你被Flappy Bird虐過麽?反擊的號角吹響了。
舒石 編譯整理
量子位·QbitAI 出品
作為一個曾經風靡一時的遊戲,【Flappy Bird】曾經虐過很多的人類玩家。而過去一段時間以來,好多人類借助AI技術把這款遊戲「玩壞了」。量子位粗略的數了一下,比較流行的有六大「門派」,特記錄如下,供有興趣的同學仿照操練。
姑且稱之: 【AI玩轉Flappy Bird全書】 ⁄(⁄ ⁄•⁄ω⁄•⁄ ⁄)⁄
目錄:
DQN大法(TensorFlow)
DQN大法(Keras)
強化學習
強化學習(改進版)
A3C大法
神經前進演化大法
DQN大法(TensorFlow)
 簡介
簡介
作者:yenchenlin(Yen-Chen Lin)
這個專案使用了DeepMind團隊在【Playing Atari with Deep Reinforcement Learning】論文中描述的Deep Q Learning演算法,表明這個演算法可以進一步推廣套用到【Flappy Bird】。
論文地址:[1312.5602] Playing Atari with Deep Reinforcement Learning
這裏所謂DQN(Deep Q-Network),是一個摺積神經網絡,用Q-Learning的變量訓練,其輸入是原始像素,其輸出是估計未來獎勵的價值函數。
安裝環境
Python 2.7或3
TensorFlow 0.7
pygame
OpenCV-Python
如何執行?
git clone https://github.com/yenchenlin1994/DeepLearningFlappyBird.git
DQN演算法
下面就是Deep Q Learning的偽代碼
Initialize replay memory D to size N
實驗
環境
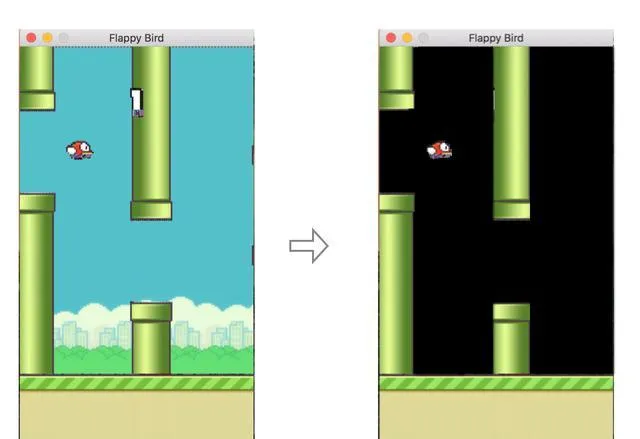
由於DQN基於遊戲螢幕上原始像素進行訓練,所以移除遊戲背景可以更快的收斂。
 網絡架構
網絡架構
首先對遊戲畫面進行如下幾步的處理:
-
將影像轉換為灰度
-
調整大小為80×80
-
堆疊最後4幀,可以產生80×80×4的輸入陣列
下圖就是網絡的架構。第一層對輸入的影像,用步長為4、尺寸為8×8×4×32的摺積核進行摺積。輸出接著透過一個2×2的Max Pooling層……全部過程如下圖所示,最後的隱藏層由256個全連線的ReLU節點構成。
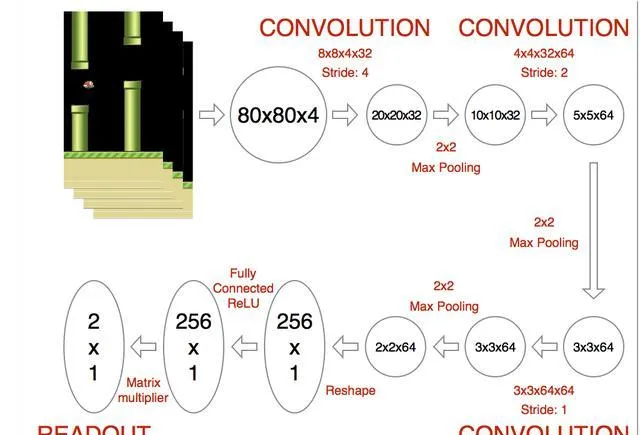 最終的輸出層的維度,和遊戲中的有效動作相同,其中第0個索引總是代表什麽也不做。輸出層的數值,代表每個有效動作輸入狀態的Q函數。每個時間步長裏,網絡使用ϵ greedy策略來執行對應最高Q值的動作。
最終的輸出層的維度,和遊戲中的有效動作相同,其中第0個索引總是代表什麽也不做。輸出層的數值,代表每個有效動作輸入狀態的Q函數。每個時間步長裏,網絡使用ϵ greedy策略來執行對應最高Q值的動作。
訓練
最開始,我使用標準偏差為0.01的正態分布隨機初始化所有權重矩陣,然後把replay memory的最大值設定為5萬次。隨後作者開始調整網絡,最後ϵ固定在0.001。
全部細節和程式碼,請存取如下網址:
yenchenlin/DeepLearningFlappyBird
DQN大法(Keras)
簡介
作者:Ben Lau
這個專案演示了如何使用Deep-Q Learning演算法與Keras,一起玩轉【Flappy Bird】。總共200行Python程式碼就搞定了。
安裝環境
Python 2.7
Keras 1.0
pygame
scikit-image
如何執行?
只用CPU/TensorFlow
git clone https://github.com/yanpanlau/Keras-FlappyBird.gitcd Keras-FlappyBird
python qlearn.py -m "Run"
GPU版本(Theano)
git clone https://github.com/yanpanlau/Keras-FlappyBird.gitcd Keras-FlappyBird
THEANO_FLAGS=device=gpu,floatX=float32,lib.cnmem=0.2 python qlearn.py -m "Run"
lib.cnmem=0.2意思是分配20%的GPU記憶體給程式
程式碼解讀
作者對程式碼有非常詳細的解讀,包括影像輸入和預處理,摺積神經網絡的構建,網絡權重和參數的調整,DQN演算法的解讀等等非常詳細。
 特別提示:最好有一個GPU加速計算。作者使用TITAN X,訓練了100萬次才有了收效。
特別提示:最好有一個GPU加速計算。作者使用TITAN X,訓練了100萬次才有了收效。
全部細節和程式碼,請存取如下網址:
Using Keras and Deep Q-Network to Play FlappyBird
強化學習
簡介
作者:SarvagyaVaish
玩過幾次【Flappy Bird】之後,我意識到可以用這個遊戲來搞機器學習。基本的思路是強化學習+Q Learning。下圖就是Q Learning的演算法。
 狀態空間
狀態空間
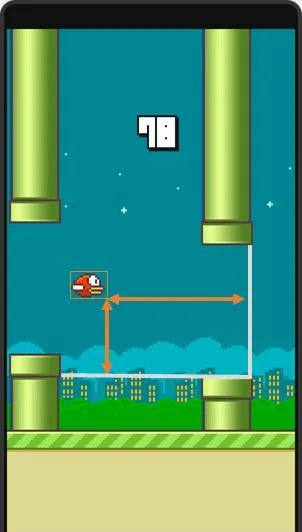
我用如下參數來描述空間,如圖所示:
從下方管子開始算起的垂直距離
從下一對管子算起的水平距離
鳥命:死或生
 動作
動作
每一個狀態,有兩個可能的動作
點選一下
啥也不幹
獎勵
獎勵的機制完全基於鳥命這個參數
+1,如果小鳥還活著
-1000,如果小鳥死了
迴圈學習
第一步:觀察Flappy Bird處於什麽狀態,並執行最大化預期獎勵的行動。然後繼續執行遊戲,接著獲得下一個狀態s’。
第二步:觀察新的狀態s’和與之相關的獎勵:+1或者-1000。
第三步:根據Q Learning規則更新Q陣列
Q[s,a] ← Q[s,a] + α (r + γ*V(s') - Q[s,a])
這裏alpha設定為0.7,因為我們有一個確定性的狀態。
第四步:設定當前狀態為s’,然後重新來過。
後續
大約花了6-7個小時,【Flappy Bird】才算訓練的比較好,得分能過150。如果開始的時候例項化不止一只小鳥,效率會有所提升。
全部細節和程式碼,請存取如下網址:
Flappy Bird RL by SarvagyaVaish
強化學習(改進版)
 簡介
簡介
作者:chncyhn
每次玩遊戲的時候,Python攜程的機器人會觀察小鳥所處的狀態,以及所采取的行動。基於行動的結果,會得到獎勵或者懲罰的反饋。如是反復,終獲高分。
這個專案深受上面sarvagyavaish成果的影響,但在狀態空間和演算法上有所改進。
狀態空間
我定義了狀態空間和動作集,根據小鳥在遊戲中的表現,對狀態-動作的對應關系進行獎勵。
我定義的狀態和sarvagyavaish有點不同。如上所述,他用於下一個管道的水平糊垂直距離定義了狀態,但我發現這樣的話,收斂需要很長的時間。所以,我把距離離散成10×10的網格,這極大的減少了狀態空間。此外,我還在狀態空間中增加了小鳥的垂直速度。
演算法也做了一點改變,不再每次觀察後更新Q值,而是每次遊戲結束時進行後向。所以Q值會從最後一個動作反向加到第一個。我認為這有助於更快的傳播「壞狀態」。另外,如果小鳥觸到管道的頂部而掛掉的話,這個狀態會被額外的懲罰。
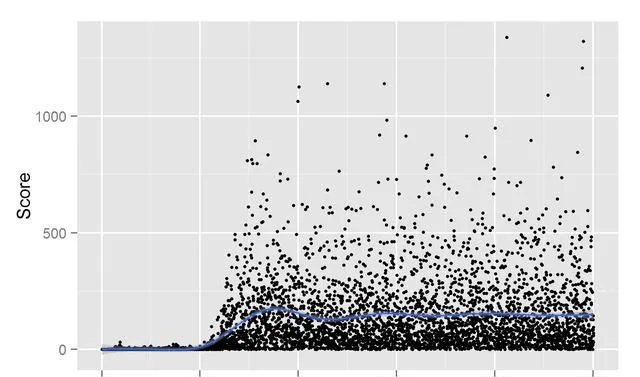 可以看到,大約在1500次遊戲叠代之後,機器已經玩得很好,平均大約150分,並且偶爾可以得到很高的分數。
可以看到,大約在1500次遊戲叠代之後,機器已經玩得很好,平均大約150分,並且偶爾可以得到很高的分數。
更新
 使用5×5網格取代10×10之後,收斂花費了更長的時間,但總分可以到675左右,明顯比之前的150分高,而且好幾次到了3000多分。
使用5×5網格取代10×10之後,收斂花費了更長的時間,但總分可以到675左右,明顯比之前的150分高,而且好幾次到了3000多分。
全部細節和程式碼,請存取如下網址:
chncyhn/flappybird-qlearning-bot
A3C大法
 簡介
簡介
作者:babaktr
這是一個嘗試使用異步評價器演算法(Asynchronous Advantage Actor-Critic,A3C),來訓練人工智能代理玩【Flappy Bird】的案例。
設定
作者詳細介紹了部份參數的設定情況。例如:
代理設定
mode / [train, display, visualize] - 模式設定
use_gpu / [True, False] - 是否啟用GPU加速訓練
parallel_agent_size - 訓練中並列的代理數量
訓練和最佳化設定
max_time_step - 40 000 000 - 最大訓練步長
gamma - 0.99 - 獎勵的折扣系數
entropy_beta - 0.01 - 熵正則化常數
以預設參數啟動訓練,執行:
$ python a3c.py
如果想檢查進度,以及即時比較不同的實驗,可以進入async-deep-flappybird資料夾,並且執行tensorboard:
$ tensorboard --logdir summaries/
全部細節和程式碼,請存取如下網址:
babaktr/async-deep-flappybird
神經前進演化大法
簡介
作者:xviniette
為了理解這個方法,讓我們先談談達爾文的前進演化理論。核心是三個要素:
-
變化
-
選擇
-
遺傳
這個方法完全基於這個理論。首先,隨機生成50只小鳥,小鳥被賦予跳躍的能力,但它們不知道什麽時候該跳,也不知道應該跳多高。
小鳥試圖隨機跳躍求生,但是很少能夠做到,尤其在最初幾代。每一代後,新的小鳥被建立,但這一次不是隨機生成,而是透過演算法「選擇」那些飛的更久的小鳥作為「父母」。新的小鳥遺傳了上一代的資訊,然後重新生成50只小鳥。
在這個過程中,每一代小鳥都不斷前進演化以適應生存。
Demo
幹說不如直接看Demo,可以透過按鈕選擇模擬的速度。Demo地址:
NeuroEvolution : Flappy Bird
 神經前進演化的程式碼
神經前進演化的程式碼
// Initialize
評價
這個案例在Hacker News上引發廣泛的討論。有人說這就是所謂的「用這麽一點程式碼就搞定了?!」,並且推這個方式推崇備至。不過也有使用者在復制這個方法後,沒有得到穩定的結果。
全部細節和程式碼,請存取如下網址:
xviniette/FlappyLearning
另外:
同樣的方法,其實也用在金融領域。例如,用前進演化的方法訓練機器炒股。在量子位微信公眾號( ID:QbitAI )對話界面回復:「炒股」兩個字,我們帶您解密一支完全由人工智能管理的基金。
以及,今天AI還搞了哪些大新聞?在量子位(QbitAI)公眾號會話界面回復「今天」,看我們全網搜羅的AI新鮮資訊。比心 ❤ ~











