早期的渲染方式都是IMR(Immediate Mode Rendering,也就是Full Screen,因为它不去分Tile), IMR的优势 是每个primitive直接提交渲染,pipeline没有中断,渲染速度快,pipeline并行起来时,每个Raster core只要负责render分给它的primitive即可,无需其他控制逻辑,只需在pixel shader后对Raster出的pixel做个排序:
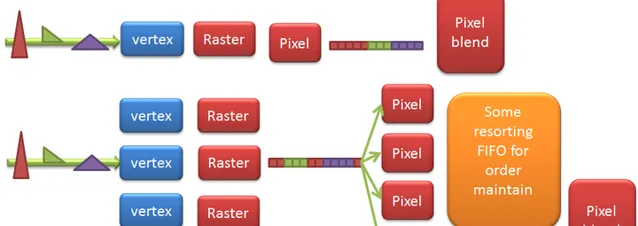
IMR的劣势 在于带宽压力和功耗较大:
- z test跟blending都要频繁从framebuffer里读数据,毕竟framebuffer是位于Memory上,带宽压力和功耗自然高;
- Overdraw的问题,比如Application在一帧里先画了棵树,然后画了面墙刚好遮住了树,在IMR下树仍然要在Pixel Shader里Sample texture,而Texture也是放在Memory,访存功耗大。
正因为这种劣势,许多Mobile GPU转向TBR(Tile Based Rendering),比如Imagination家的PowerVR,Arm家的Mali,Qualcomm家的Adreno(从AMD的Imageon收过来的),其实PC也有过尝试TBR,但最终或失败或取消,如微软的Talisman, PowerVR的Kyro,Intel的Larrabee都失败了,Nvidia的PC GPU Maxwell据说用了TBR做优化(但NV的mobile GPU tegra是IMR的,好吧):
为什么mobile GPU要转向TBR呢,因为 TBR 给 解决带宽功耗大 的两个源头提供了机会:
-
对于IMR所有
read z/framebuffer,到了TBR通通不需要
。TBR只需render完tile后把on-chip的pixel写到frame buffer(不需要写z,因为下一帧不需要用到前一帧的z和color)。
这个好处在于TBR将Screen Tiling。这样,每次render的区域变小,小到可以把z/framebuffer搬到on-chip,快,省电。
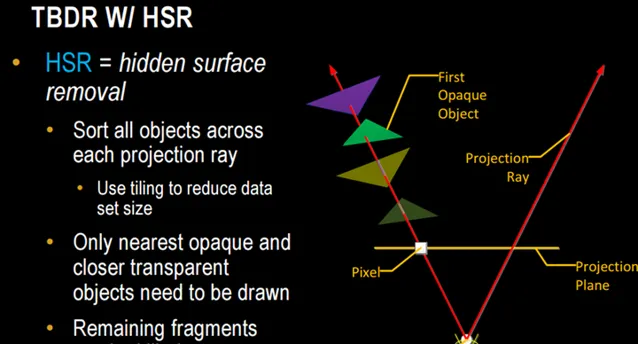
Tiled也意味着Deferred:要延迟到整个场景的primitive都收到后才能开始Raster 。为什么?试想,刚拿到整个场景一半的primitive就开始Raster了,那么render结束后z buffer就必须写回framebuffer,然后另一半的primitive开始raster时还必须把z/framebuffer从memory读回来,这样一来就大打折扣了。 - TBR给消除Overdraw提供了机会 ,PowerVR用了HSR技术,Mali用了Forward Pixel Killing技术,目标一样,就是要最大限度减少被遮挡pixel的texturing和shading,具体见后文。
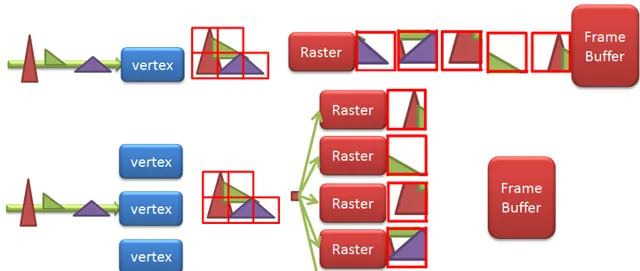
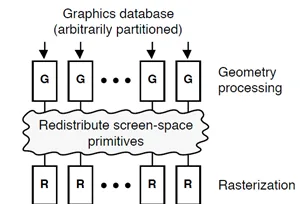
Tiled要求Defer,把pipeline提前打断,从parallel rendering的角度看,IMR跟TBR是Sort Last和Sort Middle的区别:
Sort Middle:
Sort Last:
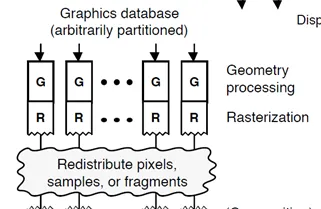
但凡并行渲染,都希望vertex直接找IDLE的shader,raster等资源执行,吐出数据,每个硬件资源之间不用互相通信,结果不需要统筹,但Graphics API的渲染是有顺序的,例如blending时Triangle的顺序决定blending pixel的先后,而并行的rendering快慢不易,最终必须有个阶段做个排序(Sort),用IMR的话,是到了pixel shading后才sort,简单;用TBR的话,是在Geometry变化后,在Raster前做Sort,复杂,但有优化空间。
再说说TBR的劣势,比较下IMR和TBR两者的pipeline和memory access:

TBR的pipeline被分成两部分:
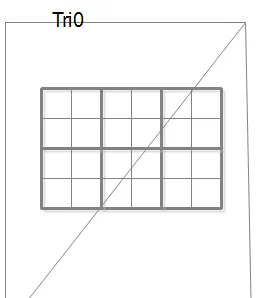
1)第一部分处理Geometry的transform和场景的tiling,然后往memory里写入Geometry的数据和每个tile所要rendering的Geometry,好吧,跟IMR比起来多了memory的开销,读写,这个是Trade off,没有绝对好坏,总之说是机会,优化做得好就赚。例如Tile Size就是个Trade off点,大Tile意味着更少的Tile,重复setup的primitive(一个primitive覆盖多个tile)更少,但也意味着每个tile有更多的triangle,on-chip buffer更大。
不过Tile list需要把每个draw的state info和所有primitive数据都保存起来,场景大的时候memory会overflow,overflow的问题可以优化,比如选择一部分tile(PowerVR的macro tile)做rendering(这时需要读写memory上的z/framebuffer,牺牲下bandwidth和power,没办法)然后释放这部分tile的memory。
PC屏幕大,PC game场景复杂,对Tile list压力大,另外PC追求frame rate,所以很少用TBR,即使用了,遇到复杂游戏场景估计会切换到IMR。
2)第二部分是tile raster, HSR 跟 Forward Pixel Kill 就是在这个阶段做优化。
PowerVR的整体架构是这样子的(Imagination官网图片):

HSR 对完成覆盖每个Tile的每个primitive的每个pixel做z test,最终保留最近的pixel(如果有blending,还需要保留透明半透明的pixel),最终每个pixel location只有一个pixel进shading(如果无blending的话)。
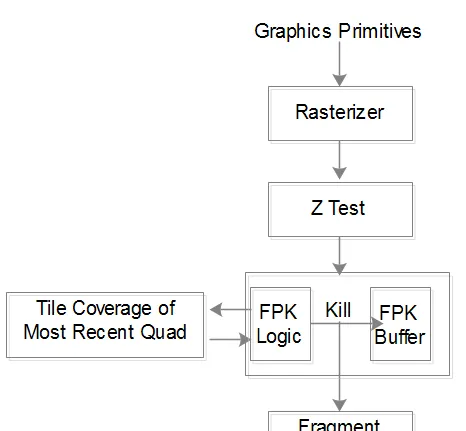
Forward Pixel Kill 会让primtive cover到的每个pixel都进 shading thread(准确是quad,因为Pixel Shading是以quad为单位的),Mali用FPK logic和FPK buffer完成Forward Pixel Kill,其输入为每个pass z test的quad(意味着每个input的quad是已收到的,对应同一位置的所有quad中距离眼睛最近)
另外,
TBR和TBDR是两个很容易被混淆的概念,因为各家厂商用的术语不一样
,
其实在ARM看来,TBR延迟了Rendering(第一个阶段的整个场景被tiling后),所以他家认为TBR跟TBDR(Tile-Based Deferred Rendering)是同一个概念;
而在Imagination看来,PowerVR的HSR把texturing和shading也延迟了(剔除不可见pixle之后),它家认为TBR+HSR才是真正意义的TBDR。
所以可以看出,IMR的pipeline畅通无干扰,sorting简单,TBR的sorting较复杂,但也给低功耗优化提供了灵活的选择。另外TBR pipeline的分割让pipeline中断了,各种defer,跟IMR比起来,速度也可能会进一步被影响而变慢。
总结一下,TBR用增大memory resource,以及(有可能)降低render rate的代价,获得降低bandwidth,power的效益。











