題主沒說自身水平,姑且當做零基礎吧。大概只有剛從零基礎走過的人最懂怎麽零基礎入門吧。我之前寫過一個SQL教程,就放到這兒供大家參考一下吧,不當之處敬請指正。
寫在前頭
嚴格來說,SQL並不是一門程式語言,只是一個取數工具,與它的原意 (結構化查詢語言) 比較貼切。 和很多初學者一樣,我學習SQL最大的門檻並非這門語言本身的難易,而是缺乏一個科學有效的學習路徑 。
我嘗試過看書(【Head First SQL】,【SQL必知必會】等系統性的書籍),也在一個月內準備並透過了數據庫二級、三級的電腦等級考試,更看過形形色色的SQL題目。
然而這些都不能讓我透過TMD某家的二面SQL技術面,後來我在另一家TMD實習中每天都需要寫大量的SQL,技術幾乎瞬間就提上去了。在沒有實習練手機會的情況下,如何在短時間快速上手SQL對於在校學生或者非技術人員都是相當重要的。
章節安排
本篇文章的目的主要是幫助 初學者 在初步知曉SQL語句的情況下在一天之內系統入門SQL,從而解決80%的sql查詢問題。本文主要框架如下:
SQL
的語法順序和執行順序
希望學完這三篇後能助你系統地入門
SQL
。
快速上手SQL的常用語法
0. 搭配學習
初學SQL時買過形形色色的書,大部份書籍存在兩個問題:一是陳舊晦澀脫離實際(尤其是電腦等級考試用書,內容迂腐且入門成本較高),二是面面俱到主次不分(尤其是大部頭的經典書籍)。如果你也是零基礎入門SQL,可以使用下面這本書,不至於被眼花繚亂的書籍勸退:
PDF:https://www. yuque.com/tomocat/txc11 h/ni8rifhcd7tqspx
1. 透過單表查詢逐步理解
SQL
語法
學生表student結構:
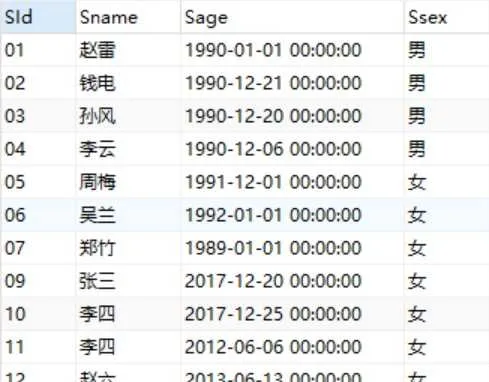
先看一個查詢例子:
查詢表中所有學號小於8的男學生的學號和姓名
select
sid
,
sname
#
需要查詢出來的欄位
from
student
#
從哪張表中取數
where
ssex
=
'男'
and
sid
<
8
#
設定查詢的條件
,
兩個條件用
and
(
和
)/
or
(
或
)
連線
暫時我們沒有對欄位做處理,
如果你需要對選擇出來的結果進行處理
,需要使用函數和
order by
,再看一個例子:
select
sid, sname
, (curdate())-year(sage) as age #當前年份減去出生年份得到年齡
from student
where ssex = '男'
order by sid desc # order by表示按照欄位排序, desc表示降序
其他常用的函數和
where
條件:
sid
升序並取前三條
select
sid, sname
from student
where sname like '張%' # 透過like和通配符%進行模糊匹配
and sid is not null # 學號非空
order by sid
limit 3 # 只取前三條
2. 多表查詢
學生表student:
成績表sc:
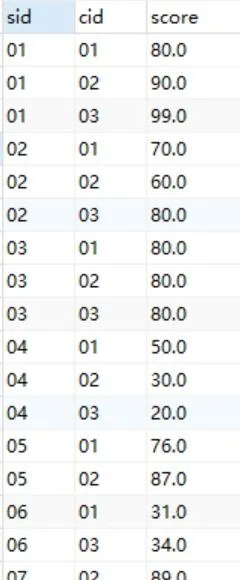
透過
join
連線兩張表:
select
sname, cid, score
from student
inner join sc
on student.sid = sc.sid # 兩張表的連線條件,滿足條件的兩行會並為一行
where sc.sname = '趙雷'
本文用到的數據庫表
為方便學習,我們繼續使用之前用到的學生表
student
和成績表
sc
,為了模擬業務中復雜的查詢任務,我們再引入課程表
course
和教師表
teacher
。
SQL
的前提一定是先了解你的數據庫表,現在花點時間看看這四張表的欄位資訊(描述每個欄位的意義)和數據樣例(給出部份真實數據),關於業務中用到的表結構可以找數據小哥拿。
1.欄位資訊
學生表:
Student(SId,Sname,Sage,Ssex)
SId 學生編號,Sname 學生姓名,Sage 出生年月,Ssex 學生性別
課程表:
Course(CId,Cname,TId)
CId 課程編號,Cname 課程名稱,TId 教師編號
教師表:
Teacher(TId,Tname)
TId 教師編號,Tname 教師姓名
成績表:
SC(SId,CId,score)
SId 學生編號,CId 課程編號,score 分數
2. 數據樣例
2.1 學生表
2.2 課程表
2.3 教師表
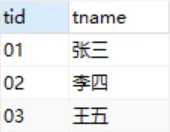
2.4 成績表
SQL的執行順序與語法順序
本篇文章關於
SQL
語法的部份會講到
條件子句
(
where
子句)、
分組查詢
(
group by
子句和
having
子句)、
結果呈現
(
order by
和
limit
)和
連線查詢
(
left/right/inner join
)。
看到這你可能會瞬間頭大,但是由於
SQL
語言是有
執行優先級
的,這給了我們
分塊講解
的機會,私以為這也是
SQL
語言易學的重要原因。
為了解釋清楚
SQL
語言的執行順序和語法順序,讓我們先看看下面這個
Hive
單表查詢的完整結構:

任何一個單表查詢的
SQL
都可以分解成上述格式,實際上抽象化後的多表連線查詢也可以分解成如上格式。從上到下是
SQL
的語法順序(即你書寫
SQL
的格式),而
SQL
真實的執行順序如下:
 筆者寄語:舉個簡單的例子加深理解,
筆者寄語:舉個簡單的例子加深理解,
SQL
的語法順序就像小說的插敘,而
SQL
真正的執行順序就是小說的時間順序。
透過一個例項復習SQL的執行順序
上面的講解可能讓你一知半解,在正式介紹各部份
SQL
語法前我們先透過一個例項復習上面
SQL
的執行順序。
例如,有這麽一個業務查詢任務:
在限定學生表學號小於等於
6
的一批學生中,查詢每門課的最高成績(最高成績低於
70
分的課程不顯示),然後根據課程最高成績降序排列取前兩條記錄。查詢的
SQL
如下:
select
cid # 課程號
, max(score) as max_score # 最高分
from sc # 成績表
where sid <= 6
group by cid
having max(score) >= 70
order by max(score) desc
limit 2; # 只展示前兩條數據
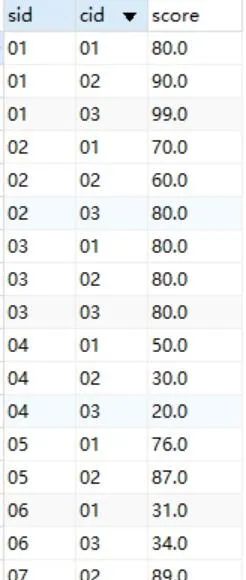
為方便閱讀,下面列出被查詢的成績表
sc
和查詢後的結果:
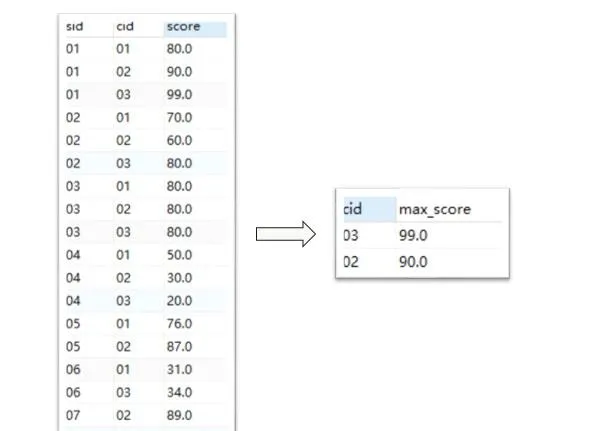
1. 條件子句——為被查詢的表增加限制條件
where sid <=6
限制只查詢學號小於等於
6
的學生成績
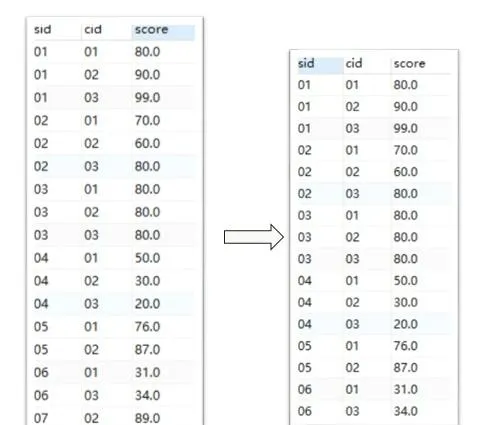
2.分組查詢——實作聚合(group by + 聚合函數)限制聚合條件(having)
如果用過數據透視表的話應該比較容易理解分組查詢的概念,分組查詢一般和聚合函數一起實作,例如檢視每個班的平均成績、檢視每個學生的最高成績或者檢視每個班的最低成績等分組資訊。
我們仍然用直觀的數據變化來展示分組查詢:
group by cid
按照課程分組檢視每門課的聚合資訊
max(score)
搭配
group by
子句使用的聚合函數,表示每門課的最高成績
having max(score) >=70
對分組後的結果篩選,選取最高成績
>=70
的課程

3.欄位選擇——select
在
group by
分組後緊跟著我們會選擇需要呈現的欄位,為了方便講解,其實
分組查詢
中呈現的圖片已經是
select
的結果了。
4.結果呈現——排序(order by)和限制條數(limit)
order by
和
limit
都是為了修改最終呈現結果。
order by
首先執行,按照某個欄位進行排序(
desc
關鍵字表示降序),這部份和
excel
的排序很相似。最後我們使用
limit
來修改結果展示的條數。

介紹各個子句的細節
之前我們已經用一個例子介紹了SQL的語法順序和執行順序,想必現在你已經知道了一個完整的SQL包括條件子句(關鍵字where)、分組查詢(關鍵字group by)、欄位選擇(關鍵字select)和結果呈現(關鍵字order by)。本部份我們旨在將實務中最常出現的詳細情況進行說明,從而 解決初學者80%的sql查詢任務 。
一、條件子句(where)
1. 比較運算子(適用於區間)
比較運算子包括
=
(等於),
>=
(大於等於),
<=
(小於等於),
!=
(不等於),
>
(大於),
<
(小於)。比如查詢年齡小於
30
的學生:
where sage < 30
2. 確定範圍(適用於連續範圍)
between … and …
為取值限定了一個範圍。例如:查詢年齡大於等於
10
小於等於
20
的學生:
where sage between 10 and 20
3. 確定集合(適用於離散的少數值)
例如:插入年齡為
10,20,30
的學生:
where sage in (10,20,30)
# in可以和not一起使用,表示不在這個區間的值
where sage not in (10,20,30)
