在這篇文章中,Jeff Dean 等人工智能大牛描繪了一幅機器學習在醫療領域的套用藍圖。
先來看兩個場景:
場景 1:
一名 49 歲的病人註意到肩膀上起了皮疹,因為不覺得疼痛,所以也沒有尋求治療。幾個月之後,他的妻子讓他去看醫生,醫生診斷出他患了脂溢性角化癥。後來,當該患者在做腸鏡篩查時,護士註意到他的肩膀上有黑色斑點,於是建議他去檢查一下。又過了一個月,這位患者去看皮膚科醫生,醫生從病變的地方取了一些活檢樣本。結果顯示這是一種非癌性色素沈澱病變。醫生還是很擔心,建議二次檢測活檢樣本,最終診斷出了侵襲性黑色素瘤。之後,腫瘤科醫生用全身化療的方法治療這位患者。一位醫生朋友問病人為什麽不接受免疫治療。
場景 2:
一名 49 歲的病人用手機 app 拍了一張肩膀上皮疹的照片,app 建議他立即預約皮膚科醫生。他的保險公司自動批準直接轉診,app 幫他在兩天內預約了附近一名經驗豐富的皮膚科醫生,該預約和患者的個人行程自動交叉核對過了。皮膚科醫生對病變處進行了活檢,病理學家在電腦輔助下診斷出 Ⅰ 期黑色素瘤,然後皮膚科醫生進行了摘除手術。
對比場景 1 和場景 2,我們可以發現,在同樣的一個病例中,場景 2 的醫療流程實作了以下最佳化:1)患者可以直接用手機拍攝病變照片,由 app 進行初級診斷,系統可以根據 app 提供的建議合理分配醫療資源;2)皮膚科醫生和病理學家實作了有效的協作,相當於讓一位普通病人也得到了專家會診,提高了診斷和治療方法的準確性。這就是 Jeff Dean 等人為我們描繪的機器學習在醫療領域的套用藍圖。
如果重癥監護人員或社區醫療人員每做出一個醫療決定,立刻就會有相關領域的專家組成的團隊對這條決定進行審查,判斷這條決定是否正確並對其進行指導,那會是什麽樣呢?最新診斷出沒有並行癥的高血壓患者將會接受現有最有效也最對癥的治療,而不是診斷者最熟悉的治療方法。這樣可以很大程度上消除用藥過量和處方錯誤的問題。患有神秘且罕見疾病的患者可以直接由相關領域的知名專家會診。
這樣的系統似乎離我們很遠。因為沒有足夠的專家可以配合這樣的系統。就算有,對專家們來說,不僅要花很長時間了解患者的病史,而且與私密相關的問題可能也會成為阻礙。但這就是用於醫療領域的機器學習的前景——幾乎所有臨床醫生所做的診斷決定以及數十億患者的診斷結果組成的智慧結晶應該為每一位患者的醫療護理提供指導。也就是說,應該根據患者所有已知的即時資訊和集體經驗得出個人化的診斷、管理決策以及治療方案。
這種框架強調機器學習不僅是像新藥或者新的醫療器械這樣全新的工具,而是一種基礎技術,這種技術可以高效處理超出人類大腦負荷的數據。這種巨大的資訊儲存涉及到龐大的臨床數據庫,甚至單個患者的數據。
50 年前的一篇專題文章指出,計算將「強化,在有些情況下可以很大程度上取代醫生的智慧」。但到 2019 年初,由機器學習驅動的醫療保健幾乎還沒有取得什麽進展。我們在此不再贅述之前報道過的無數透過測試的概念驗證模型(回顧性數據),而是要說一些醫療健康領域的核心結構變化及範式轉變,這對於實作機器學習在醫療領域的前景來說是必需的。
機器學習解釋
傳統上講,軟件工程師透過清晰的電腦程式碼形式提取知識,從而指導電腦如何處理數據並做出正確的決策。例如,如果病人血壓升高,而且沒有接受抗高血壓藥物的治療,那正確編程的電腦可以提出治療建議。這類基於規則的系統具有邏輯性和可解釋性,但正如 1987 年的一篇文章中所說,醫療領域「太過廣泛也太過復雜,因此難以(如果可能的話)在規則中捕獲相關資訊」。
