問題不太明確,我來分情況討論一下。
1. 機器人指的就是現實中的機器人產品
既然這種機器人發出的聲音聽起來不像真實的,那就說明它不是把語音預先錄制然後播放(比如「倒車請註意」),而是用語音合成技術來生成語音的。
語音的音高,是由「基頻」決定的。在語譜圖上,語音看起來是「排骨」狀的,每一根骨頭叫做一個「諧波」,相鄰諧波的間隔就是基頻。比如, @曹力科 回答中「黑化肥發灰會揮發,灰化肥揮發會發黑」的語譜圖就是下面這樣的。註意「黑」這種一聲字的諧波基本是水平的,而「化肥」這種聲調有升降的字,諧波也有升降。
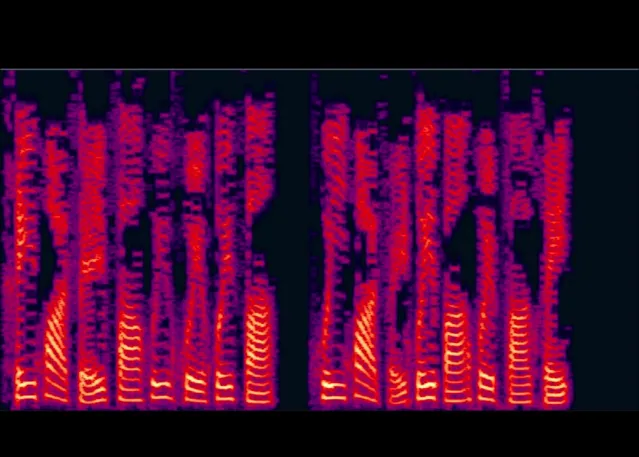 化肥繞口令——原始音訊
https://www.zhihu.com/video/1206916879530635264
化肥繞口令——原始音訊
https://www.zhihu.com/video/1206916879530635264
要根據文本生成基頻的變化,並不是一件容易的事,對於早期的語音合成來說更是這樣。如果一個合成語音聽起來全是一聲,那麽就很有可能它根本就沒有去建模基頻的變化,而是偷懶把基頻設定為常數。這樣的語音的語譜圖上,就全是水平的諧波了。
2. 機器人指的是影視作品中的機器人
在影視作品中,為了給機器人賦予一種「非人感」,常常會對預先錄制的真人聲音進行處理。
@曹力科 的答案就給出了一種處理方法,其中關鍵的步驟就是:把原始語音延遲若幹個不同的時間,然後疊加。他采用的參數為:總共疊加 10 份,最小延遲為 500 個采樣點,最大延遲為 2000 個采樣點。他使用的語音取樣率是 16 kHz,那麽相鄰兩份的時間差就是:(2000 - 500) / 9 / 16000 = 0.0104 s = 10.4 ms。
為什麽這樣處理會產生「都是一聲」的聽感呢?這就需要用到訊號處理裏的這個結論了: 時域重復等於頻域采樣 。在時域上每隔 10.4 ms 重復一次,相當於在頻域中每隔 1 / (10.4 ms) = 96 Hz 采一次樣。這其實就是用 梳狀濾波器 對語音進行濾波,梳子的齒所在的頻率都是 96 Hz 的倍數。濾波的效果如下面的視訊所示:梳狀濾波器會破壞掉語譜圖原有的諧波結構,而生成一套新的諧波結構,相鄰諧波的間距都是 96 Hz。你看,基頻變成常數了——所以語音聽起來就「都是一聲」了。
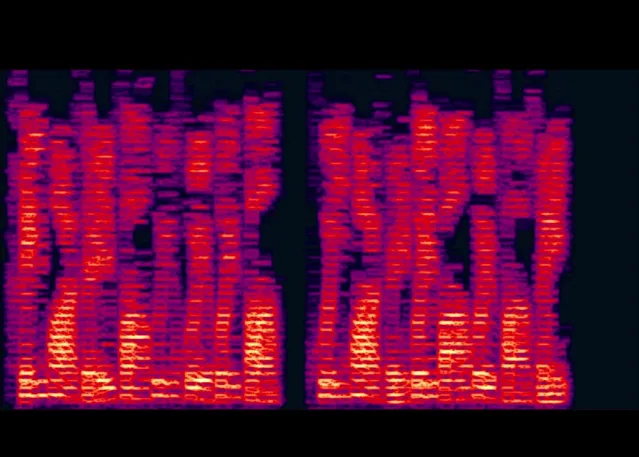 化肥繞口令——疊加後的音訊
https://www.zhihu.com/video/1206917660287811584
化肥繞口令——疊加後的音訊
https://www.zhihu.com/video/1206917660287811584
這種處理方法完全是人為的,並不需要用「增強無線傳輸語音的可靠性」來解釋,因為:









