2020年底给某大厂做过一个报告,包含两部分内容:一部分是关于计算机体系结构,尤其是CPU结构的演变;另一部分关于处理器芯片设计方法。这里把第一部分内容贴出来回答一下这个知乎问题。

- 首先回顾一下计算机体系结构领域三个定律: 摩尔定律、牧本定律、贝尔定律 。摩尔定律就不用多说了,但想表达一个观点是摩尔定律未死,只是不断放缓。
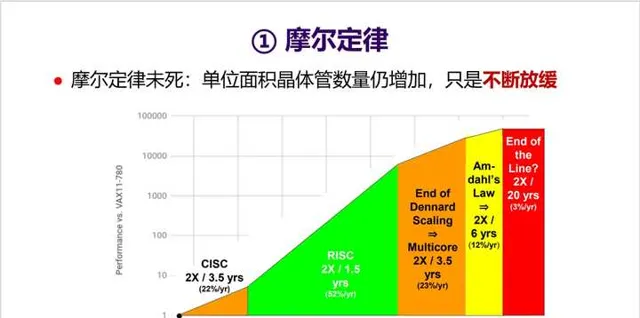
2. 摩尔定律让芯片上的晶体管数量不断增加,但一个问题是 这些晶体管都被充分用起来了吗 ?最近MIT团队在【Science】上发表了一篇文章【There’s plenty of room at the Top: What will drive computer performance after Moore’s law?】,给出他们的答案: 显然没有 !
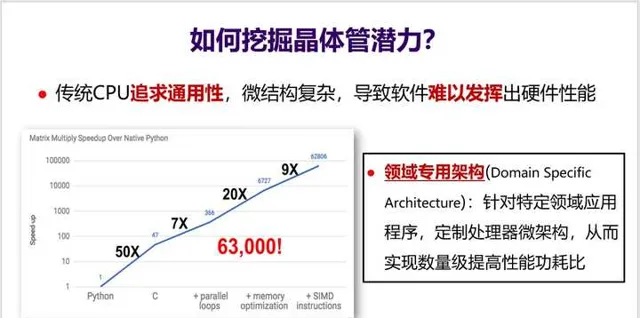
可以来看一下MIT团队开展的一个小实验(见下面PPT):假设用Python实现一个矩阵乘法的性能是1,那么用C语言重写后性能可以提高50倍,如果再充分挖掘体系结构特性(如循环并行化、访存优化、SIMD等),那么 性能甚至可以提高63000倍 。然而,真正能如此深入理解体系结构、写出这种极致性能的程序员绝对是凤毛麟角。
问题是 这么大的性能差异到底算好还是坏 ?从软件开发角度来看,这显然不是好事。这意味着大多数程序员无法充分发挥CPU的性能,无法充分利用好晶体管。这不能怪程序员,更主要还是因为CPU微结构太复杂了,导致软件难以发挥出硬件性能。
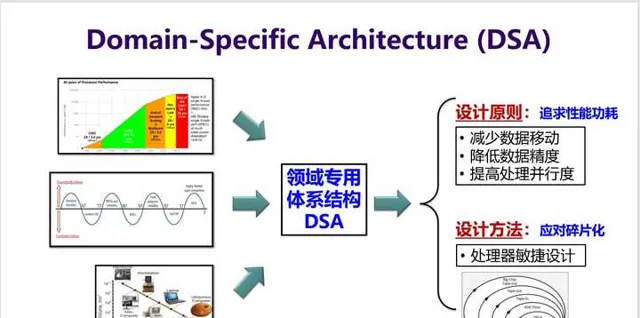
如何解决这个问题? 领域专用架构DSA(Domain-Specific Architecture)就是一个有效的方法 。DSA可以针对特定领域应用程序,定制微结构,从而实现数量级提高性能功耗比。这相当于是 把顶尖程序员的知识直接实现到硬件上 。
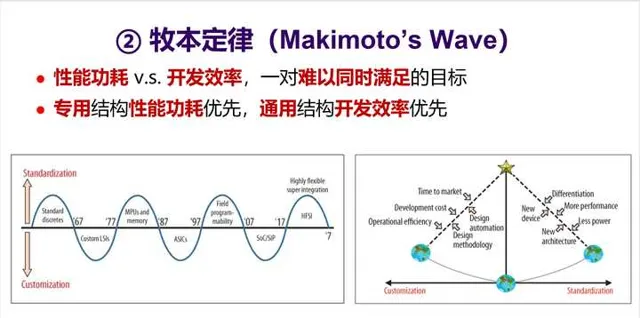
3. 第二个定律是 牧本定律 (也有称「牧本波动」)。1987 年, 原日立公司总工程师牧本次生(Tsugio Makimoto,也有翻译为牧村次夫,故称为「牧村定律」) 提出,半导体产品发展历程总是在「 标准化」与「定制化 」之间交替摆动,大概每十年波动一次。牧本定律背后是性能功耗和开发效率之间的平衡。
对于处理器来说,就是 专用结构和通用结构 之间的平衡。最近这一波开始转向了追求性能功耗,于是专用结构开始更受关注。
4. 第三个定律是 贝尔定律 。这是Gordon Bell在1972年提出的一个观察,具体内容如下面的PPT所述。值得一提的是超级计算机应用最高奖「戈登·贝尔奖」就是以他的名字命名。
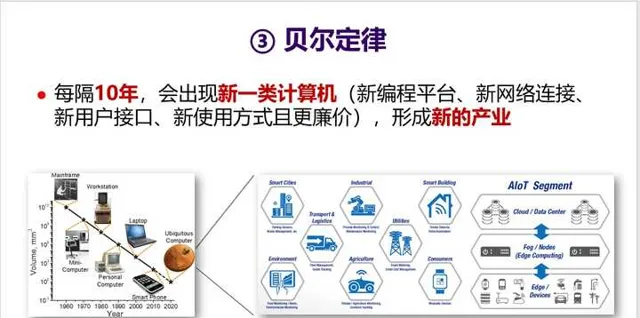
5. 贝尔定律指明了未来一个新的发展趋势,也就是AIoT时代的到来。 这将会是一个处理器需求再度爆发的时代,但同时也会是一个需求碎片化的时代 ,不同的领域、不同行业对芯片需求会有所不同,比如集成不同的传感器、不同的加速器等等。 如何应对碎片化需求 ?这又将会是一个挑战。
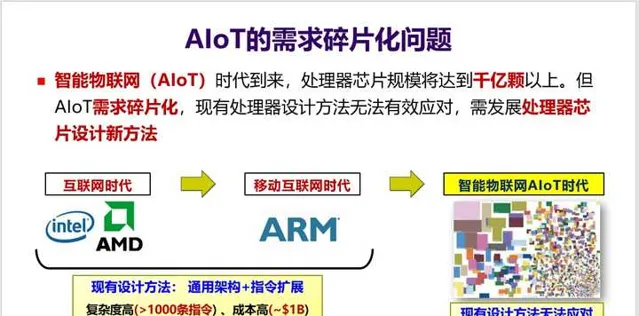
6. 这三个定律都驱动计算机体系结构向一个方向发展,那就是「DSA」 。如何实现DSA,这又涉及到两个方面:
- 为了追求性能功耗,有三条主要的设计原则(见下面PPT);
- 为了应对碎片化需求,则需要发展出处理器敏捷设计新方法。(这个回答就不介绍敏捷设计方法了)
7. 在谈一些具体技术之前,我们可以 先总体看一下过去几十年CPU性能是如何提升的 。下面这页PPT列出了1995-2015这二十年Intel处理器的架构演进过程——这是一个不断迭代优化的过程,集成了上百个架构优化技术。
这些技术之间还存在很多耦合,带来很大的设计复杂度。比如2011年在Sandy Bridge上引入了 大页面技术 ,要实现这个功能,会涉及到 超标量、乱序执行、大内存、SSE指令、多核、硬件虚拟化、uOP Fusion 等等一系列CPU模块和功能的修改,还涉及 操作系统、编译器、函数库 等软件层次修改,可谓是牵一发动全身。( 经常看到有人说芯片设计很简单,也许是因为还没有接触过CPU芯片的设计,不知道CPU设计的复杂度 )

