽我可以肯定地說,沒有區別。
既然對於AlphaGo,「圍棋」這個概念本身,和人類理解的「圍棋」這個概念沒有區別,那我們就先聊聊我們人類,特別是職業棋手,是怎麽理解圍棋的。
這裏參照一段我去年寫的文章。
圍棋是世界上最復雜的遊戲之一。所謂「一著不慎,滿盤皆輸」,每一步棋都可能左右全域的結果。一般來說,一手棋的決策分兩步。第一步,「選點」:憑經驗或感覺給出幾個候選的點;第二步,「判斷」:分別對這幾個點做形式判斷,並進行比較。這兩步,說來容易,但要做到笑傲眾生的水平,對於天賦和勤勉的要求,不亞於一個優秀數學家所需要的。
從初學者成長為大師,棋手需要先學會基本的布局理論、掌握基本的死活、對殺常識,然後熟記數百個定式及掌握其主要分支(飛刀)、練習數萬死活題,同時在大量對局中磨練。有些外行據此認為,圍棋只是復雜一點的「體力勞動」。對於這一觀點,下圖古力同學白1這一招抵得上千言萬語。

圖中右上的形狀,在任何一本死活題的書中都不曾出現。實戰白棋這一招的位置,也屬於一般「選點」思路下的盲點。但古力同學在短時間內看到了這一招,一舉扭轉乾坤。
「體力勞動」讓天賦平平者能夠成為業余高手,但山巔最美的風景只屬於天才 。
我們再說「判斷」。判斷很難嗎?在中國象棋或者國際象棋中,形勢判斷對於程式來說並非難事:只需觀察雙方子力的差距就可以大致判斷出形式的好壞。當年戰勝卡斯巴羅夫的「深藍」,其形式判斷演算法大致就是如此,非常簡潔。而圍棋的形勢判斷是個真正的難題。圍棋的勝負由終局時雙方控制地盤的多寡決定。然而棋局進行到一半,雙方的地盤都尚未封閉,怎麽判斷形勢呢?
職業棋手采用的演算法是估算雙方的目數(地盤大小)差距。那如果地盤的邊界沒有完全確定怎麽辦呢?如果有先手官子就判給先手方,如果是雙方後手官子就算一人一半。如果有一些模糊的地方,比如說一塊厚勢折算成幾目呢?這時候就只能憑經驗感覺了。職業棋手之間微妙的水平差異,很多時候也體現在模糊判斷能力上。

對於如圖所示的中盤階段末期的局面,職業棋手一般能在一到兩分鐘內大致判斷出雙方地盤的差距,並據此決定接下來的策略是保守或是激進。這樣的判斷速度和準確度,和「搜尋」能力的訓練一樣,背後也是數千盤對局積累下來的經驗。
——————
小結一下,對於高手來說,除了十幾年日復一日訓練的積累以外,靈感和天賦也是必不可少的。在復雜局面下,棋手的選點需要靈光一現,而模糊判斷的準確性,離不開棋手的天賦。
這聽上去有點像藝術創作。確實,圍棋自古以來與琴、書、畫並稱君子四藝,現在我們仍然這麽提。但是,圍棋終究是一個遊戲。如果你對博弈論有所涉獵,大概會知道,圍棋是一種「完全資訊」博弈。更懂行一點的讀者知道,根據 策梅洛定理 ,像圍棋這樣的二人、完全資訊、無運氣成分、有限回合、且不存在和棋的遊戲,對局的其中一方是有必勝策略的。(這裏有必要解釋一下「有限回合」和「不存在和棋」。圍棋的中國規則中,有「禁迴圈」一條,這就杜絕了棋局無限制進行下去的可能。另外,如果嚴格執行「禁迴圈」規則,三劫迴圈、長生等特殊棋型,相當於打一個普通的劫爭,不必判和棋。現實中將三劫迴圈判和,只是一種權宜之計,相信未來可能會改變。)
那麽,既然必勝策略一定存在,為什麽圍棋手不去研究必勝策略,搞什麽選點、判斷?為什麽圍棋手不能踏踏實實用邏輯推理解決戰鬥,是不是他們在故弄玄虛,或者說裝逼?
