作者:何建軍 王國政|零跑科技
關於零跑
浙江零跑科技股份有限公司(leapmotor)作為一家科技型企業,是國內極少數擁有智慧電動汽車完整自主研發能力並掌握核心技術的新能源汽車廠家,由浙江大華技術股份有限公司及其主要創始人共同投資成立,始終堅持核心技術的全域自研,為使用者的出行和生活創造最大價值,致力成為值得尊敬的世界級智慧電動車企品牌。
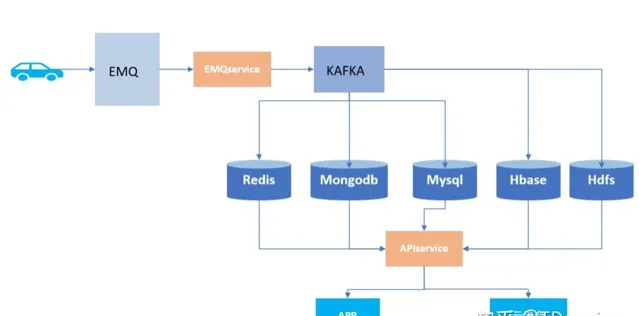
一直以來,在數據儲存上我們的選擇都是MongoDB和HBase,但是隨著業務的加速擴張,寫入速度太慢、支撐成本過高等問題也逐漸顯現,具體來說,主要有以下幾處痛點:
從降本增效的角度考慮,我們決定在C11新車型上試用下其他的資料庫,在分析數據特點後,最終確定采用時序資料庫。但市面上時序資料庫產品眾多,之所以選擇TDengine,一是由於它比較突出的效能和成本管控能力,其次也是由於我和它的一些淵源。
為什麽選擇TDengine?
在接觸一個新的資料庫產品時,通常大家比較關註的無非就是兩點:效能強、成本低,這也是我們選擇TDengine的主要原因。
另外和TDengine的淵源要追溯到我的上一份工作,那時我對它就有過一些比較深入地了解,進入零跑要進行時序資料庫選型時,發現大家都沒有接觸過,心裏也都挺沒有底的,我就把這段經歷講了出來,包括對TDengine的一些看法和見解。
我有多年大數據行業的工作經驗,在了解到時序資料庫後,也對市面上一些流行產品如OpenTSDB、InfluxDB都進行了一些調研。 對比之後發現TDengine是專門針對物聯網、車聯網業務場景去設計的,在解決這些行業數據問題上更有針對性,它不僅安裝包很小,對集群資源消耗也很少,並且它創新的「一個數據采集點一張表」的數據模型,特別適合物聯網這種多裝置且資訊量儲存非常大的數據場景 。
因為有我之前的實踐佐證,大家一致覺得這款資料庫相對會更有保障,在各方的大力推動下,我們就開始搭載TDengine運作新業務了。
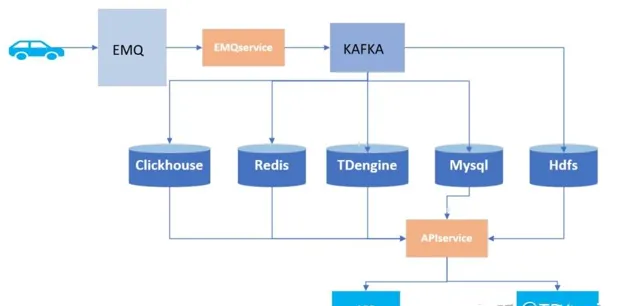
在搭載了TDengine之後,我們收獲了以下的四點進步:
存在的問題和最佳化的空間
當然問題也是不可避免會存在的,對於我們來說TDengine是一款很新的資料庫,相比較而言HBase肯定會在使用上更加穩定一些。我們的業務場景數據列本身就比較寬,有3000多列,而TDengine之前都是針對幾十列。此外,還存在因開發集群時鐘不準導致集群頻繁重新開機、因數據量太大導致查詢報錯、連線資源超時等諸多在實際落地時遇到的問題。
但我們並不認為遇到問題就要一棍子打死,相反願意給TDengine時間去進行最佳化。因為使用模式不一樣,肯定會遇到諸多問題,如果基於此就放棄使用的話,那這款跟物聯網場景非常契合的資料庫就要和我們擦肩而過了。TDengine失去了一個經典的套用場景案例,我們也會因此失去一個更好的選擇。
在TDengine小夥伴的支持下,上述問題也得到了很好的解決。我們前期使用taosdemo工具進行插入效能的測試,能達到200萬每秒的入庫效能。在查詢這塊,因為都是內部使用者在使用,雲平台查詢並行並不高,所以沒有進行非常深入的測試,其查詢效能也能完美匹配我們的需求。
此外,在副本構建上他們也從專業角度給出了一些建議,我放在本文中,給有同樣問題的同學們一些參考:
具體選擇幾個副本還是要看讀寫比,從現有架構出發的話,寫入效能要求更高,兩副本加一個冷備會相對更穩妥一些;之後如果查詢效能要求提上來了,可以考慮擴充成三個副本,三副本下讀的效能以及並行能力會比兩副本更強,因為最終的需求還是滿足線上的即時業務,而不是數倉型業務。所以此時雙副本和三副本的體驗差別不大。
零跑+TDengine的未來展望
早在2018年我就開始關註TDengine了,到2021年它已經發展了三年時間,相對來說也變得更加成熟和穩定了,也因此我們選擇了它,而它也真的在幫助我們節省成本、提高速度。
當然如果我們選擇市面上其他的資料庫產品的話,可能也能勝任,但是卻很難達到這樣一種效能和成本的最佳化。 尤其我們做的是汽車這樣一種產品,數據量之大難以想象,如果沒有一款能夠實作高效儲存的資料庫,伺服器成本會非常的高。這從執行節點的數量上就可窺一二,如果使用HBase,估計需要建立十多個節點,而搭載TDengine的情況下三個節點就能搞定,節點少了運維起來自然也會變得更加輕松一些。
目前我們的數據會在TDengine上存半年,另外每天都會同步到數倉進行為時兩年的儲存。大部份涉及到APP、雲平台的業務,像車速、溫度、充電使用情況、電池健康度等訊號值現在都是儲存在TDengine上。此前使用MongoDB進行業務處理時,需要先將數據存到MongoDB文件中,稍顯復雜,現在使用TDengine可以直接進行提取展示。對比來看,TDengine在達到我們預期的前提下,在使用上也更加方便。
在未來的規劃中,我們希望能夠引入TDengine的使用特性到更多的業務中去,比如說熱更新、溫度曲線、測速曲線、電極轉速等,用更多新的特性減少客戶端CPU的消耗,也期待TDengine有更多更好的功能加入。











