這是個直指大模型本質的好問題,我覺得也是大模型研究裏最重要的問題,應該沒有之一。當然也有不少人認為大模型就是鸚鵡學舌,沒有智能,如果這樣就架空了這個問題,沒有的東西當然無需解釋其背後的原因。當然,我個人傾向認為大模型具備真正意義上的智能,後面內容都試圖在證明這一點。
關於智能、AGI與SAI
首先,什麽是智能?簡化地理解,可以把「智能」理解為完成復雜任務的能力集合 E 。我們可以把能比較好地完成某個具體問題A的能力叫做「A任務智能」,不論解決這個問題的主體是人(Carbon-E,碳基能力集)還是機器(Silicon-E,矽基能力集),這個不重要,重要的是問題解決得是否足夠好。比如我們可以有轉譯智能(是否能夠實作完美轉譯)、情感計算智能(是否能夠準確判斷情感傾向)等。我們一般所說的通用智能,指的是這些能力構成的合集 E 。
形式化地說,假設解決某個具體問題A的能力定義為函數y=f_{taskA}(x) ,意味著對於輸入 x ,透過 f 函數對映能夠給出完美的標準答案 y (意思是在測試集合上任務A準確率足夠高),比如轉譯函數 f_{translate}(x) ,可以把英文轉譯成中文,再比如摘要函數 f_{summarize}(x) ,可以給出好的主旨內容……。所以,我們說的通用智能,就是很多復雜任務函數的集合 E=\{f_{taskA}(x),f_{taskB}(x)….f_{taskX}(x)\} 。達成這種通用人工智能的具體主體,可以是人腦這種碳基濕件(f_{task}^{carbon}(x) ),也可以是電腦這種矽基幹件( f_{task}^{silicon}(x) )。所謂人類智能,無非是說實作能力集合 E 的主體是人,而AGI(通用人工智能)無非是說實作能力集合E的主體是GPU,如此而已。
假設每個任務我們都可以量化評估,那麽當下述條件成立時:
Condition: \{f_{taskA}^{silicon}(x)>= f_{taskA}^{carbon}(x) \& f_{taskB}^{silicon}(x)>= f_{taskB}^{carbon}(x)…..\& f_{taskX}^{silicon}(x)>= f_{taskX}^{carbon}(x)|f_{task}(x)\in E\}
也就是說,如果每項任務,機器都做得和做這個任務最好的人差不多或者比人做得好,那麽我們就得到了AGI。當然這是種比較嚴格的要求,能夠滿足上述條件的其實已經是超人工智能(Super Artificial Intelligence, SAI)了,因為人作為一個群體,領域專家和普通人做一個任務效果也是天差地別的,如果我們把這裏的人定義為領域專家,則是一種對AGI相對高的要求,而如果是普通人,則是相對低的一種AGI要求。
所謂圖靈測試,就是指的構造一個測試集合TestSet(x)=\{TaskA(x_1),TaskB(x_2)…...TaskX(x_n)\} ,簾幕背後一個Carbon-E,一個Silicon-E,用來判斷上述條件是否成立。不過話說回來,圖靈測試是對AGI的「部份降格測試」,就是說即使你是SGI,也得在能力集合E中的某些任務方面降低智商,表現得弱一點才能透過圖靈測試,因為如果你表現得過於強大反而讓人很容易判斷出「GPU你不是人」。所以圖靈測試其實是弱化了上述條件,把裏面的大於等於換成了「約等於」,而且圖靈測試裏的Carbon-E指的是人類的平均水準,GPU在某個任務上表現的太強或者太弱都會被輕易分辨出來。將來某一天,要想讓Silicon-E透過圖靈測試,很可能需要有意地調低某些方面的能力才行。
大語言模型學到了怎樣的智能
