transformer的細節到底是怎麽樣的?
本文梳理了所有 transformer 的技術的細節,想要了解transformer的技術細節,看這一篇就足夠了!
內容上是這樣的,以 GPT2/llama/ViT/Whisper的資訊為基礎說明
文字序列的 token 化
做為transformer 的輸入,只有一個 token 的概念。但是這個 token 是什麽呢?大部份人的咋一看的結果就是一串文字轉成一串數位,像 ascii碼一樣的東西嘛。
實際上它確實復雜一些。因為 token 到 transformer 的輸入時已經變成了一個二維的矩陣。而一個簡單的文字序列如何變成二維矩陣
一個簡單的影像如何變成二維矩陣
一個簡單的聲音如何變成二維矩陣
這些都是個問題。
文字序列的 token 化
文字的序列化是下面這樣的操作
- 文字序列根據 BPE 或者其它別的編碼方法得到 Token(你可以認為 token 是一種文字的編碼方式,一個英文單詞編碼在 1~2 個 token, 一個漢字編碼是 1~3 個 token,每個 token 都是一個數位)
- Token 透過查表直接得到 Embeding的矩陣(這個表通常非常大 ,比如GPT3 可能是 12288x4096, 12288是 token 個數,4096 是維度,也就是每個 token 查表後有 4096 維,這東西也是訓練出來的)
- Token 透過 Postion 計算 Positional Encoding(標準演算法公式)
- 將 Embedding 與 Positional Encoding 相加得到 Transformer的輸入

Token 的查表結果
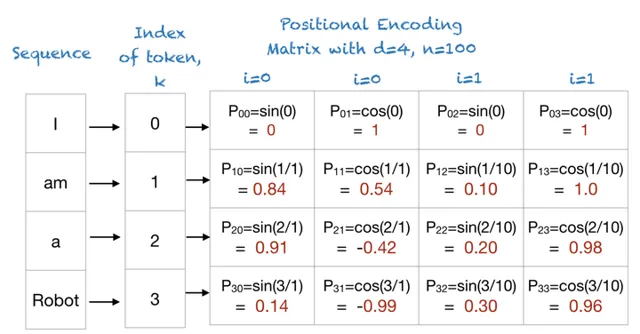
Token 的 Positional Encoding 結果,它的計算公式如下。
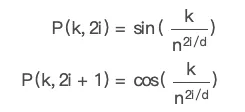
上面只是講了 transformer 的輸入的 token 如何生成這一部份,你可以感覺到,其實這東西的細節還是不少的。如果你真的想透過學習 大模型/LLM 的知識來達到學習知識、增加職業競爭力,我比較建議你聽聽知乎知學堂推出的【程式設計師的AI大模型進階之旅】,非常適合想學大模型的學員。課程適合有一定編程基礎的程式設計師,邀請了圈內知名的ai大牛授課,趁著現在還免費,我建議你看看⬇️
別忘了添加助教領取上課的課件,這對於快速入門大模型,跟老師深入溝通還是比較有幫助的。
影像的 token 化
影像的 token 化也比較簡單,它就是直接分割成小塊,通常是 16x16, 再按順序排好,然後把它們加個位置編碼就好了。
看下面這張圖,它就是把一個圖片如何搞成了 token,然後再輸入到了 transformer。
在這裏,圖片被切割拉平後,是直接扔到一個 CNN 網路裏搞成 Transformer 的輸入部份的。
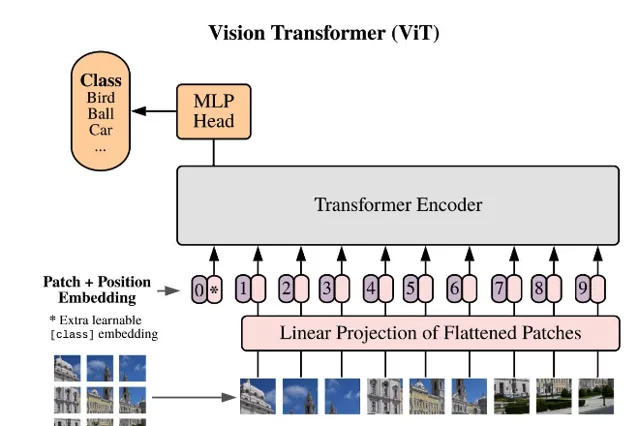
聲音的 token 化
可能聲音的 token 化是最簡單的,因為它天生就有二維特殊,mel 譜數據。