傳統方法和機器學習之間的關鍵區別在於,在機器學習中,模型是從樣本中學習而不是按規則編程的。對於給定任務,樣本給定輸入(特征)和輸出(標簽)。例如,將病理學家讀取的數碼化切片轉換為特征(切片像素)和標簽(上面的資訊表明切片是否包含指示癌變的證據)。用演算法從觀測值中學習,然後電腦決定如何從特征對映到標簽,從而建立泛化模型,這樣就可以在未曾見過的輸入上正確執行新任務(例如,從未被人讀取過的病理學切片)。圖 1 總結了這一過程,這就是所謂的有監督的機器學習。還有其他形式的機器學習。表 1 列出了用於臨床的案例,這些模型的輸入輸出對映基本上都是基於同行評審研究或現有機器學習的擴充套件。
圖 1:有監督機器學習的概念性概述
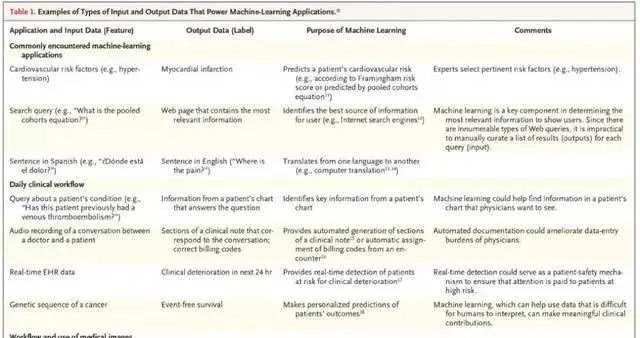


表 1:推動機器學習套用的輸入數據和輸出數據類別範例。
在實際套用中,預測準確性至關重要,模型在數百萬特征和樣例中找出統計模式的能力絕對可以超過人類的表現。但這些模式不一定適應基本的生物學鑒定方式,也不一定能辨識支持新療法的開發過程中可修改的危險因素。
機器學習模型和傳統的統計模型之間並非涇渭分明,最近有一篇文章總結了這兩者之間的關系。但復雜的新型機器學習模型(比如「深度學習」(一種利用人工神經網絡的機器學習演算法,它可以學習到特征和標簽之間極其復雜的關系,在諸如影像分類等任務上的表現已經超越了人類))很適合學習現代臨床病例中產生的復雜、異構數據(比如醫生寫的醫療記錄、醫學影像、來自傳感器的連續監控數據以及基因組數據),從而做出醫學相關的預測。表 2 提供了簡單和復雜的機器學習模型分別適用於什麽樣的情況。

表 2:決定要用哪種模型時要問的關鍵問題。
人類學習和機器學習之間的關鍵區別在於人類可以從少量數據中得到普適且復雜的關系。例如,小孩不用看太多樣本就能區分獵豹和貓。在學習相同任務的情況下,和人相比機器需要更多的樣本,而且機器不具備常識。但從另一個角度上講,機器可以從大量數據中學習。用數千萬患者儲存在 EHR(Electronic Health Records,電子健康記錄)中的數據來訓練機器學習模型是完全可行的,這些數千億的數據點完全沒有任何重點,而人類醫生在整個職業生涯中都很難接診數萬名患者。
機器學習對臨床醫生的工作有何幫助
預後
機器學習模型可以學習患者的健康軌跡模式。它可以得到超出醫生個體經驗的資訊,幫助醫生以專家水平預測出未來可能發生的事件。例如,患者重返工作崗位的概率有多大?疾病發展的速度會有多快?相同類別的預測可以在眾多患者中可靠地辨識出將出現高危情況或可能頻繁需要醫療護理的患者,這些資訊可以作為附加資訊幫助醫生。
大型綜合衛生系統已經在用簡單的機器學習模型了,它可以自動辨識可能需要轉移到重癥監護室的住院患者,回溯性研究表明,可以用 EHR 和醫學影像中的原始數據建立更復雜也更準確的預後模型。
構建機器學習系統需要用患者的縱向整合數據進行訓練。只有當訓練模型的數據集中包含結果時,模型才能學習到患者的情況。但數據現在都是獨立儲存在 EHR 系統、醫學影像存檔和互動系統、付款人、PBM(Pharmacy Benefits Managers,藥品福利管理)甚至患者手機上的套用中的。自然的解決方案是將數據系統交到患者自己手中,這也是我們長期以來一直倡導的解決方案,現在這一想法也已經透過快速采用患者控制的應用程式編程介面得以實作。
像 FHIR(Fast Healthcare Interoperability Resources,快速醫療互操作性資源)這樣將數據轉化為統一格式可以更有效地聚合數據。患者可以決定哪些人可以用他們的數據來構建或執行模型。盡管有人擔心技術的互操作性無法解決 EHR 數據中普遍存在的語意標準化問題,但 HTML(Hypertext Markup Language,超文件標示語言)可以索引 Web 數據,還可以用在搜尋引擎上。
診斷
每一位患者都是獨一無二的,但最好的醫生可以在正常範圍內確定患者特有的微弱訊號或異常值。可以用機器學習檢測出的統計模式幫助醫生辨識診斷不到的病癥嗎?
