2020年底給某大廠做過一個報告,包含兩部份內容:一部份是關於電腦體系結構,尤其是CPU結構的演變;另一部份關於處理器芯片設計方法。這裏把第一部份內容貼出來回答一下這個知乎問題。

- 首先回顧一下電腦體系結構領域三個定律: 摩爾定律、牧本定律、貝爾定律 。摩爾定律就不用多說了,但想表達一個觀點是摩爾定律未死,只是不斷放緩。
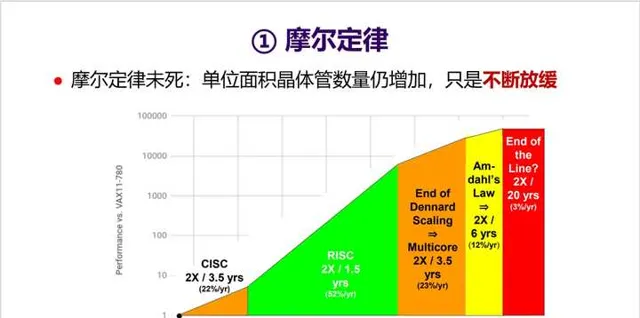
2. 摩爾定律讓芯片上的晶體管數量不斷增加,但一個問題是 這些晶體管都被充分用起來了嗎 ?最近MIT團隊在【Science】上發表了一篇文章【There’s plenty of room at the Top: What will drive computer performance after Moore’s law?】,給出他們的答案: 顯然沒有 !
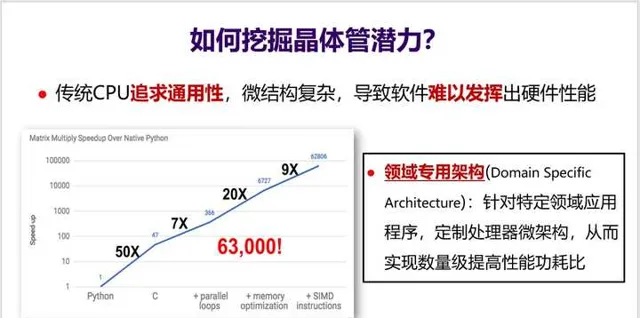
可以來看一下MIT團隊開展的一個小實驗(見下面PPT):假設用Python實作一個矩陣乘法的效能是1,那麽用C語言重寫後效能可以提高50倍,如果再充分挖掘體系結構特性(如迴圈並列化、訪存最佳化、SIMD等),那麽 效能甚至可以提高63000倍 。然而,真正能如此深入理解體系結構、寫出這種極致效能的程式設計師絕對是鳳毛麟角。
問題是 這麽大的效能差異到底算好還是壞 ?從軟件開發角度來看,這顯然不是好事。這意味著大多數程式設計師無法充分發揮CPU的效能,無法充分利用好晶體管。這不能怪程式設計師,更主要還是因為CPU微結構太復雜了,導致軟件難以發揮出硬件效能。
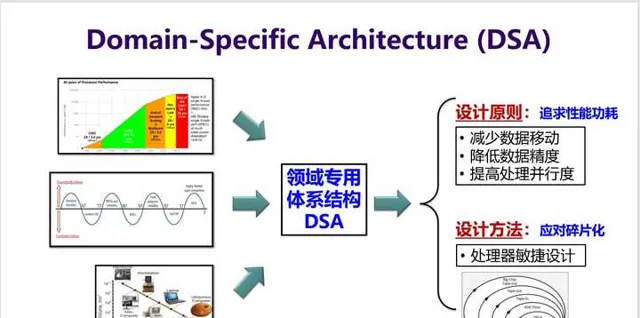
如何解決這個問題? 領域專用架構DSA(Domain-Specific Architecture)就是一個有效的方法 。DSA可以針對特定領域應用程式,客製微結構,從而實作數量級提高效能功耗比。這相當於是 把頂尖程式設計師的知識直接實作到硬件上 。
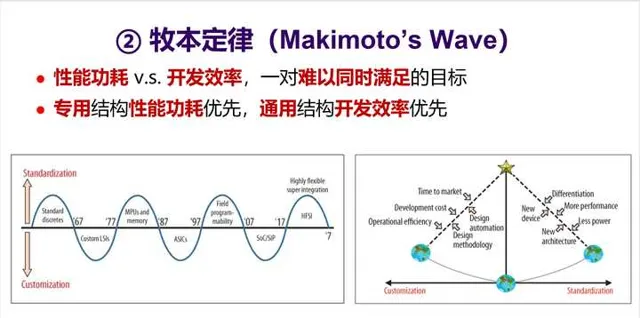
3. 第二個定律是 牧本定律 (也有稱「牧本波動」)。1987 年, 原日立公司總工程師牧本次生(Tsugio Makimoto,也有轉譯為牧村次夫,故稱為「牧村定律」) 提出,半導體產品發展歷程總是在「 標準化」與「客製化 」之間交替擺動,大概每十年波動一次。牧本定律背後是效能功耗和開發效率之間的平衡。
對於處理器來說,就是 專用結構和通用結構 之間的平衡。最近這一波開始轉向了追求效能功耗,於是專用結構開始更受關註。
4. 第三個定律是 貝爾定律 。這是Gordon Bell在1972年提出的一個觀察,具體內容如下面的PPT所述。值得一提的是超級電腦套用最高獎「哥頓·貝爾獎」就是以他的名字命名。
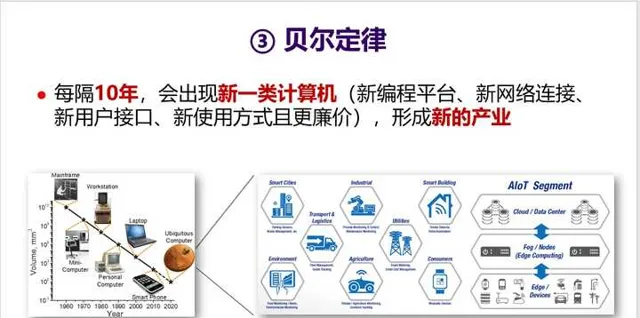
5. 貝爾定律指明了未來一個新的發展趨勢,也就是AIoT時代的到來。 這將會是一個處理器需求再度爆發的時代,但同時也會是一個需求碎片化的時代 ,不同的領域、不同行業對芯片需求會有所不同,比如整合不同的傳感器、不同的加速器等等。 如何應對碎片化需求 ?這又將會是一個挑戰。
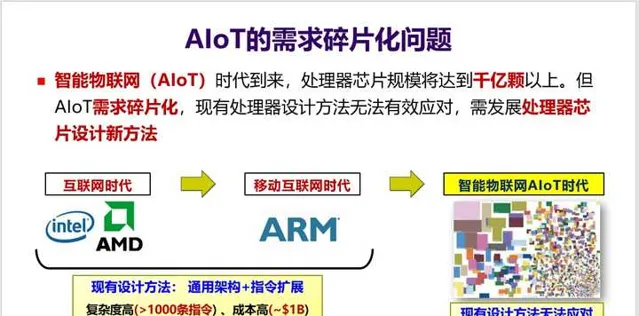
6. 這三個定律都驅動電腦體系結構向一個方向發展,那就是「DSA」 。如何實作DSA,這又涉及到兩個方面:
- 為了追求效能功耗,有三條主要的設計原則(見下面PPT);
- 為了應對碎片化需求,則需要發展出處理器敏捷設計新方法。(這個回答就不介紹敏捷設計方法了)
7. 在談一些具體技術之前,我們可以 先總體看一下過去幾十年CPU效能是如何提升的 。下面這頁PPT列出了1995-2015這二十年Intel處理器的架構演進過程——這是一個不斷叠代最佳化的過程,整合了上百個架構最佳化技術。
這些技術之間還存在很多耦合,帶來很大的設計復雜度。比如2011年在Sandy Bridge上引入了 大頁面技術 ,要實作這個功能,會涉及到 超純量、亂序執行、大記憶體、SSE指令、多核、硬件虛擬化、uOP Fusion 等等一系列CPU模組和功能的修改,還涉及 作業系統、編譯器、函數庫 等軟件層次修改,可謂是牽一發動全身。( 經常看到有人說芯片設計很簡單,也許是因為還沒有接觸過CPU芯片的設計,不知道CPU設計的復雜度 )