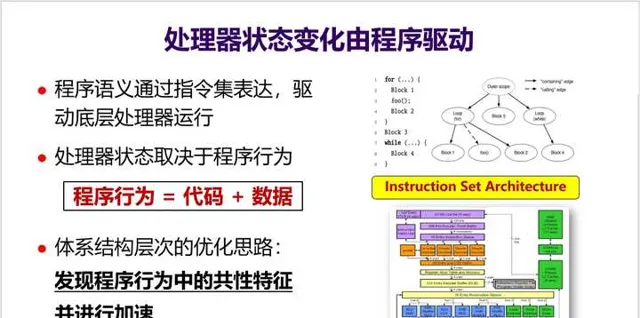
8. 处理器内部有非常复杂的状态,其状态变化是由程序驱动的。也就是说, 处理器状态取决于程序行为 (见下面PPT),而CPU体系结构层次的优化思路就是 发现程序行为中的共性特征并进行加速。
如何发现程序行为中的共性特征,就是处理器优化的关键点,这 需要对程序行为、操作系统、编程与编译、体系结构等多个层次都有很好的理解,这也是计算机体系结构博士的基本要求 。这也是为什么很多国外的计算机体系结构方向属于Computer Science系。
题外话:这两天看到国内成立集成电路一级学科,这是一个好消息。不过 要能培育CPU设计人才,在课程设计上不要忽视了操作系统、编程与编译这些传统计算机科学的课程 。
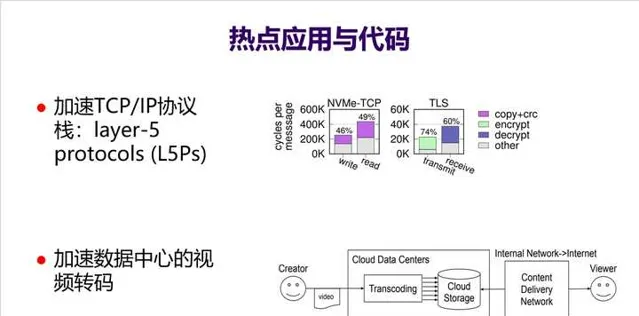
9. 举两个发现热点应用和热点代码、并在体系结构层次上优化的例子 。一个例子是发现在不少领域 TCP/IP协议栈五层协议(L5Ps) 存在很多大量共性操作,比如加密解密等,于是直接在网卡上实现了一个针对L5Ps的加速器,大幅加速了网络包处理能力。另一个例子是这次疫情导致云计算数据中心 大量算力都用来做视频转码 ,于是设计了一个硬件加速器专门来加速视频转码,大幅提升了数据中心效率。
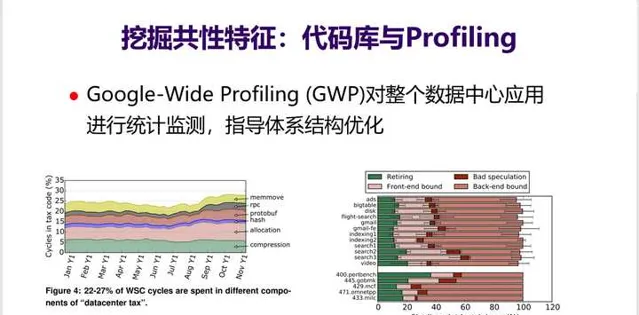
10. 发现和识别这种热点应用和热点代码并不容易, 需要由很强大的基础设施和分析设备 。比如Google在其数据中心内部有一个GWP工具,能对整个数据中心应用在很低的开销下进行监测与统计,找到算力被那些热点程序/代码消耗,当前的CPU哪些部件是瓶颈。比如 GWP显示在Google数据中心内部有5%的算力被用来做压缩。
正是 得益于这些基础工具,Google很早就发现AI应用在数据中心中应用比例越来越高,于是开始专门设计TPU来加速AI应用 。
11. 下面分别从三个方面来介绍体 系结构层面的常见优化思路 : 减少数据移动、降低数据精度、提高处理并行度 。
首先看一下如何减少数据移动。第一个切入点是 指令集 ——指令集是程序语义的一种表达方式。 同一个算法可以用不同粒度的指令集来表达,但执行效率会有很大的差别 。一般而言,粒度越大,表达能力变弱,但是执行效率会变高。
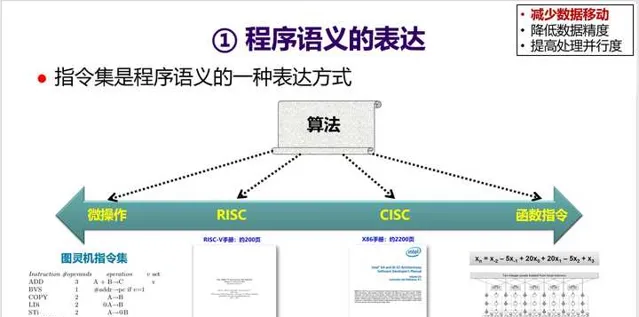
12. 通用指令集为了能覆盖尽可能多的应用,所以往往需要支持上千条指令,导致 流水线前端设计(取指、译码、分支预测等)变得很复杂,对性能与功耗都会产生负面影响 。

