谷歌DeepMind宣布他們研發的神經網絡圍棋AI,AlphaGo,在2015年10月首次5:0戰勝了人類職業選手歐洲圍棋冠軍Fan Hui二段。這篇論文由David Silver等完成。裏面的技術是出於意料的簡單卻又強大。為了方便不熟悉技術的小白理解,這裏是我對系統工作原理的解讀。下面主要編譯與:
How AlphaGo Works ,原作者是
SpinPunch CTO DAN MAAS。本文正選微信公眾號「
董老師在矽谷
」(donglaoshi-123)
深度學習

「深度學習」是指多層的人工神經網絡和訓練它的方法。一層神經網絡把大量矩陣數據作為輸入,透過非線性啟用方法取權重,再產生另一個數據集合作為輸出。這就像生物神經大腦的工作機理一樣,透過合適的矩陣數量,多層組織連結一起,形成神經網絡「大腦」進行精準復雜的處理,就像人們辨識物體標註圖片一樣。
雖然神經網絡在幾十年前就有了,直到最近才形勢明朗。這是因為他們需要大量的「訓練」去發現矩陣中的數碼價值。對早期研究者來說,想要獲得不錯效果的最小量訓練都遠遠超過計算能力和能提供的數據的大小。但最近幾年,一些能獲取海量資源的團隊重現挖掘神經網絡,就是透過「大數據」技術來高效訓練。
兩個大腦
AlphaGo是透過兩個不同神經網絡「大腦」合作來改進下棋。這些大腦是多層神經網絡跟那些Google圖片搜尋引擎辨識圖片在結構上是相似的。它們從多層啟發式二維過濾器開始,去處理圍棋棋盤的定位,就像圖片分類器網絡處理圖片一樣。經過過濾,13 個完全連線的神經網絡層產生對它們看到的局面判斷。這些層能夠做分類和邏輯推理。
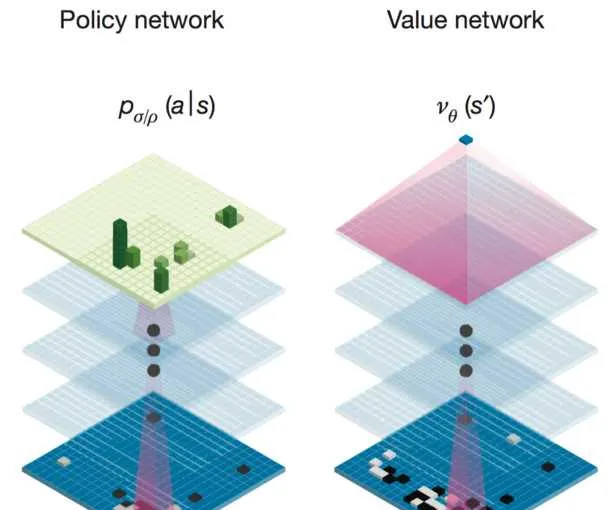
這些網絡透過反復訓練來檢查結果,再去校對調整參數,去讓下次執行更好。這個處理器有大量的隨機性元素,所以我們是不可能精確知道網絡是如何「思考」的,但更多的訓練後能讓它前進演化到更好。
第一大腦: 落子選擇器 (Move Picker)
AlphaGo的第一個神經網絡大腦是「監督學習的策略網絡(Policy Network)」 ,觀察棋盤布局企圖找到最佳的下一步。事實上,它預測每一個合法下一步的最佳概率,那麽最前面猜測的就是那個概率最高的。你可以理解成「落子選擇器」。
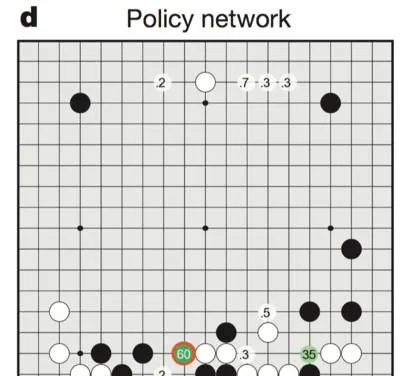 落子選擇器是怎麽看到棋盤的?數碼表示最強人類選手會下在哪些地方的可能。
落子選擇器是怎麽看到棋盤的?數碼表示最強人類選手會下在哪些地方的可能。
團隊透過在KGS(網絡圍棋對戰平台)上最強人類對手,百萬級的對弈落子去訓練大腦。這就是AlphaGo最像人的地方,目標是去學習那些頂尖高手的妙手。這個不是為了去下贏,而是去找一個跟人類高手同樣的下一步落子。AlphaGo落子選擇器能正確符合57%的人類高手。(不符合的不是意味著錯誤,有可能人類自己犯的失誤)
更強的落子選擇器
AlphaGo系統其實需要兩個額外落子選擇器「大腦」。一個是「強化學習的策略網絡(Policy Network)」,透過百萬級別模擬對局來完成。姑且稱之為更強的選擇器。對比基本的訓練,那只是教網絡去模仿單一的人類落子,高級訓練會與每一個模擬棋局下到底,教網絡最可能贏的下一手。Sliver團隊透過更強的落子選擇器總結了百萬級訓練棋局,比他們之前版本又更新改進了不少。
如果就只用這種落子選擇器已經是強大的對手了,可以到業余棋手的水平,或者說跟之前最強的圍棋AI媲美。這裏重點是這種落子選擇器不會去「讀」。它就是簡單審視從單一棋盤位置,再提出從那個位置分析出來的落子。它不會去模擬任何未來的走法,展示了樸素的深度神經網絡學習的力量。
更快的落子選擇器
AlphaGo當然團隊沒有在這裏止步。下面我會闡述是如何將閱讀能力賦予AI的。為了做到這一點,他們需要更快版本的落子選擇器大腦。越強的版本在耗時上越久-為了產生一個不錯的落子也足夠快了,但「閱讀結構」需要去檢查幾千種落子可能性才能做決定。
Silver團隊建立簡單的落子選擇器去做出「快速閱讀」的版本,他們稱之為「捲動網絡」。簡單版本是不會看整個19*19的棋盤,但會在對手之前下的和新下的棋子中考慮,觀察一個更小的視窗。去掉部份落子選擇器大腦會損失一些實力,但輕量級版本能夠比之前快1000倍,這讓「閱讀結構」成了可能。
第二大腦:棋局評估器 (Position Evaluator)
AlphaGo的第二個大腦相對於落子選擇器是回答另一個問題。不是去猜測具體下一步,它預測每一個棋手贏棋的可能,在給定棋子位置情況下。這「局面評估器」就是論文中提到的「價值網絡(Value Network)」,透過整體局面判斷來輔助落子選擇器。這個判斷僅僅是大概的,但對於閱讀速度提高很有幫助。透過分類潛在的未來局面的「好」與「壞」,AlphaGo能夠決定是否透過特殊變種去深入閱讀。如果局面評估器說這個特殊變種不行,那麽AI就跳過閱讀在這一條線上的任何更多落子。

局面評估器是怎麽看這個棋盤的。深藍色表示下一步有利於贏棋的位置。
局面評估器也透過百萬級別的棋局做訓練。Silver團隊透過 復制兩個AlphaGo的最強落子選擇器,精心挑選隨機樣本創造了這些局面。這裏AI 落子選擇器在高效建立大規模數據集去訓練局面評估器是非常有價值的。這種落子選擇器讓大家去模擬繼續往下走的很多可能,從任意給定棋盤局面去猜測大致的雙方贏棋概率。而人類的棋局還不夠多恐怕難以完成這種訓練。
增加閱讀
這裏做了三個版本的落子選擇大腦,加上局面評估大腦,AlphaGo可以有效去閱讀未來走法和步驟了。閱讀跟大多數圍棋AI一樣,透過蒙地卡羅樹搜尋(MCTS)演算法來完成。但AlphaGo 比其他AI都要聰明,能夠更加智能的猜測哪個變種去探測,需要多深去探測。
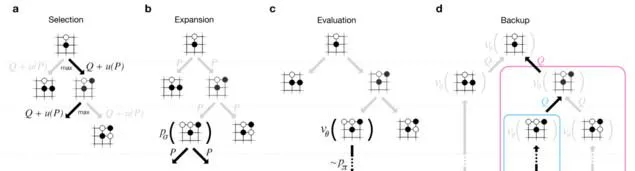
蒙地卡羅樹搜尋演算法
如果擁有無限的計算能力,MCTS可以理論上去計算最佳落子透過探索每一局的可能步驟。但未來走法的搜尋空間對於圍棋來說太大了(大到比我們認知宇宙裏的粒子還多),實際上AI沒有辦法探索每一個可能的變種。MCTS做法比其他AI有多好的原因是在辨識有利的變種,這樣可以跳過一些不利的。
Silver團隊讓AlphaGo裝上MCTS系統的模組,這種框架讓設計者去嵌入不同的功能去評估變種。最後馬力全開的AlphaGo系統按如下方式使用了所有這些大腦。
1. 從當前的棋盤布局,選擇哪些下一步的可能性。他們用基礎的落子選擇器大腦(他們嘗試使用更強的版本,但事實上讓AlphaGo更弱,因為這沒有讓MCTS提供更廣闊的選擇空間)。它集中在「明顯最好」的落子而不是閱讀很多,而不是再去選擇也許對後來有利的下法。
2. 對於每一個可能的落子,評估質素有兩種方式:要麽用棋盤上局面評估器在落子後,要麽執行更深入蒙特卡羅模擬器(捲動)去思考未來的落子,使用快速閱讀的落子選擇器去提高搜尋速度。AlphaGo使用簡單參數,「混合相關系數」,將每一個猜測取權重。最大馬力的AlphaGo使用 50/50的混合比,使用局面評估器和模擬化捲動去做平衡判斷。
這篇論文包含一個隨著他們使用外掛程式的不同,AlphaGo的能力變化和上述步驟的模擬。僅使用獨立大腦,AlphaGo跟最好的電腦圍棋AI差不多強,但當使用這些綜合手段,就可能到達職業人類選手水平。
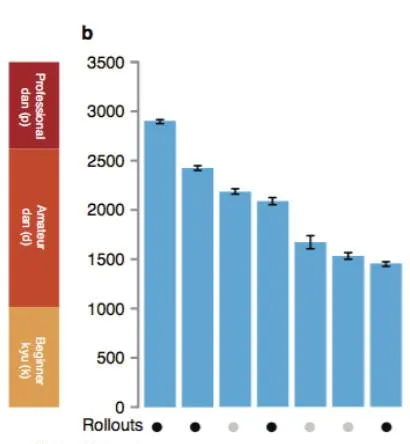
AlphaGo的能力變化與MCTS的外掛程式是否 使用 有關。
這篇論文還詳細講了一些工程最佳化:分布式計算,網絡電腦去提升MCTS速度,但這些都沒有改變基礎演算法。這些演算法部中分精確,部份近似。在特別情況下,AlphaGo透過更強的計算能力變的更強,但計算單元的提升率隨著效能變強而減緩。
優勢和劣勢
我認為AlphaGo在小規模戰術上會非常厲害。它知道透過很多位置和類別找到人類最好的下法,所以不會在給定小範圍的戰術條件下犯明顯錯誤。
但是,AlphaGo有個弱點在全域判斷上。它看到棋盤式透過5*5金字塔似的過濾,這樣對於整合戰術小塊變成戰略整體上帶來麻煩,同樣道理,圖片分類神經網絡往往對包含一個東西和另一個的搞不清。比如說圍棋在角落上一個定式造成一個墻或者引征,這會劇烈改變另一個角上的位置估值。
就像其他的基於MCTS的AI, AlphaGo對於需要很深入閱讀才能解決的大勢判斷上,還是麻煩重重的,比如說大龍生死劫。AlphaGo 對一些故意看起來正常的局也會失去判斷,天元開盤或者少見的定式,因為很多訓練是基於人類的棋局庫。
我還是很期待看到AlphaGo和李世石9段的對決!我預測是:如果李使用定式,就像跟其他職業棋手的對決,他可能會輸,但如果他讓AlphaGo陷入到不熟悉情形下,他可能就贏。
參考資料:
Nature 論文:http://www.
nature.com/nature/journ
al/v529/n7587/full/nature16961.html
關於 AlphaGo 論文的閱讀筆記_36氪
--------------------
報名轉譯:科技閱讀列表全集[600篇]關註如下我的微信公眾號「董老師在矽谷」,關註矽谷趨勢,一起學習成長。











