一句話簡單回答——就是 至少目前人類還沒有找到一條通往AGI的可行路徑,大語言模型這條路徑所體現出來的人工智能,看起來可行性最高。
自從大模型爆火之後,我周圍很多研究機器轉譯十多年甚至幾十年的朋友都在感慨,NLP經歷了規則、統計和神經網絡的三個階段,篳路藍縷,終於迎來了最黃金的時期。但,GPT的出現,並不等於機器就具備了「智能「」智慧「。因為要做出可解釋、有知識、有道德、可自我學習,能準確進行推理的NLP系統,實際上是一個很高的目標,現在我們還離得很遠。
所以,首先我們來討論一下到底什麽是自然語言。
人類的自然語言
這是個很難定義清楚的概念。
本質上,語言的出現是為了人類之間的溝通(我們當然希望電腦能全部擁有人類的視覺、聽覺、語言和行動的能力,但語言是人類區別於動物的最重要的特征)。所以從這個意義上來說,研究自然語言,其實就是在研究如何讓機器擁有更多的「認知智能」。
機器理解人類的語言很難嗎?很難。
別看我們天天說話,聊八卦看新聞,看似輕松得很,但對電腦來說,人類的自然語言是非常難掌握的。這是因為人類語言最大的問題,就是知識表示的規則模糊性和歧義性。畢竟人類語言不是工程師設計出來的,而是人類發展過程中,「眾約俗成」變成固定詞匯和語法——沒什麽道理可言——說的人多了,大家就都認可了。
這種集體參與的結果,就是語詞的含義和它們的使用規則,都非常不統一。一詞多義,一義多詞,在實際生活的使用場景中非常常見。
先看下面號稱「中文十級」的兩句話:
* 校長說:「校服上除了校徽別別別的,讓你們別別別的,別別別的,非要別別的。」* 來到楊過曾經生活過的地方,小龍女動情地說:「我也想過過過兒過過的生活」
再來看下面這句含有「歧義性」的中文語言表述:
第一場,中國女排隊大勝美國隊;第二場,中國女排隊大敗日本隊。請問:中國女排隊贏了幾場?上文中女排的「大勝」和「大敗」,指代的都是「贏得比賽」這一個意思。這個指代雖然有點微妙,但根據上下文,我們還是能比較容易地做出判斷。而想要電腦要做到這一點,那可就難得多了。
此外,人類的自然語言, 除了歧義性之外,自然語言處理面臨的難點還包括抽象性、組合性、前進演化性等。
所以從人類語言本質內容的角度來講, 自然語言處理屬於認知智能,理解它、掌握它,就需要機器具備很強的抽象和推理能力,也因此,說「自然語言是智能的載體」,是完全說得過去的。
電腦演算法的局限:理解自然語言
現階段電腦上的所有行為,說到底,都可以轉換為
數學和邏輯運算
。如果把電腦的行為抽象出來看,就是輸入、計算、輸出。
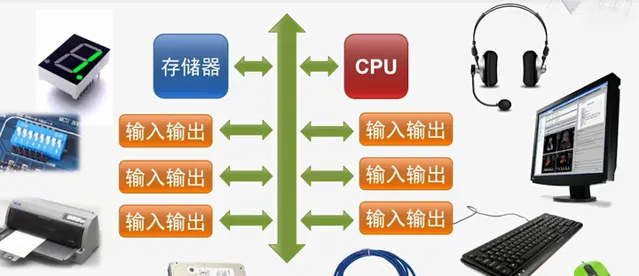
為了讓電腦模仿人類思維、理解人類自然語言,人們先是發明了編程。比如,在馮諾伊曼電腦上,工程師編寫各種處理規則。類似於:「小球如果碰到墻壁,就彈回來」,這些場景需要人類寫出不同的程式來表達。
雖然這種解決問題的方式有點「笨笨的」,但只要程式能執行起來,還是能提升了很多工作效率。

不過比較無奈的是,現實中的問題總是千變萬化。你寫的某個程式能讓「小球如果碰到墻壁就彈回來」,但當拿到真實的套用場景中的時候,你往往會發現,電腦讓小球碰壁彈回來後,小球可能還會向另一處懸崖滾下去,然後粉身碎骨。

於是,工程師不得不使勁編寫更多的程式,來彌補各種漏洞(Bug),以便讓電腦學會應付各種可能的變數。
但變數無窮盡,而人力、時間有窮盡,在不斷動態發展的世界中,漏洞是永遠補不完的。
退而求其次,人們轉而教電腦某個單一技能。比如下棋。但如果電腦只會下棋這一件事,在實際生產生活中也沒太大的作用。
於是有人想:咱們是不是應該改個路子,讓電腦模仿人類的大腦不就行了嗎?
