終於來了個自己研究方向的題目~
PS:路徑規劃(Path Planning)與運動規劃(Motion Planning)在數學上是同一個問題,所以我在文中就直接混用了。
首先,我們要先明確路徑規劃/運動規劃的 定義 :

簡單地說,就是給定環境、機器人模型,指定規劃目標(如無碰撞到達目的點),自動計算出機器人的運動路徑(可以是一序列離散狀態,也可以是運動策略)。
當然,傳統的運動規劃方法可以看我之前發過的兩篇文章(運動規劃 | 簡介篇,運動規劃 | 影片篇),這裏就不展開了。所以,如 @Pickles Husky 所說,如果想將機器學習直接塞到現有的運動規劃,似乎並不是一個好方法。於是,只能想辦法發明新的運動規劃框架了。
第一種,當然就是 監督學習 (Supervised Learning )的形式了。
這個其實很簡單,Andrew Ng 的機器學習公開課(https://www. youtube.com/watch? v=_2zt4yVCkGk )裏就提到了這樣的一個例子
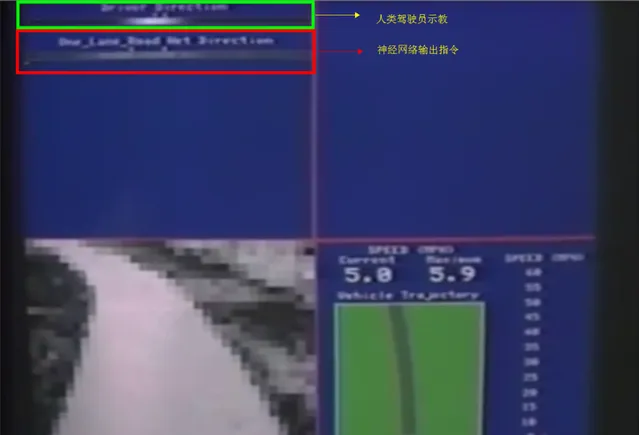
如上圖所示,無人車透過輸入前方影像,在人類駕駛員的標記動作下訓練一段時間後,即可實作汽車的自主駕駛。
當然,上面這個例子的還是很簡單的,所能應對的套用場景也極其有限;深度學習出來後,當然也有人做了類似的工作(前面的答主也有提到過這篇文章):
Pfeiffer, Mark, et al. "From Perception to Decision: A Data-driven Approach to End-to-end Motion Planning for Autonomous Ground Robots." arXiv preprint arXiv:1609.07910 (2016).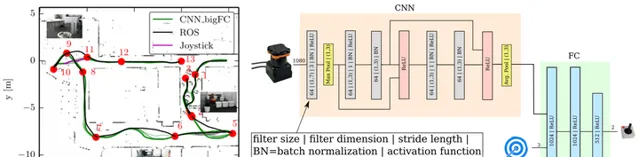
這篇文章的意思大概就是利用 CNN 解析激光資訊,然後利用 A* 演算法作為標記資訊,進行監督學習。所以,這篇論文的工作其實跟前面那個自動駕駛的例子沒什麽太大區別。
目前看來,用監督學習的框架做運動規劃,在環境變化不大的情況下,有可能實作;但是這種方法強烈依賴於標記演算法(平面還好,有A*;高維機械臂的話,沒什麽好的『最優』演算法),而且對環境變化的泛化能力比較弱。
第二種框架就是 強化學習 (Reinforcement Learning)了。這裏我就先不詳細展開強化學習的內容了,有興趣的可以先去刷一遍 Sutton 的書:
Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction . Vol. 1. No. 1. Cambridge: MIT press, 1998.簡而言之,路徑規劃就是一個標準的 MDP 問題,強化學習可以透過值叠代(value iteration)等方法建立一個表格,用以儲存狀態 s (如機器人當前位置)到動作 a (控制指令)的對映。這樣,把機器人放在地圖中任何一個位置,它都能迅速地確定自己下一時刻的動作,而這個動作將引導機器人運動到目標點。
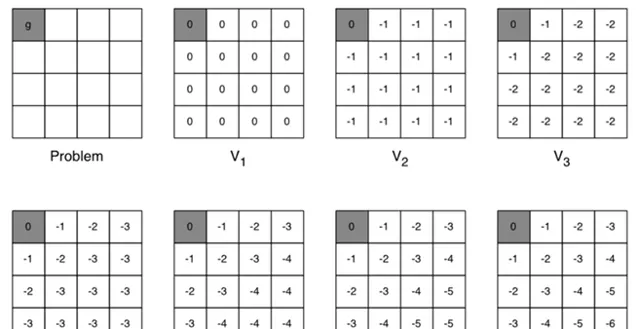
當然,如果目標點不同、障礙物位置不同,我只需生成多張表格即可。但是,這樣就是造成表格太大,占用記憶體太多的問題。
後來,深度學習出現了,它有可能地完成兩件事:1)從傳感器觀測數據 o 中提取出狀態 s;2)擬合出狀態 s 與動作 a 的對映關系(就是前面說的表格)。
大名鼎鼎的 DQN 就可以簡單地認為在做這兩件事(當然,它就是 End-to-End 的結構,實際上並不能簡單地分為這樣的兩個步驟):
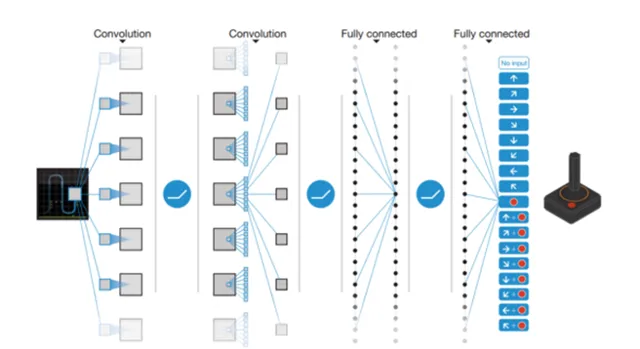 Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
深度強化學習的好處是我們不依賴於人工標記的軌跡,只需要指定規劃目標(無碰撞、到達目的地、路徑最短等),讓機器人不斷嘗試、叠代更新網絡即可。
當然,這一塊用在路徑規劃的工作也已經有了:
Tai, Lei, and Ming Liu. "Towards cognitive exploration through deep reinforcement learning for mobile robots." arXiv preprint arXiv:1610.01733 (2016). Tai, Lei, Giuseppe Paolo, and Ming Liu. "Virtual-to-real Deep Reinforcement Learning: Continuous Control of Mobile Robots for Mapless Navigation." arXiv preprint arXiv:1703.00420 (2017).
這篇文章就是讓移動機器人在仿真環境中不斷嘗試學習、訓練 DQN,最終得到一個較好的路徑規劃結果。
畢竟,現在 Planning-from-scratch 的規劃方法總是給我一種『人類不是這樣規劃的呀』的感覺;深度強化學習又跟人類的技能學習方法很相似;如果成功,規劃時間很短(一次前向傳播的時間)。所以,我感覺,深度強化學習有希望成為徹底解決機器人運動規劃問題的途徑,未來幾年應該也會湧現出一大堆 paper。
PS:從個人角度而言,如果還只是剛開始做路徑規劃的小夥伴,極度不建議直接上深度學習;我還是比較建議先至少把傳統的規劃演算法體系都搞清楚,之後,如有可能,再去嘗試深度學習。理由的話,以後有機會再聊吧。











