节省显存方面,欢迎关注我们团队最近开源的工作:
个人认为这个工作把单卡训练,或者是数据并行下的显存节省做到极致了~
这里主要介绍一下单机训练上的思路。
随着模型越来越大,GPU 逐渐从一个计算单元变成一个存储单元了,显存的大小限制了能够训练的模型大小。微软的 DeepSpeed 团队提出我们其实可以把优化器状态(Adam 的 momentum 和 variance)放在 CPU 上,用一个实现的比较快的 CPU Adam 来做更新,这样既不会变慢很多,也可以明显省出来很多空间。我们把这个思想再往前推一步,我们是不是可以只把需要计算的模型参数放在 GPU 上,其余的模型参数,优化器状态都放在 CPU 上,这样就可以尽最大能力降低对显存的需求,让 GPU 回归它计算单元的本色。
为了达成这样的效果,我们就需要一个动态的显存调度——相对于 DeepSpeed 在训练前就规定好哪些放在 CPU 上,哪些放在 GPU 上,我们需要在训练过程中实时把下一步需要的模型参数拿到 GPU 上来。利用 pytorch 的 module hook 可以让我们在每个
nn.Module
前后调用回调函数,从而动态把参数从 CPU 拿到 GPU,或者放回去。
但是,相信大家能够想象到,如果每次都运行到一个 submodule 前,再现把参数传上来,肯定就很慢,因为计算得等着 CPU-GPU 的传输。为了解决计算效率的问题,我们提出了 chunk-based management。这是什么意思呢?就是我们把参数按照调用的顺序存储在了固定大小的 chunk 里(一般是 64M 左右),让内存/显存的调度以 chunk 为单位,第一次想把某个 chunk 中的参数放到 GPU 来的时候,就会直接把整个 chunk 搬到 GPU,这意味着虽然这一次的传输可能需要等待,但是在计算下一个 submodule 的时候,因为连着的 module 的参数都是存在一个 chunk 里的,这些参数已经被传到 GPU 上来了,从而实现了 prefetch,明显提升了计算效率。同时,因为 torch 的 allocator 会缓存之前分配的显存,固定大小的 chunk 可以更高效利用这一机制,提升显存利用效率。
在 chunk 的帮助下,我们的模型可以做到,CPU 内存加 GPU 显存有多大,模型就能训多大。和 DeepSpeed 相比,在同等环境下模型规模可以提升 50%,计算效率(Tflops)也更高。
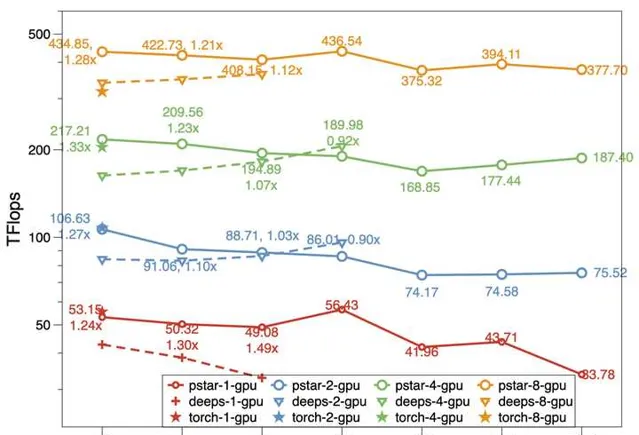
对于多卡的数据并行场景,我们扩展了上述方法,可以做到多卡中只有 1 整份模型,1 整份优化器状态,同时具备了数据并行的易用性和模型并行的显存使用效率。如果想了解多卡训练的方案,以及更详细的一些优化,也欢迎来看看我们的论文:
以上。