這個研究開始很讓人驚喜,因為人們發現,人腦的基本工作單元是神經元,也就是神經細胞。而神經細胞用的是二進制!
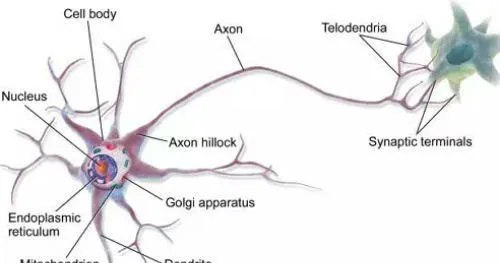
科學家很興奮,打算用電子元件模仿神經元,做出「人造大腦」。理論上說,我們造出一個神經網絡,就像一個初生嬰兒的大腦,那麽我們可以人類所有的已有知識都輸入給它,讓它像嬰兒一樣去探索世界。如果能實作這個目標,那麽人工智能就不再只局限於某個單一技能了。
但很快科學家發現,人類的大腦實在太神奇了。「看,那是只狗狗!」,小朋友一句看似非常簡單的判斷,實際上需要大腦做千萬次運算。人類大腦只有一公斤多一點,小這麽個小小的東西,運算速度卻是電腦不可企及的。
就像之前人類想要飛上藍天,期望透過模仿鳥的飛翔來制造飛機,卻一直沒能成功,直到喬治·凱利提出空氣動力學才迎來了轉機。研究自然語言處理的早期科學家,也走過類似「鳥飛派」的彎路:他們試圖讓電腦透過模仿人的大腦來理解自然語言的含義,結果導致從上世紀50年代到70年代的研究成果寥寥。
但1970年以後「統計語言學」的出現,終於讓自然語言處理發生了轉機:費德烈·賈裏尼克和他領導的IBM華生實驗室,把自然語言分析變成了一個簡單的數學問題——一個統計模型,即統計語言模型。他的出發點很簡單:一個句子是否合理,不需要再分析語法和語意了,只看它的可能性大小就可以了。
2005年後,隨著Google基於統計方法的轉譯系統全面超過基於規則方法的SysTran轉譯系統,徹底將基於規則的自然語言處理方法消滅。自然語言處理的研究也從單純的句法分析和語意理解轉換到了機器轉譯、語意辨識、文本生成、資料探勘和知識獲取。
而自2008年起,深度學習開始在語音和影像發揮威力。研究者先是把深度學習用於特征計算或者建立一個新的特征,然後在原有的統計學習框架下體驗效果。比如,搜尋引擎加入了深度學習的檢索詞和文件的相似度計算,以提升搜尋的相關度。
自2014年以來,人們嘗試直接透過深度學習建模,進行端對端的訓練,並已經在機器轉譯、問答、閱讀理解等領域取得了進展,於是出現了深度學習的熱潮。
這一切,為GPT的到來埋下了伏筆。
為什麽大模型能透過自然語言訓練表現出智能?