以 openai 的 whisper 計畫為例,它的聲音輸入的 token 就很簡單。每 30ms 一個,80 個log mel 譜數據。這樣只要不斷的切段,這個聲音就直接變成了二維矩陣了。差不多類似下面的東西,
但是它有位置編碼嗎?當然也有了,它的核心 Positional Embedding 演算法是下面這個。
在正式解釋 Transformer 前,全圖鎮樓
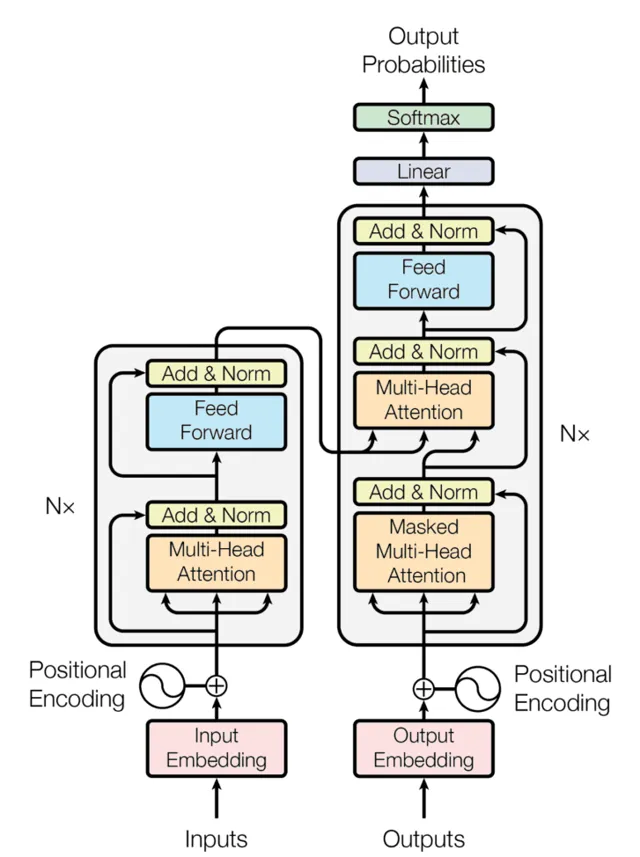
encoder 實作
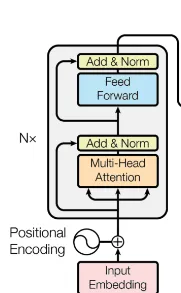
對於 encoder 來講,它的核心是Attention 機制。了解了它你就了解了整個 transformer 世界了。在 Attention 機制的基礎上又透過多頭機制,把它擴充套件成了 Encoder 的核心部份。
下面這張圖是最核心的 Scaled Dot-Product Attention ,請一定要弄懂它。
Scaled Dot-Product Attention

這裏的 Q 、 K 、 V 都是分別 有一個訓練後的矩陣與上面講的 Embedding+PositionalEncoding 的結果相乘後的數據。在 Encoder 裏是沒有 Mask 的計算的,它是用於 Decoder 部份的。
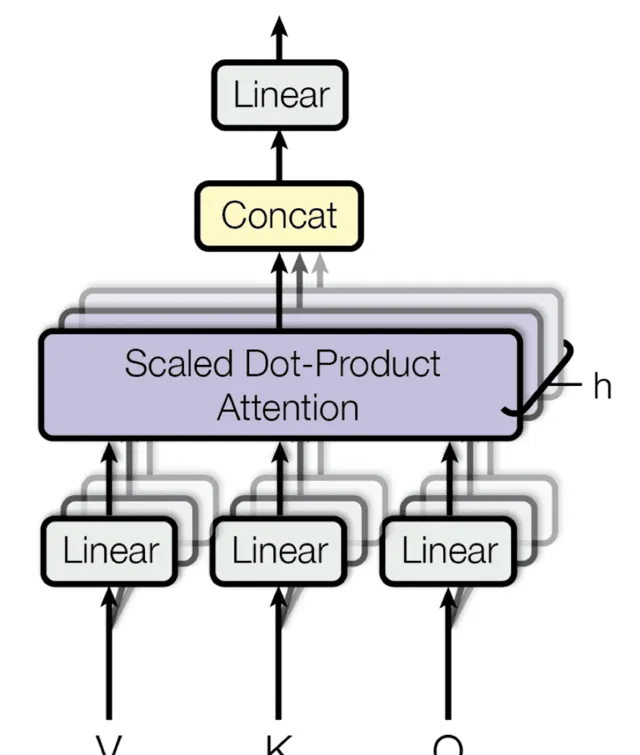
MHA/Multi-Head Attention
再然後用Scaled Dot-Product Attention 組成了下面的 MHA/Multi-Head Attention 。
這樣,透過 MHA結構再加上 Add&Norm 及 Feed Forward(一個標準的 MLP 網路),然後再用 Add & Norm 就得到了一個 Attention 塊。這樣的 N 個串連處理後,就能得到 Encoder 部份。
Encoder全部
decoder 實作
decoder 與 encoder 相比,它的計算方式的變化是增加了一個可選的 mask,同時它的輸入有一部份是直接來自於 Encoder 的, 而另一部份 則是來自於自身的輸出的不斷SHIFT,也就是輸出部份不斷的向右移增加 的輸入部份。下面這個圖的 Decoder 部份就比較好理解了。
Mask 實作
那就有一個問題 mask 在什麽時間使用,它的實作方式是什麽。
實際上 Mask 與輸入是相對應的,Outputs 的長度與 Mask 是互補的。
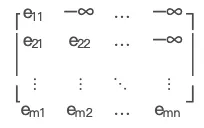
它的實際計算是透過 masked_fill(mask==0, -1e9)類似這樣的一段程式碼實作的。因為 Outputs 以外的 Embedding 數據是會被寫成全「0」的,把它再填 成一個極小值 -1e9 後,這個經過 softmax 計算時,這些數據就會變成近似於 0 的極小數。
相信你看了 Encoder 的計算方式,是一定會很容易理解 Decoder 這一部份的。
不過請相信我,一定要自己動手寫一下,才會真的理解這個模型有多好玩!