當然不是。
因為圍棋太難了。
1950年,「消息理論之父」克勞德·山農在論文「Programming a Computer for Playing Chess」 中給出了國際象棋復雜度的一個下限。山農寫道,一盤象棋一般有40個回合,平均每回合的變化總量大約在10^3這個數量級,那麽國際象棋的變化總數至少是10^120這個數量級。後人把10^120這個數稱作「山農數(Shannon Number)」。山農用此計算說明,利用純暴力搜尋破解國際象棋是不現實的。
如果我們估計一下圍棋的山農數呢?19路圍棋盤上,一盤棋大約是120個回合(240手),平均每回合的變化數總量在10^5以上,這樣算下來,圍棋的變化總數不少於10^600。可觀測宇宙的原子總量10^80,相形之下,真是小巫見大巫。劉慈欣的小說【詩雲】中寫道,就算把宇宙中的每一個原子都做成儲存器,而且技術先進到一個原子能儲存一位元資訊,也只能存下很小一部份的棋局。
誠然,計算,或者說單純的邏輯推理,是圍棋技藝的基礎。不過,當計算量遠遠超出人腦的能力之時,減少計算量的技巧,選點、判斷,就必須出場了。經驗性的選點,讓棋手快速將有限的計算力集中到幾個重要分支上;而準確的判斷,能夠讓棋手在優勢局面下鳴金收兵,避免復雜計算,減小風險;或者在劣勢局面下放棄幻想,奮力一搏。當然,選點、判斷時的模糊性,在邏輯上難免不嚴謹,有一定風險,這就要求棋手權衡利弊,合理分配時間。
-----------------
講了很多人類棋手的事,是時候讓AlphaGo出場了。事實上,擺在AlphaGo面前的最大問題,和人類棋手是一樣的: 圍棋太難了,計算力不夠 。「深藍」戰勝卡斯巴羅夫那一套,對國際象棋還行,套用到圍棋上根本不可能,畢竟圍棋的復雜度遠超國際象棋。想要戰勝人類,只能把有限的計算力用在刀刃上。怎麽辦?AlphaGo團隊的做法是, 像人類棋手一樣,去選點和判斷 。
深度摺積神經網絡,是AlphaGo采用的一項先進技術。我們可以把神經網絡看成一個黑箱。
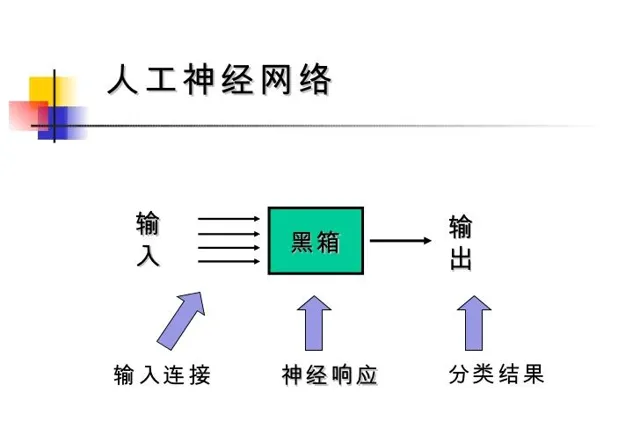
如上圖。給定一個輸入,神經網絡經過一系列處理後輸出結果。具體到AlphaGo的架構,可以用下圖粗略地解釋。
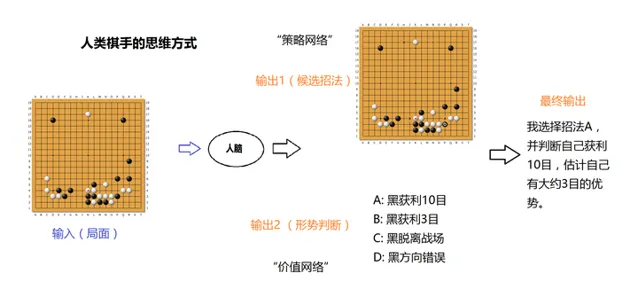
請看上圖。人類棋手的思維方式,是根據輸入的局面,輸出候選招法和形勢判斷,綜合以後給出最終輸出。AlphaGo的大框架與此非常相似。AlphaGo的策略網絡,大致對應人類「選點」的決策;AlphaGo的價值網絡,大致對應人類「判斷」的決策。