如開頭提到的,自然語言是人類思維的載體,也是知識凝練和傳承的載體。智能跟語言密不可分。人類的思想,科技、歷史、文明都是透過語言文字來記載和承載的。
也因此,自然語言跟機器語言、數學語言相比最大的不同是存在規則模糊性和歧義性(即語言可以有各種理解方式),特別是當各種模糊性和歧義性組合在一起,很容易就形成一個難以解決的爆炸性問題,這就意味著需要有一種類似於今天 的大模型這樣的「智能體」或者說,需要一種「具備智力」的工具和解決方法出現。大模型能學會理解和使用人類語言,也就意味著它有能力在各種復雜的事物中尋找模式和規則,然後用這些規則做推理。
我們可以從技術演進的角度來看,過去幾十年來,科學家一直在尋求解決知識的表示以及知識呼叫的方法(可以說每次知識表示和呼叫方式的轉變都會引起產業界巨大的變革)。
在大規模出現之前,知識最早是以數據庫的方式儲存在電腦內部,你想呼叫它就需要 SQL 語句等,需要人去適應機器,即使是這樣今天看起來比較「Low」的技術,當時也產生了很多偉大的公司,如 Oracle 等。
後來,大量的知識是儲存在互聯網裏,這種知識是非結構化儲存的,包括文本、影像,甚至影片等,要想呼叫這裏面的知識,我們就不需要學 SQL 語句,只要用關鍵詞,透過搜尋引擎的方式就可以把儲存在互聯網中的知識呼叫出來。現在 ChatGPT 仍然會存互聯網的知識,但是它不是以顯示的方式儲存,而是以參數的方式儲存在大模型中。
ChatGPT以及一系列超大規模預訓練語言模型的成功,為自然語言處理帶來新的範式變遷——即從以BERT為代表的預訓練+精調(Fine-tuning)範式,轉換為了以GPT-3為代表的預訓練+提示(Prompting)的範式。