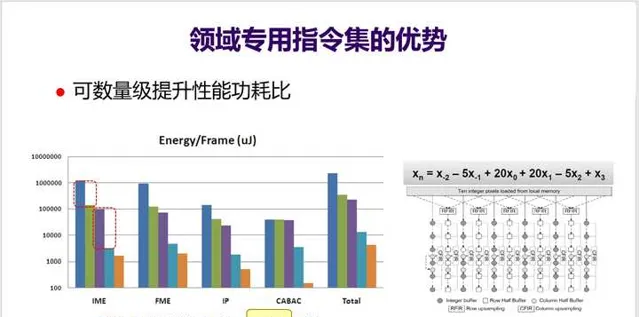
13. 针对某一个领域设计专用指令集,则可以大大减少指令数量,并且可以 增大操作粒度、融合访存优化,实现数量级提高性能功耗比 。下面PPT的这组数据是斯坦福大学团队曾经做过的一项研究,从这个图可以看出, 使用了「Magic Instruction」后,性能功耗比大幅提升几十倍 。而这种Magic Instruction其实就是一个非常具体的表达式以及对应的电路实现(见PPT右下角)。
14. 第二个减少数据移动的常用方法就是充分发挥缓存的作用 。访存部件其实是处理器最重要的部分了,涉及许多技术点(如下面PPT)。 很多人都关注处理器的流水线多宽多深,但其实大多数时候,访存才是对处理器性能影响最大的 。
关于访存优化,也有一系列技术,包括替换、预取等等。这些技术到今天也依然是体系结构研究的重点,这里就不展开细讲了。