4. 字元匹配(模糊查詢)
透過
like
關鍵字和正規表式匹配,常用的通配符有
%
(任意個字元)和
_
(一個字元)。例如:查詢名字
sname
帶「王」的學生:
where sname like 「%王%」
5. 判斷是否為空值
透過
is null
關鍵字判斷值是否為空。例如:查詢姓名
sname
不為空的學生:
where sname is not null
6. 多個查詢條件
用
and
(兩個條件同時滿足)和
or
(兩個條件滿足一個即可)。例如:查詢年齡
sage
小於
20
且性別
ssex
為男的學生:
where sage < 20 and ssex = '男'
二、分組查詢(group by&聚合函數&having子句)
分組查詢實作了類似
excel
中數據透視表的功能,可以幫助我們對數據進行
分層匯總
,而我們對分層後的數據進行統計的時候需要用到
聚合函數(也就是平均值、求和、最大值和最小值等)
,最後我們對
分層之後
的數據篩選的時候需要用到
having
子句。
where
子句是對原始表做篩選的
having
子句是對分層匯總之後的結果做篩選的
6
的一批學生中,查詢每門課的最高成績(最高成績低於
70
分的課程不顯示),然後根據課程最高成績降序排列取前兩條記錄。
select
cid
,max(score) as max_score
from sc
where sid <= 6
group by cid
having max(score) >= 70
order by max(score)
limit 2;
回顧一下執行順序,首先我們用
where
子句對原始數據做了學號
id
需要小於等於
6
的限制。然後我們用
group by
和
max(score)
聚合函數實作了對
課程進行分層,求出每門課的最高成績
,為了對聚合之後的結果作限制,我們用
having
子句只展示最高分數大於等於
70
的記錄。
關於這個例子詳細解釋可以回顧上篇文章,下面我們詳細介紹每個部份的常用語句。
1. group by
group by
不僅可以對一個欄位進行分組,還能對多個欄位進行分組。這和
excel
中的數據透視表一致。
2. 聚合函數
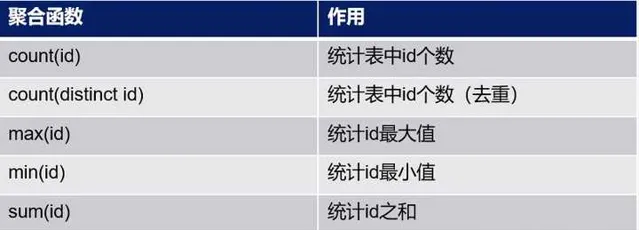
3. having子句
和
where
子句一致,
只需註意是對聚合後的結果作限制
。
三、欄位選擇(select)
select
比較靈活,我們不單單能選擇原始數據表的欄位,還能使用函數對欄位進行計算,
正如我們第一篇提到的,函數並不是重點,當你需要的時候百度或者問技術小哥就知道了
。我們這裏只簡單介紹一下可以對欄位進行計算。
select
sid, sname, year(curdate()) - year(sage) as sage
from student;
四、結果呈現(order by)
-
和
excel一樣,可以用多個欄位排序 -
關鍵字
desc表示降序排列
id
和年齡,並先按照學號
sid
降序,再按照年齡
sage
升序排列
select
sid, sage
from student
order by sid desc, sage
表的連線和其他常用關鍵字
一、表的連線
我們前面已經介紹過透過等值連線
join
實作兩個及兩個以上表的查詢需求,
sql
表連線包括內連線、外連線和交叉連線
,我們透過一個例子簡單介紹三種連線的異同。
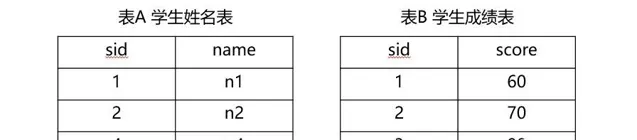
1.待連線的表的資訊
現在有一張
A
表和
B
表,
A
表記錄學生學號
sid
和對應的姓名
name
,
B
表記錄學生學號
sid
和對應的分數
score
。
2. 內連線
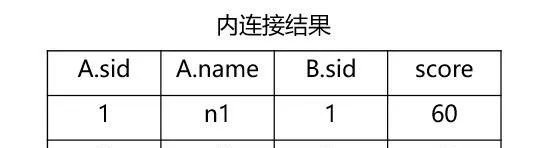
內連線即透過對某個欄位進行等值匹配從而將兩個表聯合起來,比方說我們需要獲取兩張表中同一個學號對應的姓名和成績,使用的就是
inner join
,結果如下:
3.左連線和右連線
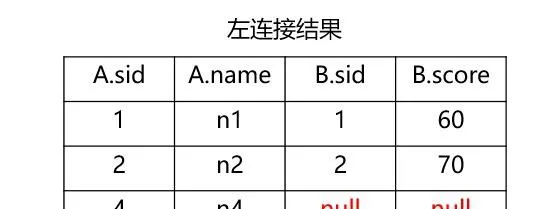
一般情況下,「A表左連線B表」的結果與「B表右連線A表」的結果相同,為了保證
SQL
程式碼的易閱讀性,一般用左連線即可。
左連線指的是將左表作為基準表,保留表中的所有行,將右表根據某個欄位進行等值匹配,如果找不到右表中匹配的行則顯示為
NULL
。結果如下:
 當然,還有全連線,在某些用途下也有用處,這裏就不展開說了
當然,還有全連線,在某些用途下也有用處,這裏就不展開說了
4.交叉連線
沒有連線條件的表連線將產生笛卡爾積,即連線結果行數等於
A
表行數乘上
B
表行數,可以理解為兩個表的記錄兩兩配對產生的結果。結果如下:
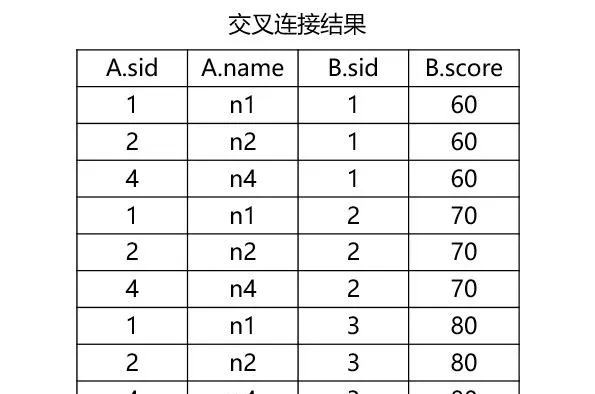
二、其他常用關鍵字
列舉一些在
hive
取數時常用的關鍵字。
1.
case when
根據欄位的不同值進行不同的操作,存在大量的變形操作可以實作不同的功能,最簡單的情形如下:
# sex欄位為1和2,現在要轉化為更為直觀的文字形式
case sex
when '1' then '男'
when '2' then '女'
else '未知'
end as sex
2.
count+distinct+if
實作統計
# 統計成績單中及格同學的人數(單個學號可能出現多條記錄)
count(distinct(if(score >= 60,sid,null)))
3.
sum+if
實作分組統計(這裏
sum
可以替換為其他聚合函數)
# 獲取男性學生的總成績
sum(if(sex = '男', score, 0))
寫在最後
整理了一下思維導圖
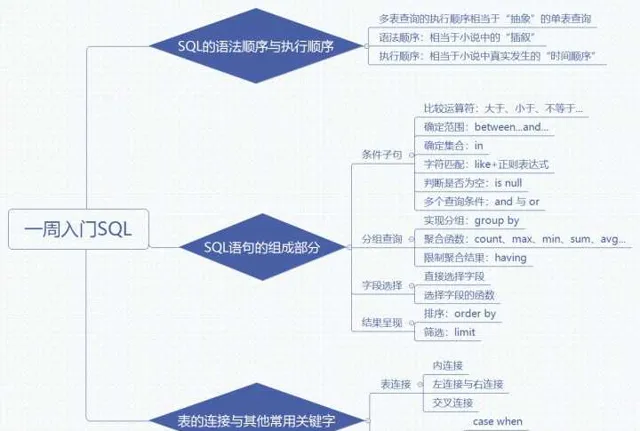
如果你看到了這裏
上中篇應該已經能夠讓你開始刷題了,關於刷題可以刷這個:
有任何意見歡迎評論,如果覺得有幫助辛苦點個贊讓更多人能看到吧謝謝~
精進
對自身有更高要求的同學,比如從事數據分析和後端開發(恰巧這也是我主要涉獵的兩個領域),可以看下面這本書,歡迎交流~











