我來貢獻一點幹貨和八卦~
AlphaGo的第一作者David Silver還在MIT做post-doc的時候(也有可能是visit?),曾經和我們組師兄合作利用機器學習和蒙特卡羅樹搜尋玩【文明2】。當時也有不小的轟動:
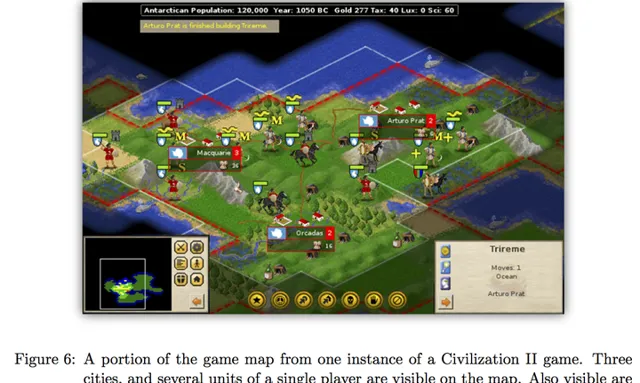
有興趣的同學可以參考專案主頁和論文
[1][2]。可以翻墻youtube的同學還可以看到一段遊戲影片。
作為其他答案的補充,下面淺顯地針對性地介紹一下蒙特卡羅樹搜尋(MCTS)。
(***本文圖片來源DeepMind和師兄論文)
一、為什麽要用搜尋?
-------
由於 狀態數有限 和 不存在隨機性 ,象棋和五子棋這類遊戲 理論上 可以由終局自底向上的推算出每一個局面的勝負情況,從而得到最優策略。例如五子棋就被驗證為先手必勝
[3]。
遺憾的是,由於大部份博弈遊戲狀態空間巨大(圍棋約為2\times 10^{170} ), 嚴格計算評估函數是辦不到的 。於是人們設計了 (啟發式的) 搜尋演算法 ,一句話概括如下:
由當前局面開始,嘗試 看起來可靠的行動 ,達到終局或一定步數後停止,根據後續 局面的優劣 反饋,選擇最優行動。通俗的說就是「手下一著子,心想三步棋」、「三思而後行」的意思。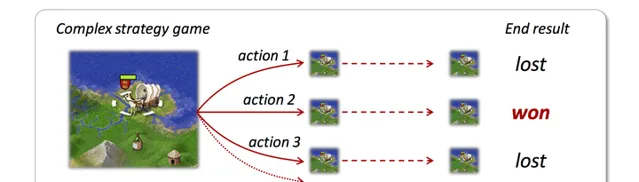
二、哪些是「看起來可靠」的行動?怎麽評價局面的優劣?
-------
這裏就要引入遊戲論和強化學習裏面的概念了。在數學上,「最優策略」和「局面判斷」可以被量化成為函數Q\left( s, a \right) ,V(s) 。這裏s 表示局面狀態,a 表示下一步(走子)行動。在強化學習裏,兩者被稱為 策略函數(policy function) 和 局面函數(value function),前者衡量在局面s 下執行a 能帶來的價值,後者衡量某一局面s 的價值,越大的值表示對當前行動的選手越有利。
Q和V函數是對我們所謂的「棋感」和「大局觀」的量化 。有了這兩個估值函數,在搜尋的時候我們盡量選擇估值更大的行動,達到縮小思考範圍(減少搜尋分支)的目的。同時即使在未達到終局的情況下,我們也可以依靠局面函數對當前局勢優劣做判斷。
那麽如何得到精確的估值函數就很重要了。 由於不能透過列舉狀態空間來精確計算Q和V,傳統的做法是人為的設計估值。例如五子棋的局面可以依靠計算「三連」、「四連」等特征的數量乘以相應的分值來估算。這裏就涉及到辨識特征和衡量特征分值兩個問題。對於更加復雜的遊戲(例如文明、圍棋等),現代的做法是利用機器學習和大量數據, 自動的找到特征,同時擬合出估值函數。 AlphaGo利用深度學習達到了該目的。
三、蒙地卡羅樹搜尋(MCTS)
-------
蒙地卡羅樹搜尋是集以上技術於一身的搜尋框架,透過反復模擬和采樣對局過程(稱為 Rollout )來探索狀態空間。可以看出它的特點是 非常容易並列 、可任何時候停止(時間和收益上的平衡)、引入了 隨機性采樣 而減小估值錯誤帶來的負面影響,並且可以在隨機探索的過程中,結合強化學習(Reinforcement Learning), 「自學」式的調整估值函數 ,讓演算法越來越聰明。直觀一點的圖示如下:
(a) 從當前狀態(帶有隨機性)的模擬對局,該過程可以並列:
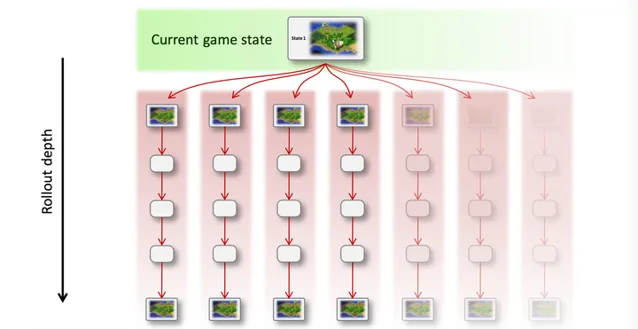
(b) 透過采樣和估值結果,選擇最優行動,並重復執行這個過程:
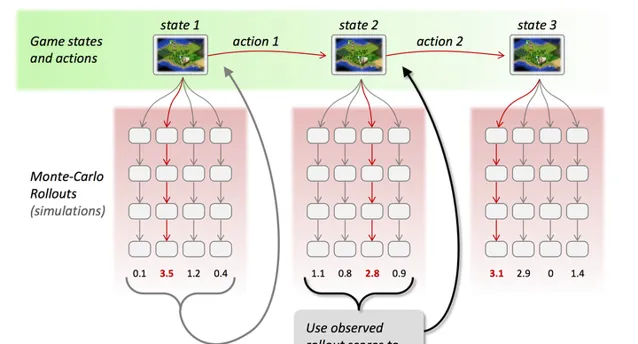
(c) 如果選擇強化學習,則根據結果更新估值函數的參數
有興趣的同學可以閱讀AlphaGo或其他相關論文。
四、總結
-------
AlphaGo結合了3大塊技術:先進的搜尋演算法、機器學習演算法(即強化學習),以及深度神經網絡。這三者的關系大致可以理解為:
這些都不是AlphaGo或者DeepMind團隊首創的技術。但是強大的團隊將這些結合在一起,配合Google公司強大的計算資源,成就了歷史性的飛躍。
一些個人見解:MCTS 、RL 和 DNN這三者,前兩者讓具有自學能力、並列的博弈演算法成為可能,後者讓「量化評估圍棋局面」成為了可能(這個
@田淵棟大神的
貼文裏已經解釋了)。
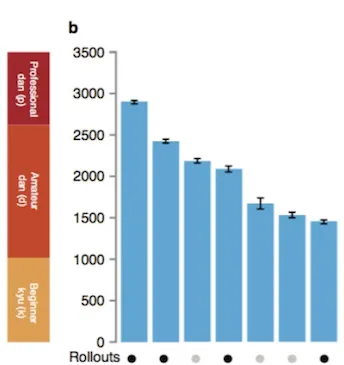
對於AlphaGo來說,這每一個模組都是必要的,DeepMind論文中已經展示了各個模組對於棋力的影響:
五、RL / MCTS 的其他套用
-------
除了最開始提到的【文明2】遊戲和圍棋,MCTS和RL還可以套用到各種博弈、遊戲場景下。因為評論裏有不少討論,這裏增加幾個有意思的幹貨:
其他小八卦
參考文獻
-------
[1]
Learning to Win by Reading Manuals in a Monte-Carlo Framework[2]
http://www. jair.org/media/3484/liv e-3484-6254-jair.pdf[3]
wikipedia.org 的頁面[4]
http:// nlp.cs.berkeley.edu/pub s/Burkett-Hall-Klein_2011_IMBA_paper.pdf[5]
http://www. nature.com/nature/journ al/v518/n7540/full/nature14236.html