醫學研究所的結論是,幾乎每一位患者在他(她)的一生中都會遇到一次誤診,而正確的診斷是采用合適治療方法的基礎。這個問題不止在一些罕見的病癥中會出現。在發展中國家,即便有充足的治療手段、檢查時間和培訓充分的醫護人員,也無法檢查出急性胸痛、肺結核、痢疾以及分娩期間的並行癥。
常規醫療護理期間收集到的數據表明,可以在臨床診斷中用機器學習來判斷可能的診斷,這樣可以提高對以後可能出現的情況的認識。但這樣的方法有局限性。生疏的臨床醫生可能無法正確提取模型必需的資訊,因而無法讓模型變得有意義。模型得到的結果可能建立在臨時或錯誤的診斷之上,可能建立在不能證明是病癥的不良反應條件之上(從而造成過度診斷),可能受計費的影響,或者可能根本沒有記錄。但模型會根據這些即時收集的數據給醫生提出建議,這些建議在誤診率很高和臨床醫生不確定的情況中是很有用的。在臨床上正確的診斷和 EHR 中或報銷索賠中的記錄的不一致意味著臨床醫生應該從一開始就參與到產生數據的過程中來,這些數據會作為常規護理的一部份,而且之後還會用於自動診斷過程。
訓練成功的模型可以回溯辨識各種影像類別的異常(表 1)。但將機器學習模型作為臨床醫生常規工作一部份的回溯試驗的數量非常有限。
治療
在數萬名醫生要治療數千萬患者的大型醫療系統中,患者在什麽時候為什麽就診以及情況相似的患者應該如何治療都是有差異的。模型是否可以對這些差異進行分類,從而幫助醫生確定首選治療途徑?