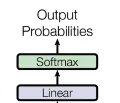
output 實作
這個大概是所有的工作裏最簡單的,只要最後用個Linear 層,再用個softmax 就可以得到 token了,那自然再反查一下 BPE 編碼(如果我們是這麽用的),那就有了結果了不是?
也就是下面這一點兒圖了。 不過不要看它在圖裏占的小,這個實際上是一個巨大的查表輸出,因為 Softmax 與 Token 表的大小是一致的。也就是你的每一次計算輸出的是巨大一維陣列,以 GPT3舉例 可能是 12288, 12288是 原來token編碼的詞表大小。現在你可以查到這裏對應的 Token 了吧!
flash attention 最佳化
做為最近出現的,馬上就迅速實際套用的 Transformer 最佳化,可以說是最近針對 transformer 的最佳化最正確的方向,它的目標極其明確,盡可能的最佳化顯卡的計算使用方式,最大化計算最小化數據傳輸,同時不改變任何原來的網路結構,只要你簡單的替換掉 transformer 的傳統計算就成了。
單純的看這個圖就能看到作者的大方向的思路,從整體的角度去最佳化這個 Attention 機制。大家在談一個模型的快慢時,經常談到的就 算力,是 FLOPS, 是 flops,是 TOPS,但是很多人並不知道,現在的芯片經常碰到的問題是,算力比 IO 快好多,經常處於算力在等待的狀態,也就是 訪存比高 。所以最佳化演算法,去最佳化它的算力,遠沒有最佳化它的 IO 能得到更好的整體效果。
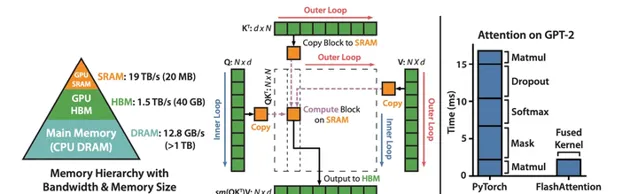
單純的看這個圖就能看到作者的大方向的思路,從整體的角度去最佳化這個 Attention 機制。大家在談一個模型的快慢時,經常談到的就 算力,是 FLOPS, 是 flops,是 TOPS,但是很多人並不知道,現在的芯片經常碰到的問題是,算力比 IO 快好多,經常處於算力在等待的狀態,也就是 訪存比高 。所以最佳化演算法,去最佳化它的算力,遠沒有最佳化它的 IO 能得到更好的整體效果。
如果大家有興趣可以看另一個回答:
https://www. zhihu.com/question/6020 57035/answer/3297728852
streaming llm 最佳化
這是我看到的最鼓舞人心的方向,它非常好的解決了 基於transformer 的llm 的視窗問題,可以讓視窗無限大。也就是有可能實作類人的智慧世界 。
在大方向上,這個 streamingllm 是找到了一個 token 的有用的特征:sink token 。 就是找到在 softmax 時得分最高的 token,實際上也應該是相關性最好的那一個(好像通常是第一個)。這樣就能只靠很少的 token 就能保留歷史資訊,而有了足夠的歷史資訊就能很好的保證你的持續輸出了不是?
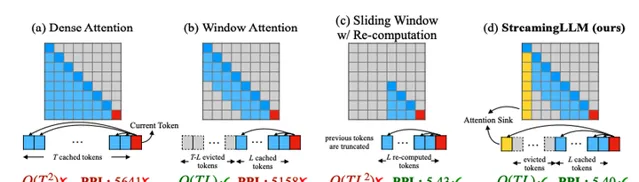
不得不說這個方向確實特別吸引我,我要好好研究一下,然後再寫一篇文章。
參考
[1]streaming-llm https:// github.com/mit-han-lab/ streaming-llm
[2]flash attention https:// github.com/Dao-AILab/fl ash-attention
[3]openai whisper https:// github.com/openai/whisp er
[4] Transformer Implements from scratch https:// github.com/hkproj/pytor ch-transformer.git
[5] llm visulation https:// bbycroft.net/llm











