論文【Image Captioning:Transforming Objects into Words】NeuralPS 2019-yahoo research傳送:
論文程式碼:
這篇,是想看看Image captioning咋用transformer的。
一句話說論文的主要內容:
Propose a new model named Object Relation Transformer , incorporates information about the spatial relationships between input detected objects through geometric attention .在standard Transformer模型基礎上,對已經辨識出來的物體設計一個「幾何註意力機制」,使得模型能夠在對影像編碼的過程中考慮到物體在空間上的相對資訊。這個模型叫「Object Relation Transformer」。
這裏需要指出,原本image captioning任務的pipeline就是Encoder-Decoder:
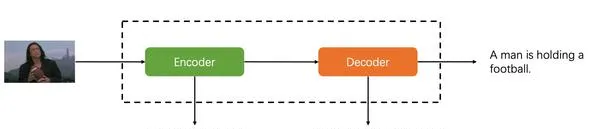
所以,Transformer很自然可以用到這個任務裏,並不算一個大的idea創新,只能說Attention確實是all you need。
對於這篇論文來說,創新點主要在於cv方面,即Encoder。更細節的說,在於Encoder中的self-attention機制的改進。咋改的呢?
為了考慮圖片中的spatial information,設計了geometric attention。(重點)下面來從論文的整個實作流程來具體解析:
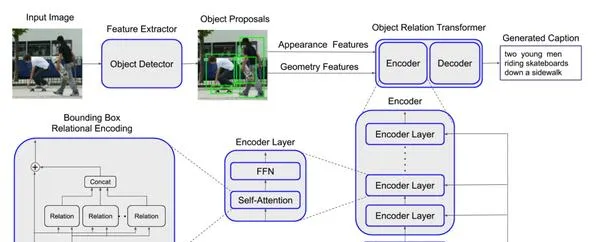
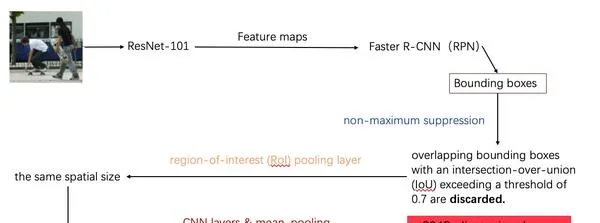
這是對圖片提取特征和物件辨識的過程:
- 首先使用摺積網路ResNet-101對圖片做一個特征提取,得到feature maps。
- 使用Faster R-CNN的RPN對feature maps做一個物件辨識,得到bounding boxes。(候選框)
- 對這些得到的bounding boxes使用最大值抑制(non-maximum suppression)對辨識出來有IoU(物件辨識的一個準確率評價值)閾值超過0.7的重疊bounding boxes剔除。(這一步做的是這個意思:對於圖片中的同一個物件,電腦可能辨識出很多個bounding boxes,但我們不能所有都留下,只選取辨識準確率最大的那一個,其他與這個重疊過高的都刪去。)
- 使用一個池化層將所有的bounding boxes變為同樣的spatial size。
- 再使用CNN layer和mean pooling再對bounding boxes做進一步的提取,最終得到2048維度的feature vectors用來表示每一個bounding box。輸入到transformer的Encoder中。
這裏feature vectors實際上是圖片每一個bounding box的appearence features(2048維),而我們實際上從object detector裏面還獲得了geometry features,對於每個bounding box的geometry features是一個4維向量:
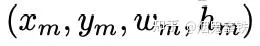
首先將上一步的appearence features輸入Encoder的embedding層,將維度從2048降到512,接著跟著一個ReLU函式和dropout層,才輸入到Encoder layer。論文裏encoder layer共有6層。
走到這裏,進入self-attention還是先按照自註意力的規則進行,得到
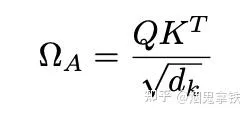
ΩA 是一個 N × N attention 權重矩陣, ω mn A 表示第m個和第n個token之間的註意力權重。
上一步得到了ΩA ,下面要解決的問題就是:
怎麽讓模型考慮到圖片中物體的空間資訊(spatial relationships)?
論文的方式就是:使用geometry features對ΩA進行改進。
- 首先學習一個函式對geometry features進行變換:
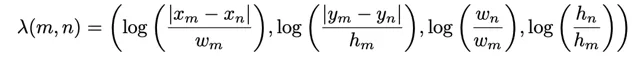
2.計算求得geometric attention weight:
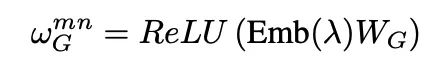
3.將geometric attention weight融合到attention機制中:
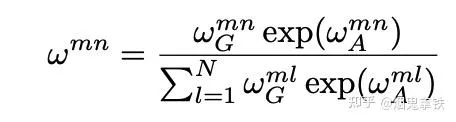
4.得到多頭註意力機制結果:

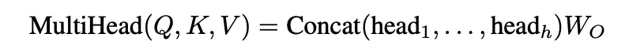
後面進行的步驟就是常規Transformer的步驟了。
參考文獻:
1.【Relation-Networks-for-Object-Detection】:https:// github.com/msracver/Rel ation-Networks-for-Object-Detection
2.【Attention is all you need】:https:// proceedings.neurips.cc/ paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf










