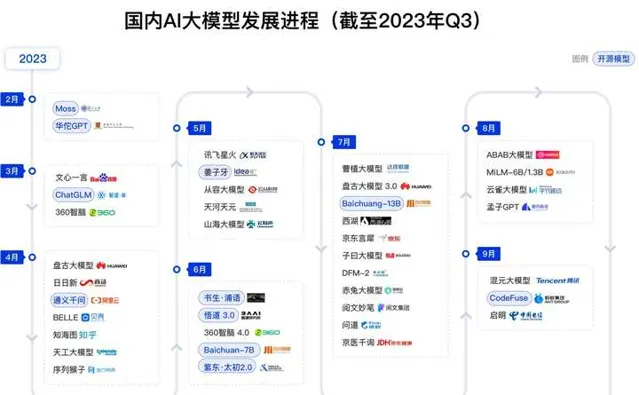
這個問題問得很好。這一年雖然AIGC行業新聞不斷、熱點頻出,百模大戰,幾乎把中國古代的聰明人和神獸的名字都用光了。
年中資本市場上各種AI股票翻倍地漲(到下半年又都逐步回吐漲幅),年底OpenAI還來了一場震驚全球的「逼宮大戲」,可謂熱鬧是足了,但是也最終呈現出了一些華麗之下的真相,既有技術上的,也有商業上的:
- 國內大部份模型都是拿國外開源模型套殼,還美其名曰開發「垂直模型」。 本質上就是下載好預訓練的開源模型,然後用自己的一些行業數據、私域數據進行微調,甚至直接拿來什麽也不改的,臉不紅心不跳地說自己自主研發、自主可控的大模型。反正,神經網絡是個「黑盒子」,你有沒法拆開看到底是哪裏來的,不像芯片還能打磨一下看到裏面的logo。
- 當然,國內現在也有一些自研的大模型,特別是大廠開發的,而且要看參數,那絕對是「遙遙領先」,你7B,我就20B,你147B,我就來個萬億,總之卷數據,沒有誰可以卷得過國內企業的。至於說效能,考試那更是我們擅長的。結果就是,看著評分,很多國產大模型已經超過了GPT3.5甚至GPT4,但是一用起來,馬上感覺完全不是那麽回事。為啥呢? 很簡單,因為這是開卷考試,我根據你的考題最佳化就行了。 目前國內的所有模型裏面,我實際使用下來,「智譜清言」(ChatGLM)是開源、閉源中效果最好的,特別是跟工程、技術相關的內容,相當準確。
- 經過前期的喧囂之後,大部份的初創套用都已經難以為繼。 如上所述,真正在模型層面有所研發和突破的,很少。那麽大部份就是一些包殼的工具(面向C端),還有一些針對特定行業的、經過微調的模型,但是隨著大模型本身越來越強大,還有大模型普遍存在的「幻覺」問題(面向B端),使得企業對於對內或者對外使用AIGC,感覺非常慎重。
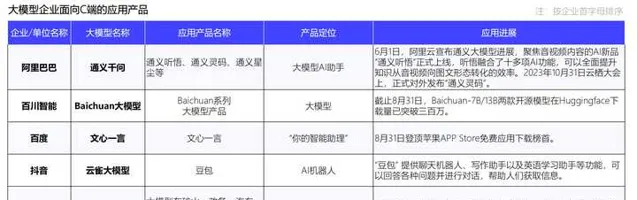
- 但是,的確也逐漸沈澱出了一些有實際效果,也得到使用者認可的套用:
- 在文書處理領域,WPS、Flowus、飛書,都學習Notion、Office365的模式,開始為收費使用者提供一定的AI輔助寫作功能,也的確很多人感受到了其中的便利。但是實際比較下來,感覺還是有一定的差距,需要慎重使用。
- 在影像處理方面,因為國內直接使用Midjourney不方便(Discord用不了),所以各種用Stable Diffusion模型訓練的工具很多,其中也跑出來了幾個知名的。
- 在輔助辦公方面,一個重要的方式是用大綱、文字描述,直接生成PPT,這裏面叠代比較快的是Mindshow和AIPPT。











