批处理的方法就是隔一段时间就分批处理一次积攒的数据。
一般情况下是先把数据存入数据库里,隔一段时间就从数据库获取数据
批处理的重点在于要在规定时间内处理所有数据。因此,数据的数量越多,执行处理的机器性能就得越好。
随着以后万物互联时代的来临,数据量也会成几何倍数增加。
人们需要处理从数量庞大的设备发来的传感器数据和图像等大型数据,这被称为 「大数据」 。不过, 通过使用一种叫作分布式处理平台的平台软件 , 就能高效地处理数兆、数千兆这种大型数据了 。具有代表性的 分布式处理平台包括Hadoop 和Spark 。
Apache Hadoop
Apache Hadoop 是一个对大规模数据进行分布式处理的开源框架。Hadoop 有一种叫MapReduce 的机制,用来高效处理数据。MapReduce是一种专门用于在分布式环境下高效处理数据的机制,它基本由Map、Shuffle、Reduce 这3 种处理构成
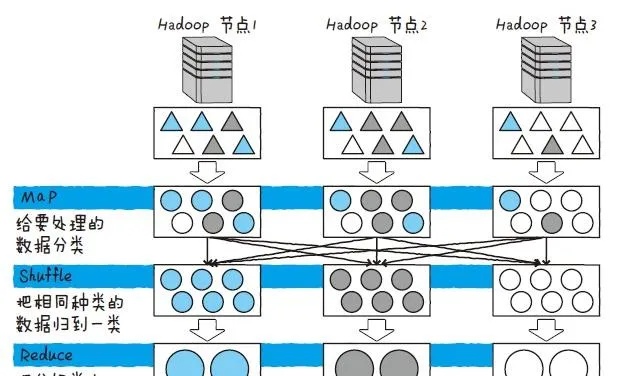
Hadoop 对于每个被称为节点的服务器执行 MapReduce ,并统计结果。首先是分割数据,这里的数据指的是各个服务器的处理对象。最初负责分割数据的是Map。Map 对于每条数据反复执行同一项处理,通过 Map 而发生变更的数据会被移送到下一项处理,即Shuffle。Shuffle 会跨Hadoop 的节点来把同种类的数据进行分类。最后,Reduce 把分类好的数据汇总。
MapReduce 是一种类似于收集硬币,按种类给硬币分类后再点数的方法。
另外,Hadoop 还有一种叫 分布式文件系统(HDFS)的机制 ,用于在分布式环境下运Hadoop。HDFS 把数据分割并存入多个磁盘里,读取数据时,就从多个磁盘里同时读取分割好的数据。这样一来,跟从一台磁盘里读出巨大的文件相比,这种方法更能高速地进行读取。如上所述,如果使用MapReduce 和HDFS 这两种机制,Hadoop 就能高速处理巨型数据。
Apache Spark
Apache Spark 也和Hadoop 一样,是一个分布式处理大规模数据的开源框架。Spark 用一种叫作RDD(Resilient Distributed Dataset,弹性分布数据集)的数据结构来处理数据
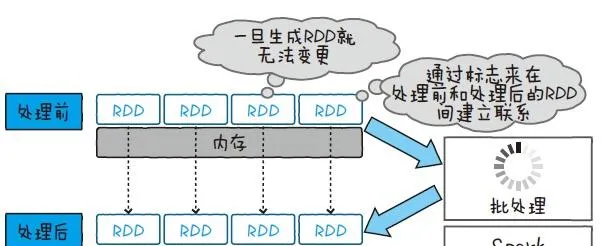
RDD 能够把数据放在内存上,不经过磁盘访问也能处理数据 。而且RDD 使用的内存不能被写入,所以要在新的内存上展开处理结果。通过保持内存之间的关系,就能从必要的时间点开始计算,即使再次计算也不用从头算起。根据这些条件, Spark 在反复处理同一数据时(如机器学习等),就能非常高速地运行了。
对物联网而言,传输的数据都是一些像传感器数据、语音、图像这种比较大的数据。批处理能够存储这些数据,然后导出当天的设备使用情况,以及通过图像处理从拍摄的图像来调查环境的变化。随着设备的增加,想必今后这样的大型数据会越来越多。