大語言模型透過自回歸語言模型任務(Autoregressive Language Model),以預測Next Token的方式,利用Transformer結構,從海量數據中自監督得學到了能力集合E中的很多能力,在很多工上的能力可以和人能力相當或超過人類,當然仍然有不少人類具備的能力它仍然做得很差,無法與人類相比,這是為何我們說大語言模型是通向AGI的一條可行道路,但是目前肯定還未達成AGI的原因。
從上面我們對AGI的形式化描述可看出,順著這條道路往下走,就是找出那些大語言模型還做得不夠好的任務E_{sub}=\{f_{task_i}(x),i=1...k\} ,然後逐一加強大模型在這些方面的能力。所以這個事情繼續往後走,會面臨三種可能的未來場景:
場景一:未來我們能夠獲得AGI,且是一種漸進達成的AGI,就是透過逐漸攻克 E_{sub} 裏的任務來達成的,我們可以把這種可能稱為「漸進智能派」。
場景二:某天AGI就突然爆發性地降臨人世,這個概率不太大,但是並非完全不可能。只有一種情況下才會讓這種場景發生,就是說Sub_E裏的任務之所以做不好,都根源於共性的一個或者兩個難題與原因,只要我們能夠解決這一兩個難題,那麽所有問題迎刃而解,AGI一夜降臨,我們可以把這種可能稱為「突然降臨派」。目前看「邏輯能力/數學能力」以及「影像理解」能力可能是其中的兩個關鍵癥結所在,所以不能排除哪一天我們有非常簡單有效提升大模型這幾種基本能力的方法,也許AGI會一夜到來。
場景三:存在另外一種可能,就是未來某天,我們發現大模型的現有機制,從根本上決定了很多人類具備的能力,它是不可能具備的,也就會否決掉大模型能夠帶來AGI的可能性,這樣可能大模型的路子只能通向有限能力,我們需要重新找到一條能夠達成AGI的新的道路。目前並不能排除這種可能性,因為我們對於大模型內在執行機制了解得太少,所以無法從機制角度作出能與否的判斷。我們可以把這個情形稱為「有限智能派」。
每人看法不同,我個人偏樂觀一些,覺得上述三個場景的出現概率大概會是:漸進智能派70%的可能性;突然降臨派20%的可能;有限智能派10%的可能性。這個問題真正的答案我相信未來兩到三年內就會揭曉。
如果我們歸納下現有對大模型機制解釋(Mechanistic Interpretation,MI)的研究結果,當然,目前機制解釋還沒有深入到能直接給出大模型是怎樣的方式學到了什麽樣的智能這種程度,不過大脈略看樣子已經初步展現出來。如果在現有研究基礎上做一些簡單推論,大致可以看出大語言模型形成了怎樣的智能。我今年5月份在之前的
裏也大致探討過這個問題,目前看有些具體細節可能需要做一些小修正,但是大邏輯目前感覺並沒有什麽問題,這裏算是結合最近半年新的研究結論做個總結。
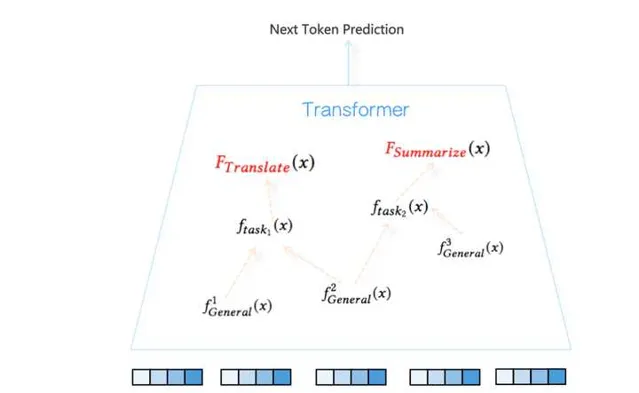
我們知道,大語言模型在很多工上效果是很好的,比如機器轉譯超過了專業機器轉譯系統、文本摘要能力也很強、程式碼能力也不錯….。我們拿機器轉譯來說,這說明大語言模型已經學到了一個很好的機器轉譯函數 y=f_{translate}(x) ,但是機器轉譯這個事情是非常復雜的,在Transformer內部大模型是怎麽處理的呢?從目前研究結論看,具體解決某個任務,應該透過預訓練過程,在Transformer內部形成了解決這個任務的特定任務回路(Circuits),當輸入x和任務prompt(比如instruct=」轉譯下面內容」)後,Transformer會由低向上地逐步啟用各層這個回路涉及到的路徑,並把資訊逐步上傳,最終到最上層token by token地輸出正確答案。任務回路由Transformer特定層的特定self attention節點及特定FFN單元構成,attention負責從上文找到重點資訊並拷貝到last token位置,負責關鍵資訊整合,FFN負責對資訊進行轉換。從這點看,和人類大腦的執行機制是非常相似的,人類大腦解決不同任務也會啟用特定的腦回路。(目前還沒有研究找出機器轉譯的回路,這個回路可能會比較復雜,不過已發現了很多相對簡單任務的專用回路,我相信每個特定任務應該都能找到對應的神經網絡回路)