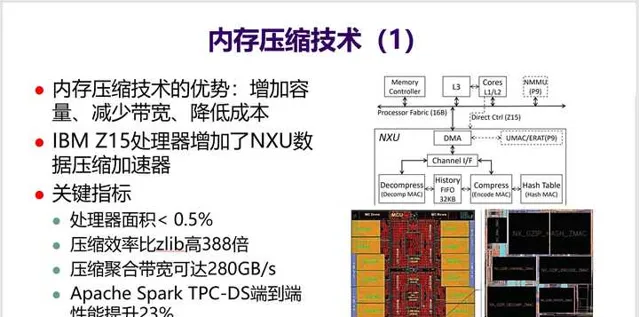
15. 不再展开介绍访存优化技术,就选 最近比较热的内存压缩方向 介绍一下。
IBM在最新的Z15处理器中增加了一个内存压缩加速模块,比软件压缩效率提高388倍,效果非常突出。
16. 英伟达也在研究如何 在GPU中通过内存压缩技术来提升片上存储的有效容量 ,从而提高应用性能。

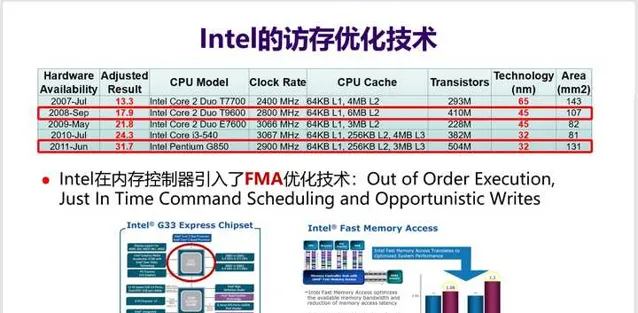
17. Intel在访存优化上很下功夫 ,可以通过对比两款Intel CPU来一窥究竟。Core 2 Due T9600和Pentium G850两块CPU,工艺差一代,但频率相近,分别是2.8GHz和2.9GHz,但性能差了77%——SPEC CPU分值G850是31.7分,而T9600只有17.9分。
频率相当,为何性能会差这么多 ?事实上,G850的Cache容量比T9600还要小——6MB L2 vs. 256KB L2 + 3MB L3。
如果再仔细对比下去,就会发现这两款处理器 最大的区别在于G850适配的内存控制器中引入FMA(Fast Memory Access)优化技术 ,大幅提高了访存性能。
18. 第二类体系结构优化技术是降低数据精度 。这方面是这几年研究的热点,特别是在深度学习领域,很多研究发现不需要64位浮点,只需要16位甚至8位定点来运算,精度也没有什么损失,但性能却得到数倍提升。
很多AI处理器都在利用这个思路进行优化,包括前段时间日本研制的世界最快的超级计算机「富岳」中的CPU中就采用了不同的运算精度。因此其 基于低精度的AI运算能力可以达到1.4EOPS,比64位浮点运算性能(416PFLOPS)要高3.4倍 。

19. IEEE 754浮点格式的一个弊端是不容易进行不同精度之间的转换 。近年来学术界提出一种新的浮点格式——POSIT,更容易实现不同的精度,甚至有一些学者 呼吁用POSIT替代IEEE 754 (Posit: A Potential Replacement for IEEE 754)。
RISC-V社区一直在关注POSIT,也有团队实现了基于POSIT的浮点运算部件FPU ,但是也还存在一些争论(David Patterson和POSIT发明人John L. Gustafson之间还有一场精彩的辩论,另外找机会再介绍)。

20. 体系结构层次的第三个优化思路就是并行 。这个题目中提到的「多核」,就是这个思路中一个具体的技术。除了多核,还有其他不同层次的并行度,比如指令集并行、线程级并行、请求级别并行;除了指令级并行ILP,还有访存级并行MLP。总之,提高处理并行度是一种很有效的优化手段。

以上是关于计算机体系结构尤其是CPU结构优化思路的一个大致梳理,供大家参考。总结来说就是两点结论:
- 领域专用体系结构DSA是未来一段时间体系结构发展趋势;
- 体系结构层面3条优化路线——减少数据移动、降低数据精度、提高处理并行度。









