來源:Google AI
編輯:LRS
【新智元導讀】 對於多工場景來說,最大的難點就在於如何找到多個任務之間相互關聯的部份。Google Brain團隊在NeurIPS 2021上發表了一篇論文,提出一個親和力指標,能將訓練速度提升32倍,直接少訓練2000個小時,相當於省了6200美元!
通常情況下,一個機器學習模型一次學習過程中只針對一個任務進行訓練。例如語言模型的訓練只有一個任務,就是在給定單詞的上下文來預測下一個單詞的概率,目標檢測的任務就是辨識影像中所有可能存在的物體。但更廣泛的人工智能套用場景要求一個模型能夠很好地完成多個任務,反過來同時學習多工也能極大提高訓練效率和模型效能,從而形成一個正反饋。多工在現實生活中的套用場景也越來越多,機器人需要同時學習如何拾取、放置、對齊和重新排列各種物體等多個任務才能正式「上崗工作」。一個典型的例子就是當你打乒乓球時,不僅要判斷乒乓球的距離、旋轉角度以及判斷乒乓球的執行軌跡,並且同時還要調整身體進行揮拍。但如果要人工智能模型來做,對於過程中的每一個任務可能都需要一個模型來單獨預測,因為預測乒乓球的旋轉角度和預測乒乓球的位置從根本上來說需要不同的特征來進行預測。
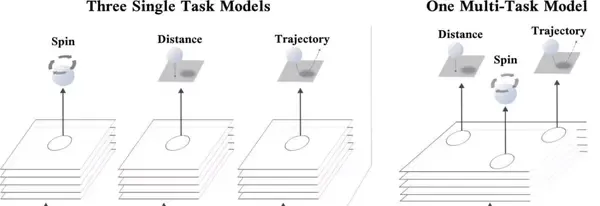
但如果能同時預測好乒乓球的旋轉和位置,則對於更好地推理出乒乓球的預測軌跡來說一定是有幫助的。所以如果一個深度學習模型能夠同時訓練並預測這三個任務,那肯定比單獨預測三個任務來說準確率更高。對於如何有效地訓練多工,Google Brain團隊在NeurIPS 2021上發表了一篇論文,提出了一個新方法,能夠在多工神經網絡中確定哪些任務可以一起訓練。研究人員首先將一組任務分成較小的子集,先使得所有任務都得到充分訓練。
為了達到效能最大化,需要將所有任務一起列入單個多工模型中訓練,並測量每個任務在模型參數上的梯度更新對網絡中其他任務的loss 影響程度,這個影響程度也被稱為任務間的親和力(inter-task affinity)。實驗結果表明選擇最大化任務間親和力的任務組,能夠顯著提升整體模型的效能。

https:// ai.googleblog.com/2021/ 10/deciding-which-tasks-should-train.html
一個多工模型首先面臨的一個問題是:哪些任務可以一起訓練?在理想情況下,一個多工學習模型能夠把它在每一個任務的訓練中獲得的資訊用於降低網絡訓練中包含的其他任務的損失。這種資訊的傳遞融合可以合並為一個模型,這樣不僅可以對多個任務分別做出多個預測,而且與針對每個任務的不同模型的訓練效能相比,多工聯合預測的準確性可能還會提高。但多工聯合訓練也有一個弊端,如果只訓練一個單一的模型可能會導致模型參數量上升。並且如果多個任務是互不關聯的,那模型的效能也會急劇下降。就像如果一個人一邊打乒乓球,一邊在思考費氏數列的下一個值,那肯定會影響他對於乒乓球位置、旋轉角度和軌跡的預測。一個最直接的方法就是對一組任務的多工網絡的所有可能組合進行全面搜尋,挨個嘗試模型的效能,但這種搜尋成本可能會高到勸退。特別是如果任務量非常大的話,那可能的組合方式也會呈指數級增長。
