nvidia gpu内部硬件单元有很多种,单独某一种的数量与显卡性能并不成严格的正相关。
实际上每一代架构都在调整各种单元之间的比例,目的是为了 让程序提高并行度,使有效吞吐接近理论极限 。如果设计gpu的过程中没有权衡各种硬件资源的比例,会造成某一种硬件资源的缺乏成为限制整个cuda程序运行效率的瓶颈。
问题里的cuda core,或者称为sp,是主要的运算单元,内部有分别处理int和单精度float的部分,用于执行一些常用的运算指令。除了sp之外还有双精度单元用于科学计算以及特殊运算单元sfu来执行比较复杂的运算指令比如三角函数。 而gpu中除了这些运算单元之外还有很重要很稀缺的储存器结构。现代计算机,无论CPU还是GPU,主要的性能瓶颈都来自储存器。 gpu运算单元的总峰值吞吐能力远远超过访存的峰值带宽。
在硬件上比SP更大的运算单位称为SM,一个SM是由多个SP加上其他的资源组成的,实际上 SM才更像是一个具有完整功能的CORE。 因为SM可以调度并发射指令到运算单元内。
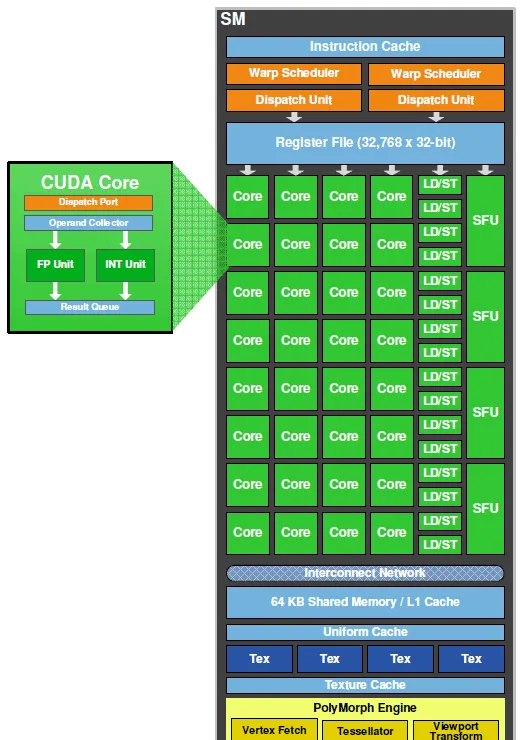
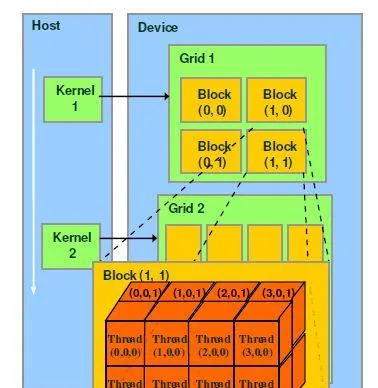
nvidia一直在努力把自己的gpu从一般的图形处理器往通用计算的方向发展,cuda core里面的cuda这个词就是nvidia主推的并行计算架构。无论是图形渲染还是cuda编程,最基本的程序并行结构称为thread,这是程序员可以控制的最细粒度的并行单位。每一个thread在运算单元上就对应一个sp,所以新闻里常常会笼统的把sp数量等同于thread的并行数量,从而量化不同GPU的性能。多个thread组合起来称为一个block,数量是程序员可以设定的。在同一个block内的thread之间可以相互通信,因为他们可以共用同一个SM内的shared memory(共享储内存),每一个thread还拥有各自独占的register(寄存器)和local memory(本地储存器),这几种储存器都是整个GPU中距离运算单元距离最近,速度最快的储存器资源。但是跨block的线程通信不能通过SM内部的储存器,只能通过距离很远,访问时间长达几百个周期的global memory(全局内存,就是指显存)来实现,这个速度实在太慢了,所以cuda程序会尽量避免使用global memory。
block在硬件上是由SM调用驻留的,一个SM会把属于它的block拆分成很多warp(硬件上的调度单位)分批喂给运算单元去执行,一个warp包含了32个thread。而所有属于这个SM的block会共用这个SM上的资源。对于编程人员来说,程序并行化的关键就在于设计一个方案,使得一个SM内的各种硬件单元都能有效利用,得到最理想的吞吐。
打个比方,一个SM内部有48kb的shared memory,8192个register,假如程序员设定的每个block里面有64个线程,并且希望每个sm能同时驻留2个block,那么每个线程就能分到8192/2/64=64个register,一个block可以分配到48/2=24kb的shared memory,接着这位程序员又修改了程序,使得每个thread使用到的资源更多,并且恰好比之前算出来的极限值多那么一点点,就会导致一个SM满足不了驻留2个block,只能留下来一个,于是就会空置很多硬件资源不能得到有效的利用。总结一下,如果一个SM内的硬件资源比例不均,不能满足程序员的分配需求,那么就会导致同时执行的block数量变少。结合题主的问题来说, 即使一个gpu内部有很多很多的运算单元,却没有足够的其他资源支撑这些运算单元同时并行,那么这些运算单元就会闲置,白白浪费了算力。
最新的Pascal虽然每个SM的sp数量相对于前代Maxwell而言只有一半(64/128),但是拥有相同的储存器资源,所以能提供给每个block/thread更多的储存器资源,从而保证每个运算单元的充分利用。再加上全局上的GPU运行频率比原来更高,即使总运算单元数量减少一点,最终折算的吞吐能力也会比上一代更高。
另外gpu的设计是考虑到成本和散热等宏观因素的,高速片上储存器占用晶体管多,所以容量有限,往往在芯片制程和工艺更新换代之后才有条件增大容量,不可能做到无限制的堆砌硬件资源。新一代的设计一般都会着重于提升每瓦性能,并且根据实际编程中总结出来的设计模式对硬件资源比例进行调整,这是个不断trade off的过程。