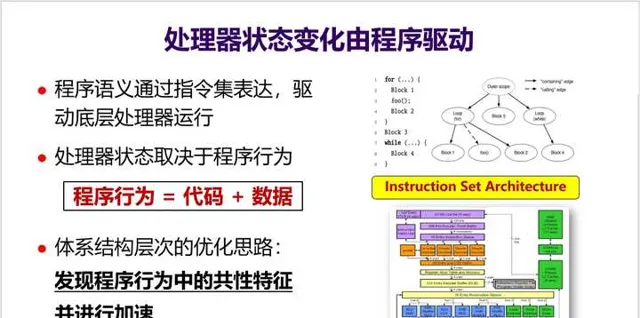
8. 處理器內部有非常復雜的狀態,其狀態變化是由程式驅動的。也就是說, 處理器狀態取決於程式行為 (見下面PPT),而CPU體系結構層次的最佳化思路就是 發現程式行為中的共性特征並進行加速。
如何發現程式行為中的共性特征,就是處理器最佳化的關鍵點,這 需要對程式行為、作業系統、編程與編譯、體系結構等多個層次都有很好的理解,這也是電腦體系結構博士的基本要求 。這也是為什麽很多國外的電腦體系結構方向屬於Computer Science系。
題外話:這兩天看到國內成立集成電路一級學科,這是一個好訊息。不過 要能培育CPU設計人才,在課程設計上不要忽視了作業系統、編程與編譯這些傳統電腦科學的課程 。
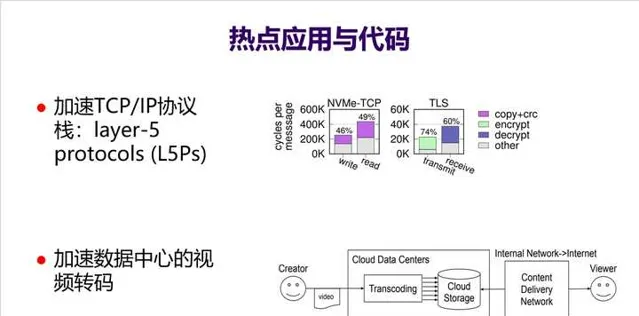
9. 舉兩個發現熱點套用和熱點程式碼、並在體系結構層次上最佳化的例子 。一個例子是發現在不少領域 TCP/IP協定棧五層協定(L5Ps) 存在很多大量共性操作,比如加密解密等,於是直接在網卡上實作了一個針對L5Ps的加速器,大幅加速了網絡包處理能力。另一個例子是這次疫情導致雲端運算數據中心 大量算力都用來做影片轉碼 ,於是設計了一個硬件加速器專門來加速影片轉碼,大幅提升了數據中心效率。
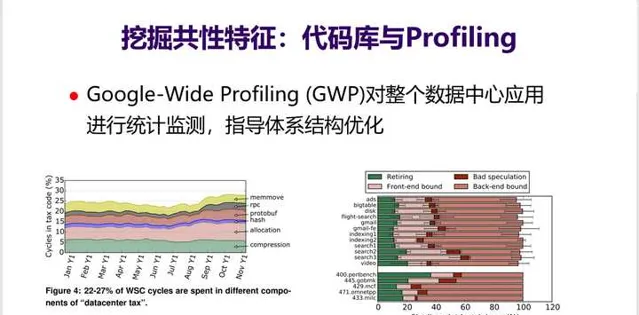
10. 發現和辨識這種熱點套用和熱點程式碼並不容易, 需要由很強大的基礎設施和分析器材 。比如Google在其數據中心內部有一個GWP工具,能對整個數據中心套用在很低的開銷下進行監測與統計,找到算力被那些熱點程式/程式碼消耗,當前的CPU哪些部件是瓶頸。比如 GWP顯示在Google數據中心內部有5%的算力被用來做壓縮。
正是 得益於這些基礎工具,Google很早就發現AI套用在數據中心中套用比例越來越高,於是開始專門設計TPU來加速AI套用 。
11. 下面分別從三個方面來介紹體 系結構層面的常見最佳化思路 : 減少數據移動、降低數據精度、提高處理並列度 。