如果模型在執行過程中需要不斷增加和刪除任務的話,那情況將會更加復雜。由於任務是從所有任務集中添加或刪除的,每次增加刪除任務都需要重復測量才能確定新的任務組。此外,隨著模型的規模和復雜性不斷增加,即使是只評估可能的多工網絡的一個子集的近似任務分組演算法,模型的訓練也可能變得十分耗時到難以接受的地步。研究人員受到元學習的啟發,因為元學習的目標就是可以訓練一個能夠快速適應新的、以前未完成的任務的神經網絡。經典的元學習演算法MAML透過對一組任務的模型參數套用梯度更新,然後更新其原始參數集以將該集合中計算的任務子集損失最小化。透過使用這種方法,MAML能夠訓練出一個模型來學習表示。這個表示方法並不是將其當前權重的損失最小化,而是在一個或多個訓練步驟後對權重進行訓練。因此,MAML能夠訓練一個模型使其能夠快速適應以前未完成的任務,因為它是在為未來而不是當下的目標進行最佳化。

TAG使用類似的機制來使得多工神經網絡能夠動態地訓練。並且它只更新單個任務的模型參數來觀察這一變化將如何影響多工神經網絡中的其他任務,然後取消這次更新。透過對其他任務重復此過程,以收集關於網絡中每個任務如何與任何其他任務互動的資訊。然後透過更新網絡中每個任務的模型共享參數,繼續進行正常訓練。收集到這些統計數據後並觀察其在整個訓練過程中的動態情況,可以發現某些任務始終顯示出正向的關系,而有些任務則相互對立(產生負面的效能影響)。網絡選擇演算法可以利用這個資訊將任務分組在一起,以最大化任務間的親和力,這也取決於從業者在推斷過程中可以使用多少多工網絡。任務間的親和力以考慮一個任務對共享參數的連續梯度更新在多大程度上影響網絡中其他任務為目標,並且所有任務的親和力相加作為整體任務的親和力,其中Li代表任務i的損失。
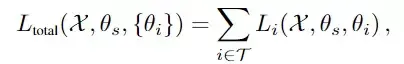
實驗結果表明,TAG可以選擇出強相關的任務組。在Celeba和TaskOnomy數據集上,TAG和sota模型相比執行速度的提升分別為32倍和11.5倍。
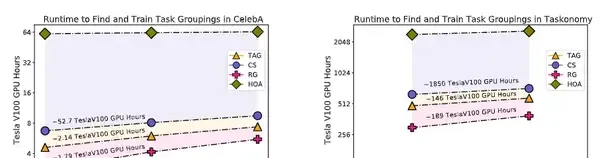
實驗人員還評估了TAG在任務集中對語意分割、深度估計、關鍵點檢測、邊緣檢測和曲面法線預測的任務組選擇的能力。這個評估使用了一個增強版的中型任務單元拆分(2.4 TB),而非完整版(12 TB),這個操作能夠減少計算開銷並提高可復制性。
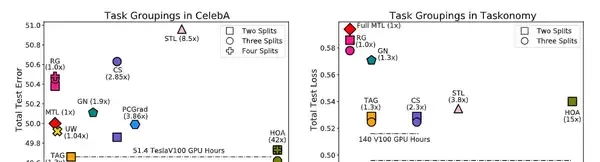
與Celeba上的研究結果相同,TAG繼續以10.0%相比MTL、7.7%相比GN、1.5%相比STL和9.5%相比RG的優勢獲勝。將TAG與HOA進行比較時,可以看到TAG 的2-split 任務分組效能比HOAD高2.5%,但HOA的3-split任務分組效能優於tag。在計算方面,TAG的效率明顯高於HOA,HOA要求額外的2008 TESLAV100 GPU小時來尋找任務組。為了考慮到這一成本,在一個8-GPU的AWS例項中,TAG和HOA之間的貨幣支出差異將為6144.48美元。類似地,TAG和CS在taskonomy上的效能是相等的,但是TAG的效率更高,計算任務組所需的teslav100 gpu小時少於140小時。總而言之,TAG對於確定哪些任務在訓練中可以協同訓練來說是一種有效的方法,該方法研究了任務如何透過訓練相互作用,特別是在一個任務上訓練時更新模型參數對網絡中其他任務遺失值的影響。
參考資料:
https:// ai.googleblog.com/2021/ 10/deciding-which-tasks-should-train.html