大模型能做很多工,意味著Transformer透過預訓練形成了很多復雜回路,也就是說這些回路分別負責能力集合 E 中某個函數f的實作。於是問題來了,不同任務回路之間存在怎樣的關系呢?我歸納了類似GPT這種大語言模型智能的所謂「智能三性」,即大模型的智能體現出了組合性、可復用性以及抽象性。
所謂「組合性」,指的是對於復雜的任務函數f來說,大模型透過組合若幹簡單的子任務回路來達成處理復雜事情的能力,就是類似f_{task}=f_1(f_2(x),f_3(x)) 這種,大模型存在完成特定功能的子回路,復雜回路由若幹簡單子回路構成,這體現了大模型透過「組合性」來拆解復雜任務的能力。
所謂「可復用性」,指的是某些相對簡單的特定子回路,會出現在多個不同任務的任務回路中,形成了通用子回路被不同任務復用的情況,這個從道理上講是很合理的,很明顯子回路復用增加了模型參數的表達效率,使得模型參數能被更充分地利用。
所謂「抽象性」,指的是Transformer由低到高對輸入內容的加工,抽象能力越來越強。底層主要對token以及n-gram的token片段進行表征,屬於具體資訊編碼,在逐步上傳過程中,會逐步出現抽象的神經元或者attention head,比如輸入內容如果是英文或中文,上層會有專有的神經元進行表征響應,在神經網絡中間層也會出現辨識句子句法結構的神經元,再往上還會有更抽象的專用神經元。能夠具備逐層抽象性是大模型具備高級智能的明顯證據。
總體看,大語言模型形成智能的內部組織結構,看起來非常像我們寫的程式碼的內在邏輯結構。比如一個復雜的程式可以拆分成組成模組,每個模組完成相對簡單的功能,這體現了功能的組合性;有些基礎模組被很多其它模組呼叫,這體現了功能的可復用性;由簡單模組簡單功能逐步到復雜功能解決復雜問題,這體現出了一定的抽象性。只不過,程式結構是人類智能賦予的外在組織形式,而大模型的內在執行機制和組織形式是在Next token prediction過程中自己學到的。
關於大模型智能的「組合性」以及「抽象性」在上面列的文章裏有提到相關的研究,至於「可復用性」,當時在文中有提及,不過只是當時我個人的猜測,缺乏證據,下半年出現了相關研究,這裏列兩個證據。
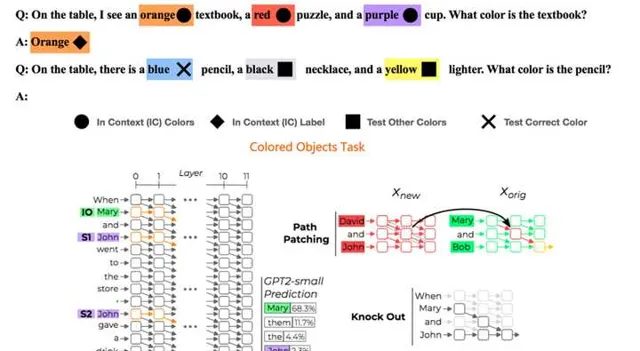
一個證據來自於「Circuit Component Reuse Across Tasks in Transformer Language Models」。它研究兩個看著有些相似性的任務「Colored Objects Task 」和「Indirect Object Identfication Task」是否存在重疊的任務回路。兩個任務具體幹什麽可以參考上圖的例子,那麽這兩個任務是否會有重疊回路呢?
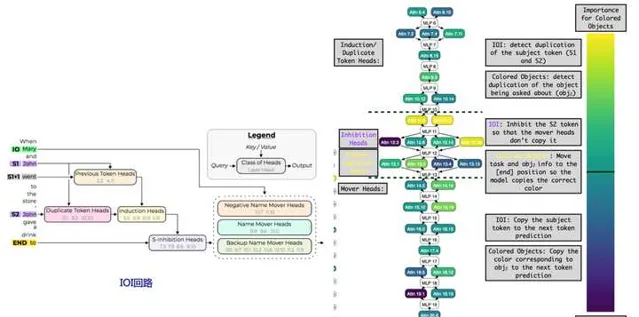
事實上,兩者的功能主要是靠Transformer不同層的特定「註意力頭」來實作的,且兩個任務存在大量任務回路重疊。參考上圖右側子圖,紫色代表IOI回路獨有的attention head,黃色代表CO回路特有的attention head,淺藍色的則是兩者共享的attention head,可以看出兩個任務存在大量回路重疊,回路重疊比例大約78%。上圖左側子圖展示了IOI回路的內部構成,可以看出IOI回路又是由「Duplicate Heads」(負責辨識上文中重復出現的內容)、「Induction Heads」(負責從上文拷貝特定的內容到next token輸出)以及「S-inhibition Heads」(負責抑制上文中特定內容,不讓它出現在next token輸出中)等子回路構成,這體現出上面提及的大模型智能的「組合性」及「可復用性」(Induction Heads是廣泛被使用的結構,比如ICL應該與這個註意力機制有密切關系)。
