更新:这篇答案有一点过时了,大体框架和想法供参考。
以前做过一些机器学习的东西,主要是经济类的,因为当时不太确定数据背后的结构和内在规律,同时又想数据可视化,所以用了SOM (Self-organizing Map, unsupervised)这些基本的机器学习方法,结果确实很有启发性。部分分析与截图可参考:从事经济、金融工作的人都是通过什么渠道获得数据资源,运用什么软件来分析行业状态和经济走势的? - 钱粮胡同的回答
背景: 法兰克福某行做Portfolio Management,工作上跟各类经济,行业,企业等数据打交道,再之前做过企业评级和信贷业务,所以时不时就会想把机器学习的一些东西应用到工作上。当然,银行里这些略有创新/ 实践的想法基本都会被上面打回来,图样图森破。
讨论部分: 跑题了,直接讨论下可行性:其实这方面国内国外都有一些研究文献(针对中小企业信用评级/违约概率预测),主要是利用比较传统的multi-layer back-propagation neural networks, 用已知结果的样本反复培训,再用另一部分样本做实测,防止overfitting等等,我也做过一些。下图是个基本原理,摘自网络(TeX - LaTeX Stack Exchange):
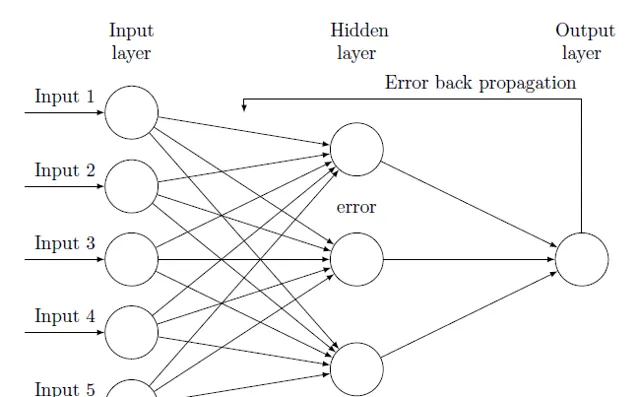
首先,我们要清楚神经网络(类人工智能) 的分析有很多种,比如你是想做clustering(评级分类,如AAA, AA, BB, CCC等),还是想预测具体违约概率。对于PD,我想比较适合的是预测具体数值吧?长时间这些数值的积累与变化,画成图,就像是企业的生命线。
我们先看一下传统的企业信用评级,方法很多,但是大同小异 (可以参看标普关于评级的网站:Understanding Ratings), 基本分财务与非财务 :
企业信用评级简要框架:
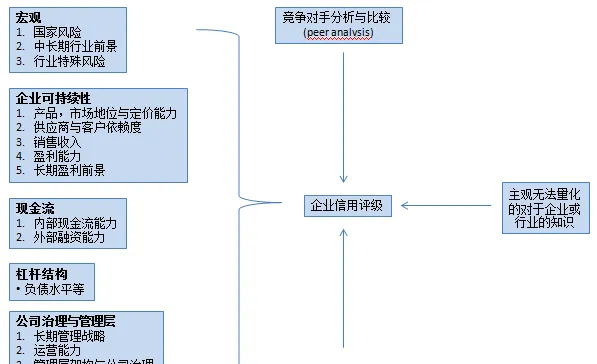
我个人感觉,企业违约概率/ 信用评级其实一般模型就可以做(相关文献也比较多,如SVM,PCA,甚至最基本传统的数学模型),如果要用机器学习的话,一定要找到突破点。我觉得优势应该是寻找大规模量化的数据中潜在的规律或结构,优化预测结果。如果可以通过如unsupervised的学习方法来获得(或者就是supervise中培训模型的时候,告诉模型结果然后反复培训 - 其实就是在不知不觉中让机器寻找数据背后的结构区别),应该是很有价值的。
泼冷水时间: 从银行角度来看,个人信用评级和中小企业信用评级,再到大型企业评级(简单的企业分类可以按照企业的销售额与总资产等指标,如果复杂一些,这方面本身就可以用机器学习:比如用ANN中clustering的方法,如之前提到过的SOM,或者非ANN中传统的K均值),区别还是蛮明显的,尤其企业类评级一般量不大(相比retail),同时数据比较滞后,源少,这个方面我觉得如果想使用机器学习的话需要找到非常好的理由与突破口,否则就有点成心显摆的感觉(就好像有些任务,明明简单的用excel的pivot功能就可以很好的完成,非要用VBA或者R,意义不大)。
冷水泼完来点热水: 很多同行说银行内部的评级要独立(假设这么有节操的银行用的是高级评级法),与信贷业务的考虑尽量分开。我认为,在评级过程中,企业信用本身与周边宏观环境确实决定了违约的概率 (forward looking),保持独立性很好,但是如果把信贷业务中交易等环节的动态有时效性的数据也加入到评级分析中(企业与银行之间交易的行为数据),那么很有可能提高评级的时效性与准确性,而这个方面就需要高度的自动化与数据挖掘。所以这个领域前景还是很广阔多变的。
One more thing: 今天工作,突然想到机器学习的一个优势之前没有说到:平常做企业分析,行业内类似企业的对比分析 (peer analysis)很重要,而这一块根据我的经验,很多分析师容易疏忽,或者一些junior因为对行业的理解不到位,导致peer的选择不对,影响最后分析结果的正确性。如果采用机器学习,数据结构的探索本身应该就可以一定程度上解决这个问题。
先回答到这里,主要觉得这个问题结合的比较贴近我的工作,有兴趣的话再讨论。











