早期的渲染方式都是IMR(Immediate Mode Rendering,也就是Full Screen,因為它不去分Tile), IMR的優勢 是每個primitive直接送出渲染,pipeline沒有中斷,渲染速度快,pipeline並列起來時,每個Raster core只要負責render分給它的primitive即可,無需其他控制邏輯,只需在pixel shader後對Raster出的pixel做個排序:
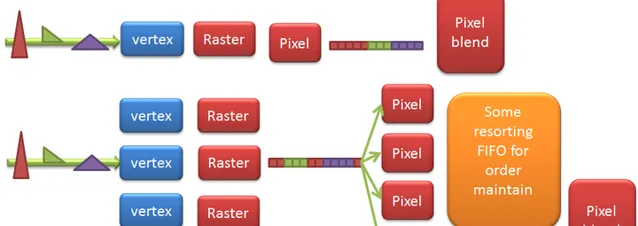
IMR的劣勢 在於頻寬壓力和功耗較大:
- z test跟blending都要頻繁從framebuffer裏讀數據,畢竟framebuffer是位於Memory上,頻寬壓力和功耗自然高;
- Overdraw的問題,比如Application在一幀裏先畫了棵樹,然後畫了面墻剛好遮住了樹,在IMR下樹仍然要在Pixel Shader裏Sample texture,而Texture也是放在Memory,訪存功耗大。
正因為這種劣勢,許多Mobile GPU轉向TBR(Tile Based Rendering),比如Imagination家的PowerVR,Arm家的Mali,Qualcomm家的Adreno(從AMD的Imageon收過來的),其實PC也有過嘗試TBR,但最終或失敗或取消,如微軟的Talisman, PowerVR的Kyro,Intel的Larrabee都失敗了,Nvidia的PC GPU Maxwell據說用了TBR做最佳化(但NV的mobile GPU tegra是IMR的,好吧):
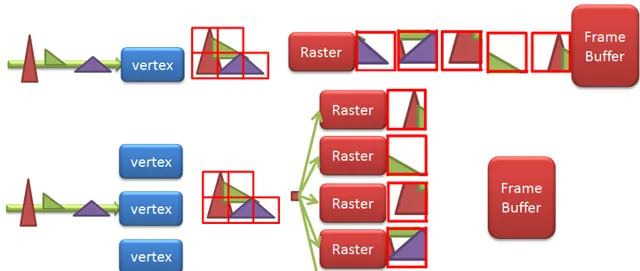
為什麽mobile GPU要轉向TBR呢,因為 TBR 給 解決頻寬功耗大 的兩個源頭提供了機會:
-
對於IMR所有
read z/framebuffer,到了TBR通通不需要
。TBR只需render完tile後把on-chip的pixel寫到frame buffer(不需要寫z,因為下一幀不需要用到前一幀的z和color)。
這個好處在於TBR將Screen Tiling。這樣,每次render的區域變小,小到可以把z/framebuffer搬到on-chip,快,省電。
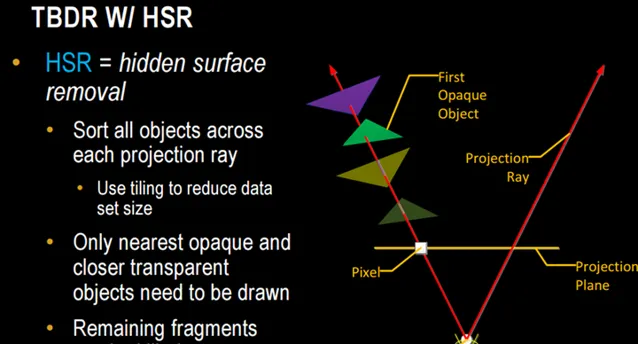
Tiled也意味著Deferred:要延遲到整個場景的primitive都收到後才能開始Raster 。為什麽?試想,剛拿到整個場景一半的primitive就開始Raster了,那麽render結束後z buffer就必須寫回framebuffer,然後另一半的primitive開始raster時還必須把z/framebuffer從memory讀回來,這樣一來就大打折扣了。 - TBR給消除Overdraw提供了機會 ,PowerVR用了HSR技術,Mali用了Forward Pixel Killing技術,目標一樣,就是要最大限度減少被遮擋pixel的texturing和shading,具體見後文。
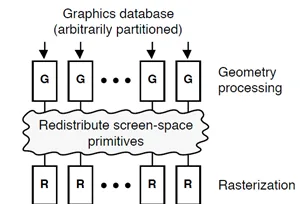
Tiled要求Defer,把pipeline提前打斷,從parallel rendering的角度看,IMR跟TBR是Sort Last和Sort Middle的區別:
Sort Middle:
Sort Last:
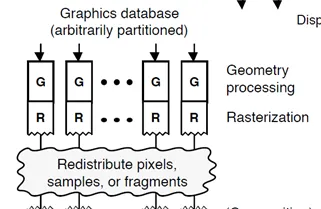
但凡並列渲染,都希望vertex直接找IDLE的shader,raster等資源執行,吐出數據,每個硬件資源之間不用互相通訊,結果不需要統籌,但Graphics API的渲染是有順序的,例如blending時Triangle的順序決定blending pixel的先後,而並列的rendering快慢不易,最終必須有個階段做個排序(Sort),用IMR的話,是到了pixel shading後才sort,簡單;用TBR的話,是在Geometry變化後,在Raster前做Sort,復雜,但有最佳化空間。
再說說TBR的劣勢,比較下IMR和TBR兩者的pipeline和memory access:

TBR的pipeline被分成兩部份:
1)第一部份處理Geometry的transform和場景的tiling,然後往memory裏寫入Geometry的數據和每個tile所要rendering的Geometry,好吧,跟IMR比起來多了memory的開銷,讀寫,這個是Trade off,沒有絕對好壞,總之說是機會,最佳化做得好就賺。例如Tile Size就是個Trade off點,大Tile意味著更少的Tile,重復setup的primitive(一個primitive覆蓋多個tile)更少,但也意味著每個tile有更多的triangle,on-chip buffer更大。
不過Tile list需要把每個draw的state info和所有primitive數據都保存起來,場景大的時候memory會overflow,overflow的問題可以最佳化,比如選擇一部份tile(PowerVR的macro tile)做rendering(這時需要讀寫memory上的z/framebuffer,犧牲下bandwidth和power,沒辦法)然後釋放這部份tile的memory。
PC螢幕大,PC game場景復雜,對Tile list壓力大,另外PC追求frame rate,所以很少用TBR,即使用了,遇到復雜遊戲場景估計會切換到IMR。
2)第二部份是tile raster, HSR 跟 Forward Pixel Kill 就是在這個階段做最佳化。
PowerVR的整體架構是這樣子的(Imagination官網圖片):

HSR 對完成覆蓋每個Tile的每個primitive的每個pixel做z test,最終保留最近的pixel(如果有blending,還需要保留透明半透明的pixel),最終每個pixel location只有一個pixel進shading(如果無blending的話)。
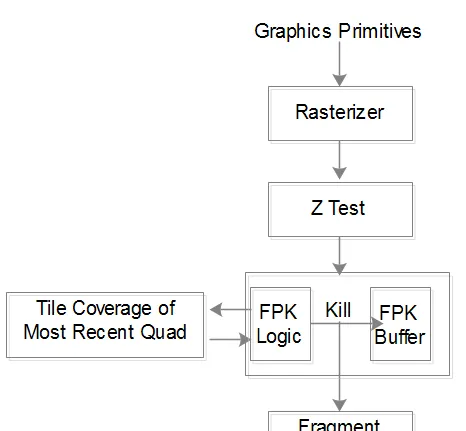
Forward Pixel Kill 會讓primtive cover到的每個pixel都進 shading thread(準確是quad,因為Pixel Shading是以quad為單位的),Mali用FPK logic和FPK buffer完成Forward Pixel Kill,其輸入為每個pass z test的quad(意味著每個input的quad是已收到的,對應同一位置的所有quad中距離眼睛最近)
另外,
TBR和TBDR是兩個很容易被混淆的概念,因為各家廠商用的術語不一樣
,
其實在ARM看來,TBR延遲了Rendering(第一個階段的整個場景被tiling後),所以他家認為TBR跟TBDR(Tile-Based Deferred Rendering)是同一個概念;
而在Imagination看來,PowerVR的HSR把texturing和shading也延遲了(剔除不可見pixle之後),它家認為TBR+HSR才是真正意義的TBDR。
所以可以看出,IMR的pipeline暢通無幹擾,sorting簡單,TBR的sorting較復雜,但也給低功耗最佳化提供了靈活的選擇。另外TBR pipeline的分割讓pipeline中斷了,各種defer,跟IMR比起來,速度也可能會進一步被影響而變慢。
總結一下,TBR用增大memory resource,以及(有可能)降低render rate的代價,獲得降低bandwidth,power的效益。