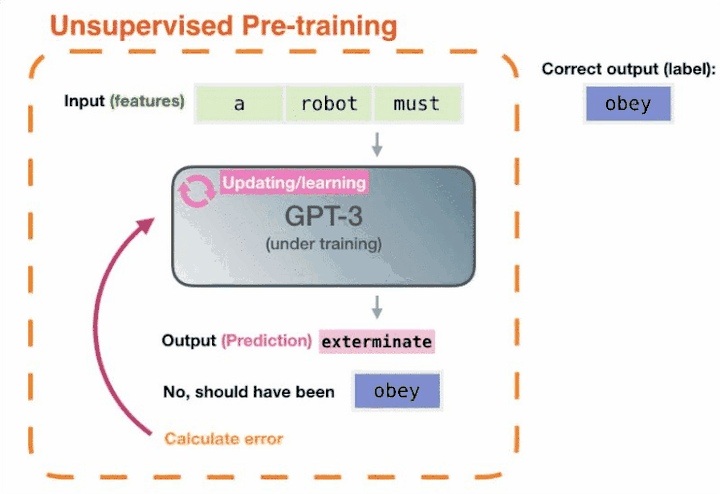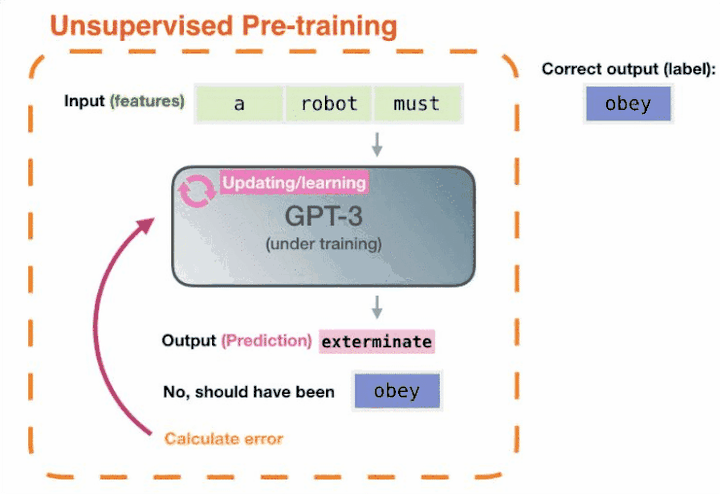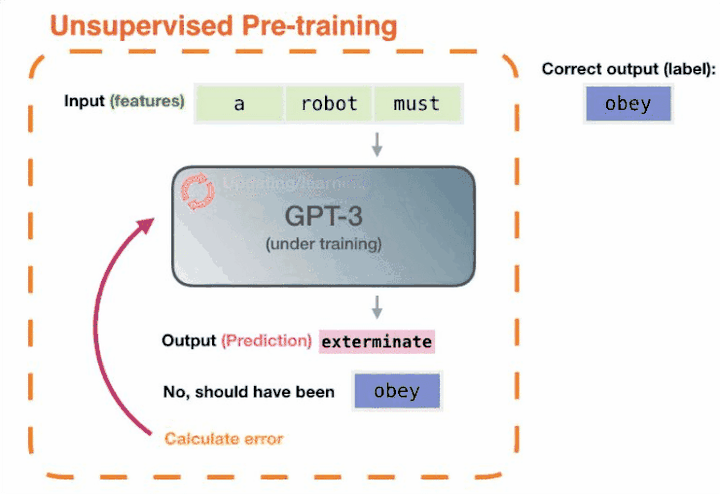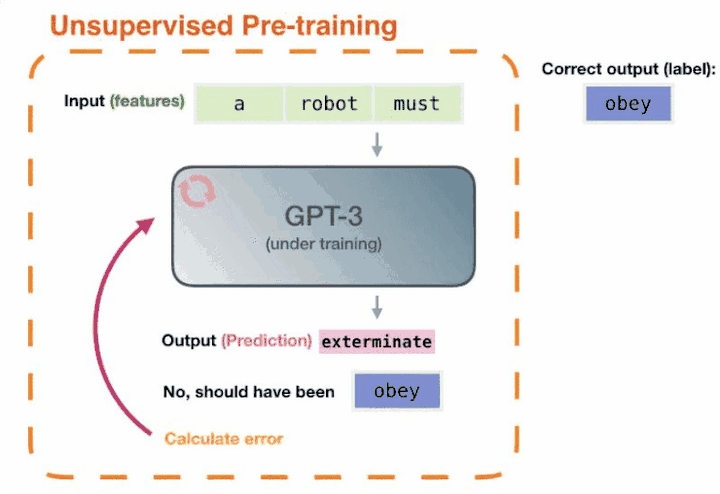
我們再回過頭來看,GPT-3 兩年前就能完成這樣的任務,但為什麽沒有引起這麽大的轟動呢?因為它沒有解決好另外一部份問題,即怎樣把這些知識呼叫出來。而ChatGPT就很好的解決了這個問題——透過自然語言的方式就可以很好的把這些知識呼叫出來。
ChatGPT 等於把這兩塊打通了,讓電腦有了智能湧現(頓悟)。這才引發了人工智能方向性的改變。說白了,也就是大模型在學習人類自然語言的同時,其實是把語言承載的知識也都學會了,TA能自己從數據裏總結規律。

這也正是GPT不同尋常的地方——傳統的電腦技術,由基於公式和統計,可以做非常精確的計算。而GPT做的,不是基於「已有命令「行事,其實這就具備了人類的本領:觀察世界,總結規律,獲取新知識。
不過,盡管今天的大模型能夠生成非常連貫而有邏輯性的語篇,對語言自身規律的掌握已經達到甚至超過普通人的水平。但是,對語言所負載的知識、經驗,尤其是道德、文化、價值觀等的把握,大模型還需要向人學習。
這背後,是因為現階段,人工智能的本質,仍然只是一種數學統計模型的具體套用。說白了,本質上還是一個小算盤。只是這個計算公式超級復雜,運算速度超快而已(所謂的「大力出奇跡「)。

所以很多人都在期待通用人工智能的來臨,期待未來AI能用這些知識解決復雜的問題,像人一樣進行推理、發明和創造。從這個意義上來說,從語言到知識再到智能,這就算是大模型到通用人工智能的總體路線了吧。











