基于格的难题你只说了一个RLWE,不知你是不是已经了解基于格的其它难题。引用刚才在另外一个问题中的回复。
密码学难题还有很多。说几个比较热门的。基于格的密码难题 \rm SVP
和 \rm CVP
,这两个难题都是抗量子的。还有基于他们构建的LWE和RLWE问题,它们是构建全同态加密的基础。
相关的知识内容可关注我并去我专栏学习。
下面我们来讲下基本的\rm SVP
和 \rm CVP
。
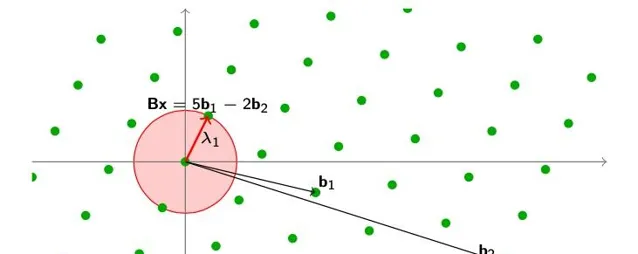
最短向量问题 \rm SVP
让我们定义最基本的涉及格的计算难题:最短向量问题,简称 \rm SVP
。 在这里,我们给出了一个格,需要我们找到最短的非零格点。 更准确地说,\rm SVP
有三个变体,这取决于我们是否必须实际找到最短的向量,找到它的长度,或者仅仅取决于它是否比某些给定的数字小:
Search
\rm SVP
: 给定格基 B∈\mathbb{Z}^{m×n}
求 v∈\mathcal{L}(B)
,使 ||v||=λ_1(\mathcal{L}(B))
。
Optimization
\rm SVP
: 给定格基 B∈\mathbb{Z}^{m×n}
,找到 λ_1(\mathcal{L}(B))
。
Decisional
\rm SVP
:给定格基 B∈\mathbb{Z}^{m×n}
和有理数 r\in \mathbb{Q}
,判断λ_1(\mathcal{L}(B))\leq r
是否成立。
注意,我们限制格基由整数向量组成,而不是任意的实向量。这样做的目的是使输入以有限的多位表示,这样我们就可以将 \rm SVP
视为一个标准的计算难题。我们还可以允许格基由有理向量组成。这将导致一个本质上等价的定义,因为通过缩放,可以使所有有理数坐标都是整数。
上述三个变体之间的两个简单关系是,决策变体不比优化变体更难,优化变体不比搜索变体更难。 事实上,可以证明逆向也是正确的:优化变量不比决策变量更难,搜索变量不比优化变量更难。 总之,这三个变体本质上是等价的。
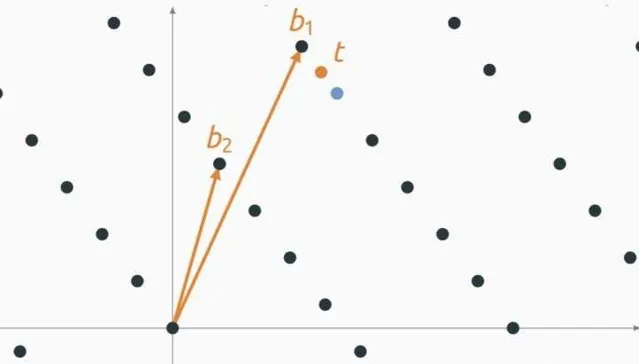
最近的向量问题 \rm CVP
另一个基本格难题是最近的向量问题,简称 \rm CVP
,i.e.,目标是找到最接近给定空间点的格点。 和以前一样,对于任何近似因子 \gamma \geq 1
,我们可以定义三个变体:
Search
\rm CVP_\gamma
: 给定格基 B∈\mathbb{Z}^{m×n}
和向量 t\in \mathbb{Z}^{m}
,查找 v\in \mathcal{L(B)}
使得 ||v-t|| \leq \gamma \cdot {\rm {dist}} (t, \mathcal{L}(B))
。
Optimization
\rm CVP_\gamma
:给定格基 B∈\mathbb{Z}^{m×n}
和向量 t\in \mathbb{Z}^{m }
,求 d
使d≤{\rm dist}(t,\mathcal{L}(B))≤\gamma\cdot d
。
Promise
\rm CVP_\gamma
: 由 a triple (B,t,r)
给出一个难题实例,其中 B∈\mathbb{Z}^{m×n}
是格基, t∈\mathbb{Z}_m, r∈\mathbb{Q}
。 在 YES 实例中, {\rm dist}(t,\mathcal{L}(B)≤r
。在没有情况下, {\rm dist}(t,\mathcal{L}(B)\geq r
。
\rm CVP
和 \rm SVP
都是困难的计算问题,我们将在本课程后面更详细地讨论这些问题。 还有一些格中容易计算的问题,如:
Membership
: 给定格基 B∈\mathbb{Z}^{m×n}
和向量 v\in \mathbb{Z}^{m}
,decide v
是否属于 \mathcal{L}(B)
。 方程 Bx=v
可以看作是 n
个变量中的 m
线性方程组。 因此,我们可以通过高斯消除来有效地解决它。 如果一个解存在,并且它恰好在 \mathbb{Z}^n
(as opposed to \mathbb{Q}^n
)中,则输出YES;否则输出NO。
Equivalence
: 给定格基 B_1, B_2∈\mathbb{Z}^{m×n}
, decide if \mathcal{L}(B_1) = \mathcal L(B_2)
。 为了解决这个问题,我们检查了两件事: B_1
的每一列都包含在 \mathcal L(B_2)
中, B_2
的每一列都包含在 \mathcal L(B_1)
中。 如果 \mathcal{L}(B_1) = \mathcal L(B_2)
,则满足这两个检查。 相反,如果满足这些检查,则 \mathcal{L}(B_1) \subseteq \mathcal L(B_2)
和 \mathcal{L}(B_1) \supseteq \mathcal L(B_2)
,因此 \mathcal{L}(B_1) = \mathcal L(B_2)
。