一個比較簡單的套用是比較定點照護(point of care)的處方和模型得到的處方,可以將差異標記出來後再次核查(例如,其他臨床醫生傾向於使用可以反映新方法的替代療法)。基於歷史數據訓練的模型只能學習醫生的處方習慣,但這並不一定是理想做法。為了了解療效最好的藥物和治療方法,需要精心收集數據並評估因果效應,而機器學習模型則不一定能(有時候也不能用給定的數據集)辨識這些效應。
根據觀察數據比較療效研究和實用性實驗的傳統方法也提供了重要看法。但近期使用機器學習方法的試驗表明,和專家一起生成人工篩查過的數據集、更新模型以納入新發表的數據、根據不同領域的處方進行調整以及從 EHR 中自動提取相關變量都是很大的挑戰。
還可以用機器學習自動選擇患者,根據臨床記錄,這些患者可能適合進行隨機對照試驗;或者可以用機器學習自動辨識可能用早期研究或新療法治愈的高風險患者或亞群。這些工具促使醫療健康系統研究每一種臨床情況,可以在降低成本和管理費用的同時進行更嚴格的研究。
臨床工作流程
EHR 的引入提高了數據的可用性。但這些系統也因費用過高、管理文件的核取方塊過多、使用者介面不夠友好、輸入數據花費的時間過長以及產生新的醫療錯誤等讓臨床醫生們灰頭土臉。
也可以將機器學習技術用在其他消費產品中以提高臨床醫生們的效率。驅動搜尋引擎的機器學習可以在無需臨床醫生多次點選的情況下找出患者數據的相關資訊。用機器學習技術(如預測類別、語音聽寫和自動摘要等)可以大大改進表格和文本數據的輸入。根據患者表格中的資訊自動授權支付的模型可以取代提前授權。使用這些工具不僅僅只是為了方便醫生。無障礙地檢視和輸入臨床上的有效數據對捕獲和記錄醫療健康數據來說至關重要,這反過來也可以在機器學習的輔助下為每一位患者提供最好的醫療護理幫助。最重要的是,這種做法提高了效率、簡化了記錄,而且改進了自動化臨床工作流程,這樣臨床醫生就可以把更多的時間花在患者身上。
在 EHR 系統之外,機器學習技術也可以用於外科手術的即時影片分析,可以幫助外科醫生避免在關鍵結構解剖時出現問題或者患者身體有意料之外的改變,甚至可以處理更普通的任務——比如準確計算手術海綿的數量。檢查清單(checklist)可以避免手術錯誤,還可以自動監控手術過程,提高手術的安全性。
在臨床醫生的個人生活中,他們可能在自己的智能電話上用到了所有這些技術的變體。盡管有將這些技術套用於醫學背景的概念驗證的研究,但主要的障礙不是模型的開發,而是技術的基礎設施——EHR 之上的法律、私密和政策框架、衛生系統以及技術供應商。
擴大臨床專業知識的可用性
醫生不可能照料到所有需要治療的患者。機器學習是否可以在不需要醫生親自參與的情況下,擴大醫生診治範圍、提供專家級醫療評估呢?例如,剛剛發皮疹的患者可能只要用手機發送一張照片就可以獲得診斷,從而避免掛不必要的急診。本身要去急診室就診的患者可能在自動診斷系統就能獲得診斷,並在適當的時候以另一種形式進行護理。當患者確實需要專業幫助時,模型也可以辨識出專業最相關且處於空閑狀態的醫生。同樣,為了提高舒適度並降低成本,如果機器可以遠端監控病人的傳感器數據,本身需要住院治療的病人就可以在家裏接受護理了。
世界上有一些地區,直接學習醫學專業知識的渠道有限,而且非常復雜,因而將機器學習的真知灼見直接傳遞給病人變得越來越重要。即便是在那些專家醫生充足的區域,這些醫生擔心他們的能力和努力無法及時且準確地解釋那些浪潮一般的數據,這些數據一般是從患者穿戴的傳感器或活動追蹤器材中得到的,並且由患者自己驅動。事實上,用數百萬患者的數據訓練得到的機器學習模型可以幫助專業醫護人士做出更好的決策。例如,護士可以承擔通常由醫生完成的醫療工作,初級護理醫生則可以承擔通常由醫療專家完成的工作,而醫療專家則可以將更多的時間投入到非常需要他們專業知識的病人身上。
不涉及機器學習的流動應用或網絡服務已被證明可以改善藥物的依賴性,還可以控制各種慢性病。但正式的回顧性和前瞻性評估方法阻礙了患者直接套用機器學習。
主要挑戰
高質素數據的可用性
