開門見山,直接說jpeg的缺點:
8位元色彩深度 (理論上也可以支持更高深度,但我從未見過高於8位元的jpeg),也就是像素值範圍屬於[0,255];而單反/微單的raw一般都為12位元,像素值範圍[0,4095];甚至有14位元的,像素值範圍[0,16383]。顯然raw對顏色的分辨力更高,一般為jpeg的16倍甚至64倍。
有趣的是,RGB三通道均為8位元、共24位元色深的影像,稱之為「真彩色」;那12位元的raw豈不是「很真彩色」,14位元的就成了「超真彩色」...
YUV420采樣 (jpeg支持RGB,但是也從未見RGB的jpeg,畢竟jpeg本來就是做壓縮的,用RGB與壓縮的本意相違背),數據量Y:U:V=4:1:1,與原始的R:G:B=1:1:1相比,亮度資訊不變,但顏色資訊直接損失了75%。但是有些相機的raw也是使用YUV420。
不過,相機cmos的實際輸出中,每個像素點似乎只有一個值(R或G或B)。

而從raw解析出的影像,每個像素點的RGB值是從鄰域插值得到的,例如某個像素點本來為R,則它的G和B值被當作是八鄰域內的R和B值的均值。人眼對綠色更為敏感,因此cmos的R:G:B數量一般為1:2:1。在這種情況下,使用yuv420采樣也會有顏色損失,但損失小於75%。
高頻資訊有大量損失。 也就是影像中變化豐富的細節部份很難保留。這是dct+量化導致的。
塊效應。 由於jpeg的基本處理單元是一個個小塊,小塊之間的過渡不自然就會出現色塊效應。這在壓縮比較高或影像中顏色變化劇烈時,尤為明顯。塊效應其實也是失真壓縮最難解決的問題之一,在低質素的影片中更常見。


不適合多次編輯。 這一點 @Timothy Wang提到了,我給補充上去並詳細說明。因為每一次對影像進行ps然後保存成jpeg,都會有一次損失。所以修一次,保存,再修一次,保存...影像質素會越來越差...
不過這個問題也好解決,你只需要把jpeg先轉換成bmp再編輯即可。(那你為什麽不直接使用同為無失真的raw呢?)
例如使用質素因子99,將同一張圖片不斷讀取-編碼-保存jpeg:




現在畫質已經慘不忍睹了....
類似的例子可見於
順便說一句,字尾是jpeg與jpg沒有任何區別,檔頭都是0xFFD8。由於Windows上習慣用三個字母的檔字尾,所以jpeg簡寫為jpg。既然老大哥Windows都這樣用了,大家也就都混著用了。
下面是原理解釋,有興趣的同學可以
---------------------------------------------------------------------
我手寫過jpeg編碼器,因此對jpeg編碼算是比較了解。原始碼(歡迎點star):
raw是一種無失真的影像儲存格式,類似的還有bmp、png等,均為無失真儲存,而bmp不會做任何壓縮,png會做壓縮,但也是無損壓縮。無失真的儲存,會忠實記錄每一個像素點的像素值。將圖片保存為檔,然後再從檔中讀取圖片,讀的的圖片與原先的圖片沒有任何區別。
jpeg是一種 失真 的壓縮標準,失真意味著,將原圖保存成jpeg,再從jpeg讀取出圖片,得到的圖片與原來的圖片並非完全相同。
例如使用我自己編寫的jpeg編碼器,將bmp影像先編碼成jpeg再解碼,得到的影像與原影像作差,並視覺化,得到誤差影像:

誤差影像中,越白的像素,表示此處的誤差越大。可以發現,jpeg影像的誤差註意集中在影像中的輪廓(邊緣)區域。
下面介紹一下jpeg編碼的基本原理,以及誤差的來源。
jpeg的編碼過程為:分塊-dct變換-量化-掃描-編碼
分塊: 將圖片分成8*8或16*16的小區域,邊長不為8的整數倍則補齊。小塊的邊長為2的次冪,這是為了加速dct變換。
imageWidth = srcImageWidth
imageHeight = srcImageHeight
# add width and height to %8==0
if (srcImageWidth % 8 != 0):
imageWidth = srcImageWidth // 8 * 8 + 8
if (srcImageHeight % 8 != 0):
imageHeight = srcImageHeight // 8 * 8 + 8
print('added to: ', imageWidth, imageHeight)
# copy data from srcImageMatrix to addedImageMatrix
addedImageMatrix = numpy.zeros((imageHeight, imageWidth, 3), dtype=numpy.uint8)
for y in range(srcImageHeight):
for x in range(srcImageWidth):
addedImageMatrix[y][x] = srcImageMatrix[y][x]
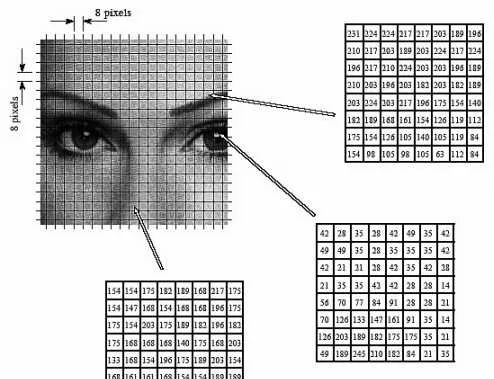
註意,jpeg很少對RGB空間進行操作,一般都是先將RGB轉化到YUV(亮度色度濃度)空間,而且這一過程往往會進行下采樣:
RAW中的RGB儲存數據量是R:G:B=1:1:1(但是也有不少raw中使用YUV420而非RGB)
如果使用YUV420(絕大多數jpeg都是YUV420,不過我的程式碼中使用的是YUV444),亮度不會被下采樣,但色度和濃度都是四取一,則Y:U:V=4:1:1
可以發現,僅僅在這一步,從RGB到YUV420,顏色資訊就損失了75%。
好在人眼對亮度更敏感,對顏色其實並不敏感,普通人很難看出經過YUV420采樣後圖片與原圖片有何區別。
dct變換: 遍歷每個小塊,進行dct變換。dct變換實際上是將原矩陣中的數據,按照頻率的大小進行重新排列。什麽是影像的頻率?可以理解成影像中灰度變化劇烈程度。顯然影像中輪廓處的灰度變化劇烈,所以輪廓是高頻區域。
8*8的矩陣經過dct變換後,得到的仍然是一個8*8的矩陣。dct變換後,原矩陣的直流分量(也就是均值)會被儲存到新矩陣的左上角,稱為DC量;而新矩陣中其他的63個值,稱為AC量。變換後的矩陣,越靠近右下方,所儲存的頻率越高。也就是,影像中的高頻細節,都儲存在新矩陣的右下部份,且細節越豐富、變化越劇烈,在新影像中的位置越靠近右下角。
for y in range(0, imageHeight, 8):
for x in range(0, imageWidth, 8):
print('block (y,x): ',y, x, ' -> ', y + 8, x + 8)
yDctMatrix = fftpack.dct(fftpack.dct(yImageMatrix[y:y + 8, x:x + 8], norm='ortho').T, norm='ortho').T
uDctMatrix = fftpack.dct(fftpack.dct(uImageMatrix[y:y + 8, x:x + 8], norm='ortho').T, norm='ortho').T
vDctMatrix = fftpack.dct(fftpack.dct(vImageMatrix[y:y + 8, x:x + 8], norm='ortho').T, norm='ortho').T
# 這裏用4*4舉例
[[127 127 127 127]
[127 127 127 127]
[127 127 127 127]
[127 127 127 127]]
dct->
[[508. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]
[ 0. 0. 0. 0.]]
[[ 127 127 127 127]
[ 127 127 127 127]
[ 127 127 -100 127] # 將127換成-100,導致這個位置成為「高頻區域」
[ 127 127 127 127]]
dct-> # 可以發現dct變換後得到的矩陣,與原來dct變換得到的矩陣大為不同
[[451.2 30.7 56.8 -74.1]
[ 30.7 -16.6 -30.7 40.1]
[ 56.8 -30.7 -56.8 74.1]
[-74.1 40.1 74.1 -96.9]]
dct變換是完全可逆的,但是電腦的精度有限,因此存在一定的截斷誤差。例如1/3只能表示為0.333......3,小數位數是有限的。但這種截斷誤差非常微小,可以忽略。
解碼器在進行idct變換(dct變換的逆操作)後,通常得到的也不會恰好是整數,而像素值必須為整數,因此此處又會出現舍入誤差。
下面的gif圖,是對原圖片進行dct變換,然後分別取前0到1023個頻率的分量求和,再反變換得到的影片,取的頻率越多,圖片越接近原圖片:
 分別取前0到1023個頻率
https://www.zhihu.com/video/1146758691666763776
分別取前0到1023個頻率
https://www.zhihu.com/video/1146758691666763776
量化: 其實就是取整。選取一個基準矩陣(稱之為量化表),然後用dct變換後的矩陣去點除量化表,得到量化矩陣。
例如量化表和dct變換後的矩陣為
luminanceQuantTbl:
[[ 2 1 1 2 2 4 5 6]
[ 1 1 1 2 3 6 6 6]
[ 1 1 2 2 4 6 7 6]
[ 1 2 2 3 5 9 8 6]
[ 2 2 4 6 7 11 10 8]
[ 2 4 6 6 8 10 11 9]
[ 5 6 8 9 10 12 12 10]
[ 7 9 10 10 11 10 10 10]]
yDctMatrix:
[[ 2.36750000e+02 5.53303392e+00 2.01307085e+00 -7.19686853e-02
-1.57009246e-16 3.96662146e-01 -6.24580225e+00 7.60578828e+00]
[ 6.66855886e+00 -7.52969799e-01 1.48262936e-01 -3.92175621e+00
2.30297862e+00 3.29949388e+00 -6.18734755e+00 5.08374735e+00]
[-4.84356843e+00 -5.43104954e-01 -1.19822330e+00 8.12655697e-01
-9.47093175e-01 -5.06521493e-01 3.05698052e+00 -2.63930259e+00]
[ 2.93827790e+00 1.53779026e+00 1.40202735e+00 1.54364563e+00
-6.90691317e-01 -1.43266006e+00 2.09031500e-01 4.41897106e-01]
[-1.75000000e+00 -1.52408871e+00 -7.24572153e-02 -1.48975772e+00
2.00000000e+00 9.95424283e-01 -2.13477164e+00 3.03160093e-01]