首先看一下如何減少數據移動。第一個切入點是 指令集 ——指令集是程式語意的一種表達方式。 同一個演算法可以用不同粒度的指令集來表達,但執行效率會有很大的差別 。一般而言,粒度越大,表達能力變弱,但是執行效率會變高。
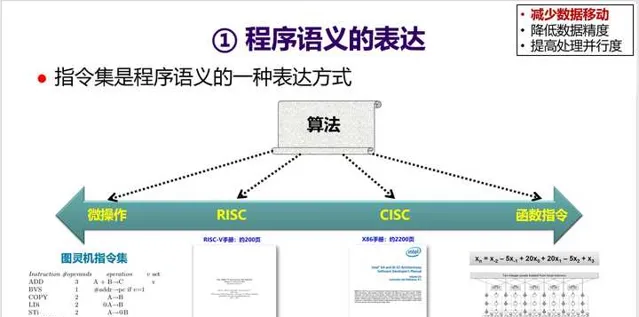
12. 通用指令集為了能覆蓋盡可能多的套用,所以往往需要支持上千條指令,導致 流水線前端設計(取指、譯碼、分支預測等)變得很復雜,對效能與功耗都會產生負面影響 。

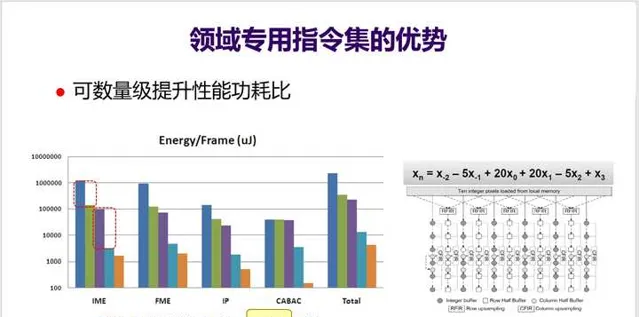
13. 針對某一個領域設計專用指令集,則可以大大減少指令數量,並且可以 增大操作粒度、融合訪存最佳化,實作數量級提高效能功耗比 。下面PPT的這組數據是史丹福大學團隊曾經做過的一項研究,從這個圖可以看出, 使用了「Magic Instruction」後,效能功耗比大幅提升幾十倍 。而這種Magic Instruction其實就是一個非常具體的運算式以及對應的電路實作(見PPT右下角)。
14. 第二個減少數據移動的常用方法就是充分發揮緩存的作用 。訪存部件其實是處理器最重要的部份了,涉及許多技術點(如下面PPT)。 很多人都關註處理器的流水線多寬多深,但其實大多數時候,訪存才是對處理器效能影響最大的 。
關於訪存最佳化,也有一系列技術,包括替換、預取等等。這些技術到今天也依然是體系結構研究的重點,這裏就不展開細講了。

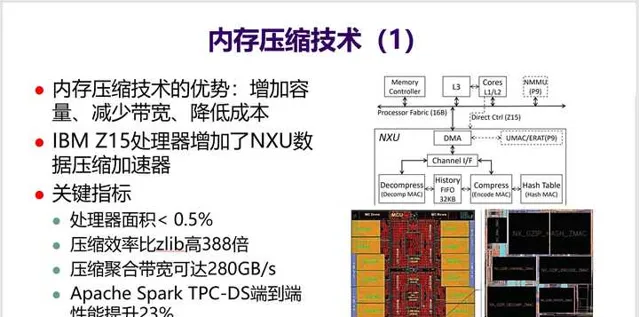
15. 不再展開介紹訪存最佳化技術,就選 最近比較熱的記憶體壓縮方向 介紹一下。
IBM在最新的Z15處理器中增加了一個記憶體壓縮加速模組,比軟件壓縮效率提高388倍,效果非常突出。
16. 輝達也在研究如何 在GPU中透過記憶體壓縮技術來提升片上儲存的有效容量 ,從而提高套用效能。

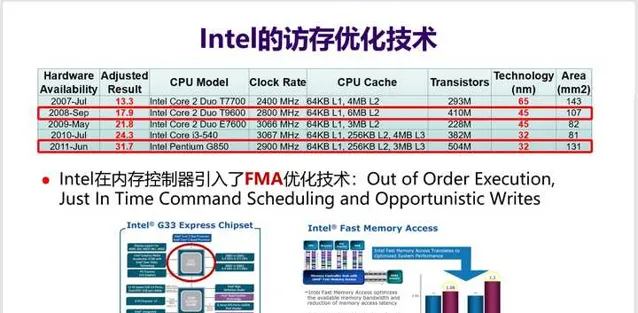
17. Intel在訪存最佳化上很下功夫 ,可以透過對比兩款Intel CPU來一窺究竟。Core 2 Due T9600和Pentium G850兩塊CPU,工藝差一代,但頻率相近,分別是2.8GHz和2.9GHz,但效能差了77%——SPEC CPU分值G850是31.7分,而T9600只有17.9分。
頻率相當,為何效能會差這麽多 ?事實上,G850的Cache容量比T9600還要小——6MB L2 vs. 256KB L2 + 3MB L3。
如果再仔細對比下去,就會發現這兩款處理器 最大的區別在於G850適配的記憶體控制器中引入FMA(Fast Memory Access)最佳化技術 ,大幅提高了訪存效能。
18. 第二類體系結構最佳化技術是降低數據精度 。這方面是這幾年研究的熱點,特別是在深度學習領域,很多研究發現不需要64位元浮點,只需要16位元甚至8位元定點來運算,精度也沒有什麽損失,但效能卻得到數倍提升。
很多AI處理器都在利用這個思路進行最佳化,包括前段時間日本研制的世界最快的超級電腦「富嶽」中的CPU中就采用了不同的運算精度。因此其 基於低精度的AI運算能力可以達到1.4EOPS,比64位元浮點運算效能(416PFLOPS)要高3.4倍 。

19. IEEE 754浮點格式的一個弊端是不容易進行不同精度之間的轉換 。近年來學術界提出一種新的浮點格式——POSIT,更容易實作不同的精度,甚至有一些學者 呼籲用POSIT替代IEEE 754 (Posit: A Potential Replacement for IEEE 754)。
RISC-V社區一直在關註POSIT,也有團隊實作了基於POSIT的浮點運算部件FPU ,但是也還存在一些爭論(David Patterson和POSIT發明人John L. Gustafson之間還有一場精彩的辯論,另外找機會再介紹)。

20. 體系結構層次的第三個最佳化思路就是並列 。這個題目中提到的「多核」,就是這個思路中一個具體的技術。除了多核,還有其他不同層次的並列度,比如指令集並列、執行緒級並列、請求級別並列;除了指令級並列ILP,還有訪存級並列MLP。總之,提高處理並列度是一種很有效的最佳化手段。

以上是關於電腦體系結構尤其是CPU結構最佳化思路的一個大致梳理,供大家參考。總結來說就是兩點結論:
- 領域專用體系結構DSA是未來一段時間體系結構發展趨勢;
- 體系結構層面3條最佳化路線——減少數據移動、降低數據精度、提高處理並列度。









