更新:這篇答案有一點過時了,大體框架和想法供參考。
以前做過一些機器學習的東西,主要是經濟類的,因為當時不太確定數據背後的結構和內在規律,同時又想數據視覺化,所以用了SOM (Self-organizing Map, unsupervised)這些基本的機器學習方法,結果確實很有啟發性。部份分析與截圖可參考:從事經濟、金融工作的人都是透過什麽渠道獲得數據資源,運用什麽軟件來分析行業狀態和經濟走勢的? - 錢糧胡同的回答
背景: 法蘭克福某行做Portfolio Management,工作上跟各類經濟,行業,企業等數據打交道,再之前做過企業評級和信貸業務,所以時不時就會想把機器學習的一些東西套用到工作上。當然,銀行裏這些略有創新/ 實踐的想法基本都會被上面打回來,圖樣圖森破。
討論部份: 跑題了,直接討論下可行性:其實這方面國內國外都有一些研究文獻(針對中小企業信用評級/違約概率預測),主要是利用比較傳統的multi-layer back-propagation neural networks, 用已知結果的樣本反復培訓,再用另一部份樣本做實測,防止overfitting等等,我也做過一些。下圖是個基本原理,摘自網絡(TeX - LaTeX Stack Exchange):
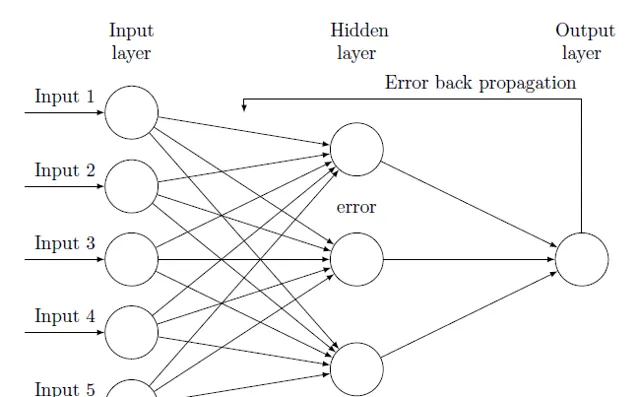
首先,我們要清楚神經網絡(類人工智能) 的分析有很多種,比如你是想做clustering(評級分類,如AAA, AA, BB, CCC等),還是想預測具體違約概率。對於PD,我想比較適合的是預測具體數值吧?長時間這些數值的積累與變化,畫成圖,就像是企業的生命線。
我們先看一下傳統的企業信用評級,方法很多,但是大同小異 (可以參看標普關於評級的網站:Understanding Ratings), 基本分財務與非財務 :
企業信用評級簡要框架:
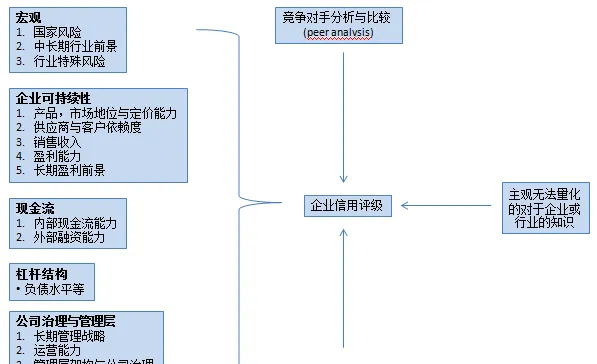
我個人感覺,企業違約概率/ 信用評級其實一般模型就可以做(相關文獻也比較多,如SVM,PCA,甚至最基本傳統的數學模型),如果要用機器學習的話,一定要找到突破點。我覺得優勢應該是尋找大規模量化的數據中潛在的規律或結構,最佳化預測結果。如果可以透過如unsupervised的學習方法來獲得(或者就是supervise中培訓模型的時候,告訴模型結果然後反復培訓 - 其實就是在不知不覺中讓機器尋找數據背後的結構區別),應該是很有價值的。
潑冷水時間: 從銀行角度來看,個人信用評級和中小企業信用評級,再到大型企業評級(簡單的企業分類可以按照企業的銷售額與總資產等指標,如果復雜一些,這方面本身就可以用機器學習:比如用ANN中clustering的方法,如之前提到過的SOM,或者非ANN中傳統的K均值),區別還是蠻明顯的,尤其企業類評級一般量不大(相比retail),同時數據比較滯後,源少,這個方面我覺得如果想使用機器學習的話需要找到非常好的理由與突破口,否則就有點成心顯擺的感覺(就好像有些任務,明明簡單的用excel的pivot功能就可以很好的完成,非要用VBA或者R,意義不大)。
冷水潑完來點熱水: 很多同行說銀行內部的評級要獨立(假設這麽有節操的銀行用的是高級評級法),與信貸業務的考慮盡量分開。我認為,在評級過程中,企業信用本身與周邊宏觀環境確實決定了違約的概率 (forward looking),保持獨立性很好,但是如果把信貸業務中交易等環節的動態有時效性的數據也加入到評級分析中(企業與銀行之間交易的行為數據),那麽很有可能提高評級的時效性與準確性,而這個方面就需要高度的自動化與資料探勘。所以這個領域前景還是很廣闊多變的。
One more thing: 今天工作,突然想到機器學習的一個優勢之前沒有說到:平常做企業分析,行業內類似企業的對比分析 (peer analysis)很重要,而這一塊根據我的經驗,很多分析師容易疏忽,或者一些junior因為對行業的理解不到位,導致peer的選擇不對,影響最後分析結果的正確性。如果采用機器學習,數據結構的探索本身應該就可以一定程度上解決這個問題。
先回答到這裏,主要覺得這個問題結合的比較貼近我的工作,有興趣的話再討論。











