主要的深度学习系列算法有DBN, ConvNets, RNN等,基本上经典的深度学习算法都用过。
详细请看唐路路(研究方向 深度学习 3D重建)在专栏 机器学习&深度学习--学术水准的理解 总结的文章 深度学习在3D重建上的应用
近年来Deep Learning在计算机视觉上的应用主要在2D image 的detection,segmentation, classification等方面,感觉已经快无孔不入了。但是DL在3D scene上的研究相对还较少,比如3D reconstruction or 3D modeling。因此,今天我想浅谈下image-based 3D reconstruction.
具体来讲,image-based的3D重构算法可以描述为当给定某个物体或场景的一组照片时, 在一些假设条件下,比如物体材料、观测视角和光照环境等,通过估计一个最相似的3D shape来解释这组照片。 一个完整的3D重构流程通常包含以下几个步骤:
1)收集场景图片(Collect images);
2)计算每张图的相机参数(Camera parameters for each image);
3)通过图组来重构场景的 3D shape(几何模型)以及其对应的相机参数;
(Reconstruct the 3D geometry of the scene and corresponding camera parameters.)
4)有选择的重构场景的材料等(Optionally texture the reconstructed scene.)。
(Image source:Multi-View Stereo: A Tutorial, by Yasutaka Furukawa from Washington
University)
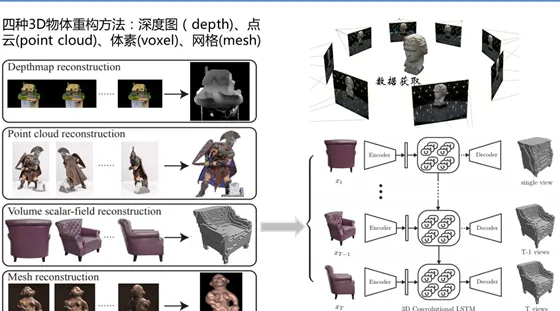
其中最核心的工作是第三步:3D shape的重构算法。常规的3D shape representation有以下四种:深度图(depth)、点云(point cloud)、体素(voxel)、网格(mesh).
近年来,基于Deep learning 的3D reconstruction 也逐渐火热起来, 例如David EigenNIPS2014上的文章 「 Depth Map Prediction from a Single Image using a Multi-Scale Deep Network 」,以及Fayao Liu 在CVPR2015上的文章「 Deep Convolutional Neural Fields for Depth Estimation from a Single Image 」。两篇文章都是利用CNN网络结构学习预测 a single image与其对应的depth map 之间的关系。然而我个人觉得depth image 还不足以解释重构原始input的信息,它只能作为3D scene understanding的一个辅助信息。 因此,一些学者开始研究利用一组二维图来重构3D 点云图或voxel以及mesh图,这里就不详细展开了。
个人觉得基于deep learning 的3D 点云和mesh重构是较难以实施的,因为DL学习一个物体完整的架构需要大量数据支撑。然而传统3D模型是由 vertices 和 triangulation mesh 组成的,因此不一样的data size造成了training的困难。所以后续大家都用 voxelization(Voxel)的方法把所有CAD model转成binary voxel 模式(有值为1,空缺为0)这样保证了每个模型都是相同的大小。
早期的voxel-based 三维物体重建代表作有 3DShapeNet (http:// princeton.edu ) ,它采用Deep Belief Network (DBN)来学习 voxel 的 probabilistic embedding 然后在给带有2.5D信息的图片后,通过 Gibbs Sampling来不断预测他的 shape class 和填补他的未知voxel以完成3D模型重建。
后续又有CMU的paper 「Learning a Predictable and Generative Vector Representation for Objects」 ,利用auto-encoder 学习3D Model 的 embedding, 然后通过 ConvNets学习一个 deterministic function 让其 rendered image infer 到学习到的 embedding 上。因为 auto -encoder是generative的,对于新的test image,模型就会infer 到相关的3D model embedding,再通过decoder生成其相应的 3D model。
同类型的工作还有Choy 在ECCV2016的一篇文章 「3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction」。 采用深度学习从2D图像到其对应的3D voxel模型的映射: 首先利用一个标准的CNN结构对原始input image 进行编码; 再利用一个标准 Deconvolution network 对其解码。 中间用Long Short-Term Memory(LSTM是RNN中的一种)进行过渡连接, LSTM 单元排列成3D网格结构, 每个单元接收一个feature vector from Encoder and Hidden states of neighbors by convolution,并将他们输送到Decoder中. 这样每个LSTM单元重构output voxel的一部分。 总之,通过这样的Encoder-3DLSTM-Decoder 的网络结构就建立了2D images -to -3D voxel model 的映射.
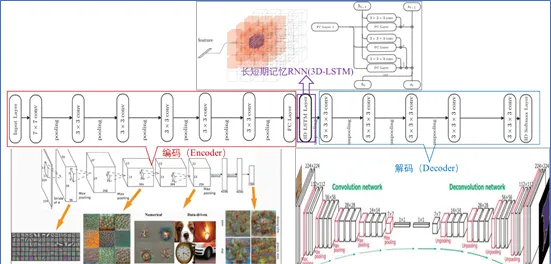
但是,由于3D voxel是三维的,它的resolution成指数增长,所以它的计算相对复杂,目前的工作主要采用32*32*3以下的分辨率以防止过多的占用内存。 但这使得最终重构的3D model分辨率并不高, 也可能catch不到一些常规的结构(比如对称性、直线、曲线等),离真实物体还有较大差距。在DL如此火热的今天,如何将其更好的应用到3D reconstruction(3D重构) 或3D modeling(3D建模)上确实值得我们进一步深入研究。例如考虑如何提高voxel model 的分辨率; 如何选择best view 和最少的 view来重构3D物体;如何利用mesh 或point cloud来直接重构3D物体等。但由于mesh 和point cloud是不规则的几何数据形式,因此直接使用CNN是不可行的。但是可以考虑将3D mesh data 转化为graphs形式,再对3D曲面上的2D参数进行卷积。具体方法有Spatial construction (Geodesic CNN)和Spectral construction (Spectral CNN)。基于point cloud的方法,可以参考大神Hao Su的CVPR2017文章「PointNet: Deep Learning on Point Sets for 3D classification and Segmentation」和「A Point Set Generation Network for 3D Object Reconstruction from a Single Image」。 但是基于mesh和point cloud的方法总的来讲数学东西多,而且细节恢复上效果欠佳。不过可以考虑结合voxel来提高重构精度。这里就不啰嗦了,有兴趣的留言交流。若有理解错误的也欢迎指正,谢谢!