[ 1.36194964e+00 6.56452465e-01 -2.05142958e+00 -4.80757100e-01
-2.56621229e+00 1.19379124e+00 2.35377408e+00 3.00353396e-01]
[-1.24090487e+00 2.47316174e-01 3.30698052e+00 2.26126343e+00
2.28648519e+00 -2.94759335e+00 -1.55177670e+00 -1.09970969e+00]
[ 8.16663251e-01 -4.64349688e-01 -2.50381139e+00 -2.06205701e+00
-1.32619360e+00 2.47989422e+00 6.46286535e-01 1.01553293e+00]]
進行量化,也就是用dct變換後的矩陣去點除量化矩陣:
yQuantMatrix = numpy.rint(yDctMatrix / luminanceQuantTbl)
則量化得到:
yQuantMatrix:
[[118. 6. 2. -0. -0. 0. -1. 1.]
[ 7. -1. 0. -2. 1. 1. -1. 1.]
[ -5. -1. -1. 0. -0. -0. 0. -0.]
[ 3. 1. 1. 1. -0. -0. 0. 0.]
[ -1. -1. -0. -0. 0. 0. -0. 0.]
[ 1. 0. -0. -0. -0. 0. 0. 0.]
[ -0. 0. 0. 0. 0. -0. -0. -0.]
[ 0. -0. -0. -0. -0. 0. 0. 0.]]
註意,dct變換後的矩陣中,越靠近右下角,頻率越高,但值往往很小(因為高頻的數據在原影像中只占少數部份)。這些很小的值,在除以量化表後,很容易得到0。 也就是這些高頻數據,在量化的這一過程中被舍入了,jpeg的主要誤差就來源於此。
此外,雖然YUV有3通道,但jpeg總是使用2個量化表:一個用於亮度,一個用於色度和濃度。
std_luminance_quant_tbl = numpy.array(
[ 16, 11, 10, 16, 24, 40, 51, 61,
12, 12, 14, 19, 26, 58, 60, 55,
14, 13, 16, 24, 40, 57, 69, 56,
14, 17, 22, 29, 51, 87, 80, 62,
18, 22, 37, 56, 68, 109, 103, 77,
24, 35, 55, 64, 81, 104, 113, 92,
49, 64, 78, 87, 103, 121, 120, 101,
72, 92, 95, 98, 112, 100, 103, 99],dtype=int)
std_luminance_quant_tbl = std_luminance_quant_tbl.reshape([8,8])
std_chrominance_quant_tbl = numpy.array(
[ 17, 18, 24, 47, 99, 99, 99, 99,
18, 21, 26, 66, 99, 99, 99, 99,
24, 26, 56, 99, 99, 99, 99, 99,
47, 66, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99,
99, 99, 99, 99, 99, 99, 99, 99],dtype=int)
std_chrominance_quant_tbl = std_chrominance_quant_tbl.reshape([8,8])
3個通道卻用兩張量化表,而不是專門為色度和濃度各設計一個量化表,顯然誤差會增加(但並不明顯)。
blockNum = 0
for y in range(0, imageHeight, 8):
for x in range(0, imageWidth, 8):
print('block (y,x): ',y, x, ' -> ', y + 8, x + 8)
yDctMatrix = fftpack.dct(fftpack.dct(yImageMatrix[y:y + 8, x:x + 8], norm='ortho').T, norm='ortho').T
uDctMatrix = fftpack.dct(fftpack.dct(uImageMatrix[y:y + 8, x:x + 8], norm='ortho').T, norm='ortho').T
vDctMatrix = fftpack.dct(fftpack.dct(vImageMatrix[y:y + 8, x:x + 8], norm='ortho').T, norm='ortho').T
if(blockSum<=8):
print('yDctMatrix:\n',yDctMatrix)
print('uDctMatrix:\n',uDctMatrix)
print('vDctMatrix:\n',vDctMatrix)
yQuantMatrix = numpy.rint(yDctMatrix / luminanceQuantTbl)
uQuantMatrix = numpy.rint(uDctMatrix / chrominanceQuantTbl)
vQuantMatrix = numpy.rint(vDctMatrix / chrominanceQuantTbl)
由於jpeg的主要誤差就來自於量化,因此改變壓縮率,或者說影像質素,往往是透過改變量化表實作的。例如相機設定中,jpeg 的標準/精細,其實就是對應不同的量化表。
量化表中的數值越小,點除後小數部份會越小,取整後舍入誤差也越小,則jpeg質素越高;同理,量化表中越靠近右下的部份值越大,則影像中高頻資訊的損失越嚴重。
在程式碼中,我們透過「質素因數」這一數值,對量化表進行簡單的線性變換來改變影像質素:
if(quality <= 0):
quality = 1
if(quality > 100):
quality = 100
if(quality < 50):
qualityScale = 5000 / quality
else:
qualityScale = 200 - quality * 2
luminanceQuantTbl = numpy.array(numpy.floor((std_luminance_quant_tbl * qualityScale + 50) / 100))
luminanceQuantTbl[luminanceQuantTbl == 0] = 1
luminanceQuantTbl[luminanceQuantTbl > 255] = 255
luminanceQuantTbl = luminanceQuantTbl.reshape([8, 8]).astype(int)
print('luminanceQuantTbl:\n', luminanceQuantTbl)
chrominanceQuantTbl = numpy.array(numpy.floor((std_chrominance_quant_tbl * qualityScale + 50) / 100))
chrominanceQuantTbl[chrominanceQuantTbl == 0] = 1
chrominanceQuantTbl[chrominanceQuantTbl > 255] = 255
chrominanceQuantTbl = chrominanceQuantTbl.reshape([8, 8]).astype(int)
print('chrominanceQuantTbl:\n', chrominanceQuantTbl)
bmp體積為786.5KB,改變質素因數,得到的jpeg圖片和體積如下:

量化表均為1,幾乎沒有量化誤差:
luminanceQuantTbl:
[[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]]
chrominanceQuantTbl:
[[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1]]

luminanceQuantTbl:
[[ 6 4 4 6 10 16 20 24]
[ 5 5 6 8 10 23 24 22]
[ 6 5 6 10 16 23 28 22]
[ 6 7 9 12 20 35 32 25]
[ 7 9 15 22 27 44 41 31]
[10 14 22 26 32 42 45 37]
[20 26 31 35 41 48 48 40]
[29 37 38 39 45 40 41 40]]
chrominanceQuantTbl:
[[ 7 7 10 19 40 40 40 40]
[ 7 8 10 26 40 40 40 40]
[10 10 22 40 40 40 40 40]
[19 26 40 40 40 40 40 40]
[40 40 40 40 40 40 40 40]
[40 40 40 40 40 40 40 40]
[40 40 40 40 40 40 40 40]
[40 40 40 40 40 40 40 40]]

luminanceQuantTbl:
[[ 80 55 50 80 120 200 255 255]
[ 60 60 70 95 130 255 255 255]
[ 70 65 80 120 200 255 255 255]
[ 70 85 110 145 255 255 255 255]
[ 90 110 185 255 255 255 255 255]
[120 175 255 255 255 255 255 255]
[245 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]]
chrominanceQuantTbl:
[[ 85 90 120 235 255 255 255 255]
[ 90 105 130 255 255 255 255 255]
[120 130 255 255 255 255 255 255]
[235 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]]
這個量化表....均為255,高頻資訊幾乎完全遺失(所以每個色塊內都幾乎一個色了)
luminanceQuantTbl:
[[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]]
chrominanceQuantTbl:
[[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]
[255 255 255 255 255 255 255 255]]
掃描: 將二維矩陣掃描,得到一維陣列。希望更多的0元素儲存到一起,以便儲存時節省空間。因此按z字形掃描:
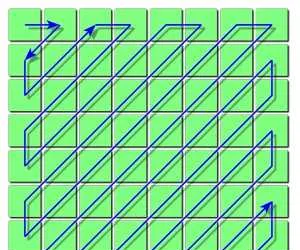
z字形掃描久負盛名,著名的FFMPEG(絕大多數播放器都是給FFMPEG套個圖形界面的殼,當然也有少部份是用gstreamer套殼..),采用的就是這個圖示:

註意,實際上每個小塊中的z字形掃描只針對AC值;所有小塊的DC值會被單獨儲存,且只儲存第一個DC值的真正值,剩下的都是儲存與前一個的差值。
編碼: 霍夫曼編碼或者算術編碼。是無失真編碼。DC值采用(Size,Value)格式,AC值采用(Run/Size,Value)格式。很復雜,不做詳細介紹。詳情請見於./python-jpeg-encoder/huffmanEncode.py