在此基礎上,蒙地卡羅搜尋樹演算法將策略網絡和價值網絡串聯起來,形成完整的決策系統。
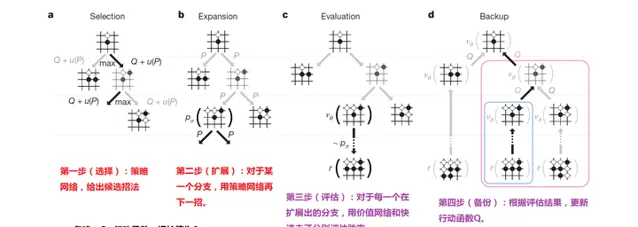
AlphaGo基於蒙地卡羅搜尋樹的單次決策過程,附有我的詮釋。進行此迴圈多次以後,AlphaGo選擇在過程中 重復次數最多 的分支為最終落子點。
以上我對AlphaGo的解讀為了方便大家理解,有不嚴謹之處。關於AlphaGo原理的深度解讀,推薦 @袁行遠 的答案DeepMind 研發的圍棋 AI AlphaGo 是如何下棋的?。輕松一點的解讀,也可以看圍棋 AI(人工智能)的發展歷程是怎麽樣的?,我和 @Haochen Liu 以及 @雲天外 一起做的Live的逐字稿。
前面的內容講到,AlphaGo下棋時決策的方式和人類相似,因此可以說AlphaGo「理解」圍棋。接下來進入我要論證的主題, AlphaGo比人類更懂圍棋 。
AlphaGo以4:1戰勝李世乭,又化名Master在快棋中橫掃職業棋手,實力無疑超過所有人類棋手。然而,還有更恐怖的事情。棋手們在這一年多以來,一直在向AlphaGo學習。在具體招法上,也有了不少心得。 但是,AlphaGo的判斷力是人類永遠沒法學習或者模仿的。 下面這一段,我將人類與AlphaGo的判斷能力做個簡單比較。
——————
人類「數地盤」式的判斷常有失靈之時。除了模糊判斷可能帶來的誤差以外,對於某一塊地盤歸屬的錯判也是經常發生的。李世乭-AlphaGo五番棋第一局中,職業棋手們就在局中集體給我們演示了一次這樣的錯判。
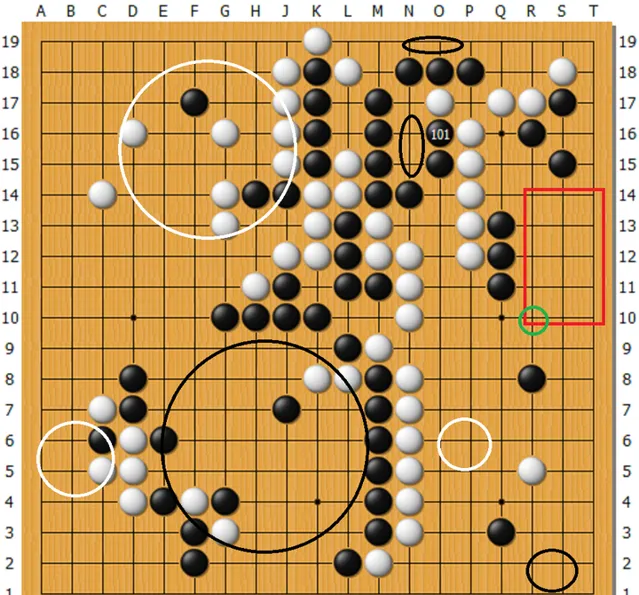
這是棋局進行到第101手時的局面。李世乭在棋盤上落下的這一手確保了右上黑棋的安全。由於AlphaGo在左下步伐紊亂,黑棋收獲頗豐。沈浸在樂觀情緒中的職業棋手們一致判斷黑棋明顯優勢。直觀來看,此局面的判斷並不復雜:黑方下邊一塊確定的目數,基本可以和白方全域確定的目數+厚味抗衡;黑方額外多出右邊紅框裏的地盤,意味著黑棋盤面(即不計貼目)領先15目左右。然而,當時沒有人想到,右邊紅框範圍內看上去已經萬無一失屬於黑棋的地盤,即將被AlphaGo掏空。
敏銳如柯潔者,第一時間看到了白棋在R10(圖中綠圈)打入的手段。不過,柯潔當時的說法是,這是落後一方孤註一擲的手法。局後回顧,才發現此處黑棋已無法全身而退,而AlphaGo對此早已成竹在胸。從DeepMind公布的數據來看,AlphaGo認為此局面下白方的勝率超過75%,這意味著AlphaGo對R10打入之後的變化充滿信心。棋局的走向證明了AlphaGo判斷的正確,而職業棋手的直覺在此處集體失靈。
————
AlphaGo在復雜局面下的形勢判斷,比職業棋手的判斷更精準。
更重要的是,AlphaGo基於概率的形勢判斷,比人類棋手比較地盤多寡的判斷,更接近圍棋的本質。學棋的時候,老師常說,贏半目和贏一百目沒有區別。圍棋十訣第一條就是「不得貪勝」。說明人類棋手都認同,保住勝利果實,比拿到更多地盤更重要(也許藤澤秀行棋聖是個例外)。然而,具體操作中,人類的形勢判斷演算法並不能實作這一目標。
為了幫助理解,我舉個例子。
在某一盤棋的後半盤,黑方確定目數70目,沒有潛力。白方確定目數40目,有一塊40目潛力的大空。如果黑方立即打入(選項A)並活出(結局A1),則40目的潛力只能轉化成10目的實地,黑方獲勝。如果黑方打入失敗(結局A2),則白棋40目大空圍成,白方獲勝。黑棋也可以選擇保守的淺消(選項B),則白方的40目潛力 大約 能轉換為25目實地 。
這個局面下,如果選擇淺消(選項B),雖然最後差距會縮小,然而其實勝機也很少。很遺憾,這種局面下,職業棋手很難準確估算打入成活的概率,然而AlphaGo可以。於是心存幻想的人類棋手覺得落後不多,而打入無成算,選擇淺消白棋大空,結果白方40目的潛力轉化成25目實地,黑棋盤面僅多5目,從而落敗。Alpha狗估算出選擇打入(選項A)的勝率是40%,而選擇淺消勝率僅為25%,於是毅然選擇打入。不論最後勝負如何,選擇打入顯然是更好的策略。
換句話說,只「領先兩目」而勝率80%,和「領先五目」而勝率70%,其實是前者優勢更大,然而人類會認為後者優勢更大。
AlphaGo有能力精確地估算勝率,人類棋手不能。因此我說,AlphaGo對圍棋的理解,比人類高一個境界。
我們可以進一步想象,假如有一天,人類造出了一台能夠做無限快計算,且儲存能力無限大的機器。那麽這台機器判斷一個圍棋局面,不會輸出勝率,而是會輸出「此局面黑棋(白棋)必勝」。這就又比AlphaGo對圍棋的理解高一個境界,是真正破解了圍棋。
不過,由於圍棋的復雜度,我不認為這樣的機器能夠在一百年(原來寫千年,有人批評,我也覺得不謹慎)以內被發明出來。 換句話說,AlphaGo的演算法,是目前我們能做到的對圍棋問題的最好解決方案。 此後的圍棋AI,大概只需要在這個框架的基礎上修修補補了吧。
而人類也沒必要為此感到悲哀。AlphaGo是個好老師。雖然學不了她的判斷方法,但是具體招法可以借鑒。將來AlphaGo或者其他AI的形勢判斷,也可供參考。將來十年,圍棋技術一定會快速發展變化,我等棋迷有好戲可以看了。
相關文章:AlphaGo與人類的恩怨情仇(一):世紀難題 - 知乎專欄