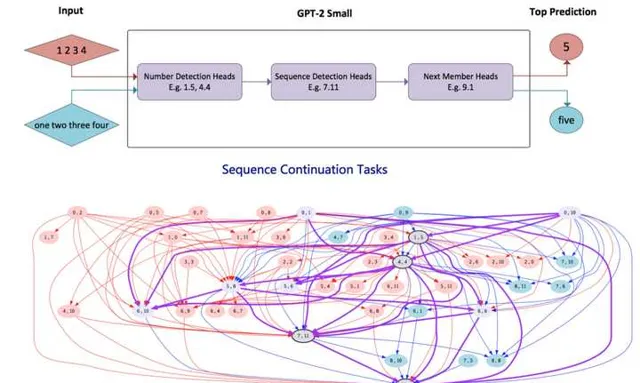
另外一個證據來自於「Locating Cross-Task Sequence Continuation Circuits in Transformers」。如上圖所示,它探索對於比如數碼形式的序列類似「1,2,3,4」以及單詞形式的數碼序列「one,two,three,four」這兩種表面看似不同但內在有相似性的任務,回路是否有重疊。結論是兩者存在大量回路重疊,這個內部回路涉及到了「數碼檢測」、「序列檢測」以及「下一數碼預測」子回路,這些子回路在這兩個任務之間存在大量註意力頭的共享。
上面兩個證據說明了兩個任務越是相似,則有越大比例的內部任務回路是共享的,這充分證明了大模型智能存在任務回路的「可復用性」。
為什麽大語言模型可以形成智能
既然大語言模型可以很好完成很多工,說明起碼它具備了能力集合E中的很多能力。那麽接下來的問題是:為何大語言模型可以透過預訓練獲得解決這些任務的能力呢?
目前並沒有研究結論,因為這個課題看上去太寬泛了。不過,我相信這個問題的答案很可能極為簡單,所有關於大模型秘密的答案應該都藏在預訓練數據裏。
這個答案很可能是(猜測,謹慎參考):大模型預訓練透過自回歸方式進行的Next Token Prediction,它是個非常好的代理任務(Proxy Task)。所謂代理任務,是說盡管我要做機器轉譯任務,但是我不直接拿機器轉譯數據和目標函數來訓練模型,而是透過其它任務比如Next Token預測來實作。那為啥Next Token預測對很多工的代理效果這麽好呢?這是因為,大模型看似以自監督方式在做Next Token預測,但是因為預訓練數據的多樣性,對於很多工來說,預訓練數據中存在和這些任務有監督學習非常類似的數據,而正是這些數據,使得大模型可以透過看似自監督的方式在進行有監督訓練,由此得到了解決很多工的能力。目前雖無定論,但我相信正確答案離此不遠。

我們拿具體任務來說,比如為何大語言模型轉譯能力這麽強?你看看上面這張圖應該就明白為什麽了。互聯網上存在大量類似上面的雙語網頁,一句中文對應一句英文,當大模型在做Next Token Prediction的時候,當Next Token是中文對應的英文的時候,其實就是在做機器轉譯的有監督學習,只不過是以Next token 這種看似自監督的模式而已。
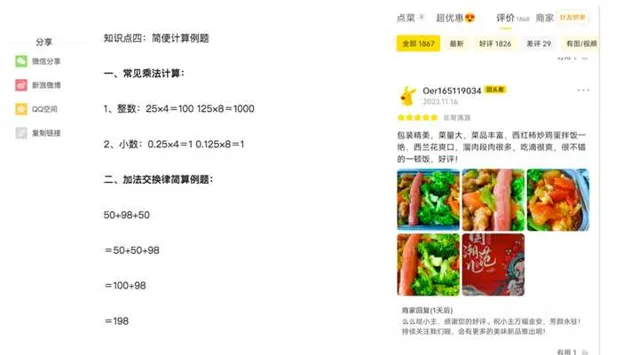
再比如,大模型的數學能力從何而來?情感計算能力從何而來?看看上面我給的兩個例子大概就明白了,當Next Token預測到「等於號」的時候,以及當Next Token預測到「好評」的時候,如果預訓練數據中大量存在此類數據,就是在對數學和情感判斷做有監督訓練,只不過是以Next Token的自監督形式存在而已,本質上還是在做有監督學習。很多其它能力的獲得大概率跟這些情況是很類似的。
所以原則上,如果我們覺得大模型哪些能力還不夠好,那很簡單,把這個任務相關或類似的數據加進去,應該就會直接提升這種任務的效果。而這得益於Next Token Prediction這種好的代理任務,以及互聯網開放數據的多樣性,包含了類似有監督學習形式的任務數據。
總而言之,數據是大模型智能的最關鍵因素,數據多樣性決定了大模型智能的下限(提升效果較差任務的效果),而數據質素決定了大模型智能的上限(提升效果較好任務的效果)。