構建機器學習模型的核心挑戰在於組裝具有代表性的多樣化數據集。理想做法是在使用過程中利用最接近期望數據準確格式和質素的數據來訓練模型。例如,對於打算用在即時護理中的模型而言,最好使用 EHR 在特定情況下所用的同一數據,即便已知這些數據不可靠或這些數據受到了不必要變化的影響。當數據集足夠大時,現代模型可以成功被訓練,以將嘈雜輸入對映到嘈雜輸出。使用人工篩查數據(比如那些在臨床試驗中從人工病例審查得到的數據)得到的更小數據集就不太理想,除非希望醫生根據原始實驗規範手動提取變量。這種做法對某些變量來說或特許行,但對於做出最準確預測所必需的、EHR 中數十萬的數據而言就太不可行了。
俗話說「垃圾進,垃圾出」(garbage in, garbage out),那麽我們如何協調雜訊數據集來訓練模型呢?要學習大多數復雜的統計模式最好還是有大數據集(哪怕是雜訊數據),以便對模型進行微調和評估,但具有人工篩查標簽的更小樣例集還是有必要的。當原始數據可能標記錯誤時,這種樣例集可以就模型對預期標簽的預測做出正確的評估。對成像模型來說,這通常需要生成由每張圖片的多個評分器判定的「ground truth」標簽(即由一位絕對可靠的專家指定給一個樣例的診斷或發現),但對非成像任務來說,如果沒能獲得必要的診斷測試,那可能也無法獲得「ground truth」標簽。
一般情況下,訓練數據越多機器學習模型表現得越好。因此,對於機器學習的使用而言,一個關鍵的問題是在利用大且多樣化數據集以提高機器學習模型準確率的同時,需要平衡私密問題和監管要求。
從過去的失敗經驗中學習
人類的所有活動都會被意料之外的偏差破壞。機器學習系統的構建者和使用者需要仔細考慮偏差如何影響用於訓練模型的數據,並采取措施解決和監控這些偏差。
機器學習的優勢(也是劣勢之一)在於模型可以辨識到人類無法找到的歷史數據模式。醫療實踐的歷史數據表明,人們能得到的系統性醫療護理是存在差異的,一般為弱勢群體提供的醫療護理較其他群體更差一些。在美國,歷史數據反映了一種支付系統,該系統會獎勵使用不必要護理和服務的人,這樣可能會錯過那些本該卻並未得到護理的病人(比如沒有保險的患者)。
監管、監督和安全使用的專業知識
衛生系統已經建立了可以確保將藥物安全傳遞到患者手上的復雜機制。機器學習的廣泛適用性也需要同樣復雜的監管結構、法律框架以及當地實踐以確保系統的安全開發、使用和監管。此外,技術公司必須要提供可延伸的計算平台來處理大量數據和模型使用的問題,但到現在他們也不清楚自己的定位。
重要的是,使用機器學習系統的醫生和病人都需要理解其局限性,包括模型並不能泛化到特定場景。做決策或分析影像時過度依賴機器學習模型可能會導致自動化偏差,而醫生可能已經降低其對這些偏差的警惕。如果模型的可解釋性不夠強,醫生可能意識不到模型給出了錯誤的建議,這時尤其會出現問題。在模型預測中表現出置信區間可能有所幫助,但置信區間本身或許被錯誤解釋。因此,需要對使用中的模型進行前瞻性的、真實的臨床評估,而不只是根據歷史數據集對模型效能做回顧性評估。
需要特別考慮直接針對患者的機器學習套用。患者可能無法驗證模型構建者所說的話是否得到高質素臨床證據的證實,也無法驗證模型建議的行為是否合理。
研究結果的出版與傳播
構建模型的跨學科團隊可能會在臨床醫生不熟悉的場所匯報結果。稿件通常會在 arXiv 和 bioRxiv 這樣的預印本服務網站上釋出,許多模型的原始碼則會在 GitHub 庫這樣的地方保存。此外,許多同行評審的電腦科學稿件也並不會釋出在傳統期刊上,而會發表在 NeurIPS(神經資訊處理系統大會)和 ICML(國際機器學習大會)這樣的會議上。
結論
大量衛生保健數據的加速建立將從根本上改變醫療保健的性質。我們堅信,醫患關系將成為為患者提供醫療服務的基石,而這種關系會因機器學習的輔助而變得豐富。我們期望在未來幾年會出現一些早期模型和同行評審的刊物,它們的出現以及監管框架和基於價值醫療的經濟激勵的發展,都會成為對醫療領域套用機器學習保持樂觀態度的理由。我們期望在不遠的未來,數百萬臨床醫生在護理數十億患者時,可以在機器學習模型的幫助下根據所有醫學相關數據做出決策,從而為所有患者提供最好的護理方案。





