這個問題之前OpenAI 的核心研發人員 Jack Rae在一次分享中解答過。下面我們就分享下如何透過壓縮理論,解釋為什麽像GPT這樣的自然語言模型擁有智能。
1. 壓縮即智能——為什麽ChatGPT擁有智能
目前規模較大的語言模型,在訓練基礎模型時,都采用了預測下一個詞的任務。這個任務非常簡單,就是根據語言中前面的詞,來生成下一個詞。這樣學習到的似乎只是詞之間的表面統計關系,怎麽就能體現出智能呢?這確實很難理解。
2月28日,OpenAI 的核心研發人員 Jack Rae 在 Stanford MLSys Seminar 上分享了一個主題:壓縮與人工通用智能。他的核心觀點是:人工通用智能的基礎模型應該能夠最大程度地無損壓縮有效資訊。他還分析了這個目標的合理性,以及 OpenAI 是如何按照這個目標進行工作的。
Jack Rae 是 OpenAI 的團隊負責人,主要研究大型語言模型和遠端記憶。他曾在 DeepMind 工作了 8年,領導了大型語言模型研究組。在分享中,Jack Rae 提出了以下兩個核心觀點。
Jack Rae 在 Stanford ML Seminar 上的分享非常精彩,讓人感覺豁然開朗。他用壓縮理論來解釋為什麽 GPT 具有智能,是一個很有創意的觀點。下面我們就具體介紹一下 Jack Rae 是如何論證的。
1.1 直觀理解AGI
在探討壓縮如何能夠實作人工通用智能之前,先來了解一下什麽是人工通用智能。「中文房間」是約翰·塞爾(John Searle)在1980年提出的一個著名的思想實驗,用來質疑電腦是否能夠真正理解語言。實驗的設想可以透過下面的文字描述。
一個只會說英語,對中文一無所知的人被關在一個密閉的房間裏。房間裏只有一個小視窗,還有一本中英文對照的手冊,以及足夠的紙和筆。有人從視窗遞進來一些寫著中文的紙條。房間裏的人根據手冊上的規則,把這些紙條轉譯成中文,並用中文寫回去。盡管他完全不懂中文,但是透過這個過程,他可以讓房間外的人認為他會說流利的中文。這就是「中文房間」的實驗,圖1-1展示了它的示意圖。

一個龐大而煩瑣的手冊說明了這個人的智能水平很低,因為他只能按照手冊上的指示去做,一旦遇到手冊中沒有的情況,他就束手無策了。
如果我們能夠從海量的數據中學習到一些語法和規則,那麽就可以用一個簡潔而高效的手冊來指導這個人,這樣他就能夠更靈活地應對各種情況,表現出更高的智能水平(泛化能力更強)。
手冊的厚度反映了智能的強度。手冊越厚,說明智能越弱;手冊越薄,說明智能越強。就像在公司裏,你雇用一個人,他能力越強,你需要給他的指示就越少;他能力越弱,你需要給他的指示就越多。
這個例子用一個比較形象的方式解釋了為什麽壓縮就是智能。
1.2 如何實作無損壓縮
假設 Alice 需要把一個(可能無限長)的數據集D = \{x_1, x_2, ..., x_n, ...\} 從遙遠的半人馬座星系傳輸回地球上的 Bob,假設如下。
先看一下基準傳輸方法。由於 x_{t+1} 的可能性有m = 256種,所以 z_{t+1} 可以表示為一個8位元的整數(即1字節)。假如當 x_{t+1}=7 時, z_{t+1}=00000111 表示 x_{t+1} 。這時需要傳輸的位元數 |z_{t+1}| = \log m = \log 256 = 8 。另外,Alice還要將上面的程式碼寫成程式碼 f_0 ,在一開始傳輸給Bob。圖1-2是編碼數據傳輸的示意圖。
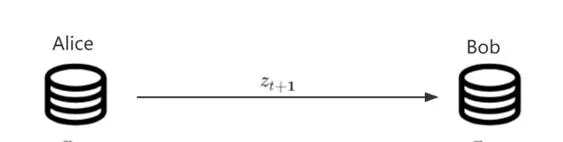
這樣傳輸一個大小為n的數據集的D_n = \{x_1, x_2, ..., x_n\} 的代價S_0 可以表示為如下形式。
\begin{align} S_0 & = \#bits \\ & = |f_0| + \sum_{t=1}^n |z_{t}| \\ & = |f_0| + n \log m \end{align} \\ \tag1 接下來從消息理論角度解釋一下基準的資訊量。
基準方法對於 x_{t+1} 的分布沒有先驗知識,因此其概率分布故P(x_{t+1}) = \dfrac{1}{m} 是一個離散均勻分布。此時資訊量表示為如下形式。
I= -\log P(x_{t+1}) = -\log \dfrac{1}{m} = \log m = |z_{t+1}| \\\tag2
因此, |z_{t+1}| 也可以看作是 P(x_{t+1}) 的資訊量。
在介紹了基準方法之後,接下來介紹一下基於神經網絡的無損壓縮方法。想要利用一個自回歸神經網絡來實作壓縮。具體來說,假設如下的一個場景。
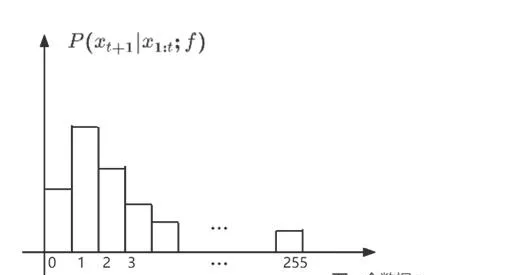
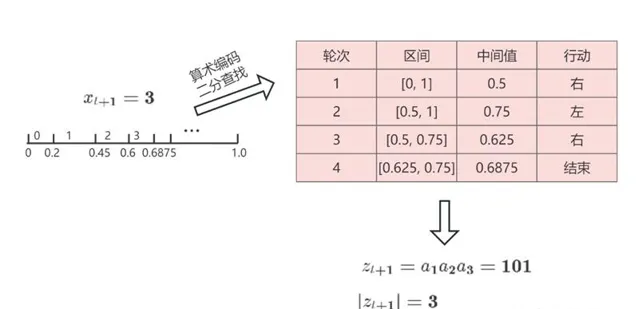
這樣一來,Alice 就實作了把x_{t+1}=3 按照 Alice 和 Bob 共同掌握的概率分布編碼成 z_{t+1}=\left( 1,0,1 \right)_2 ,並且把它無失真地傳輸給 Bob。Bob 也可以按照同樣的概率分布把z_{t+1}=\left( 1,0,1 \right)_2 解碼回 x_{t+1}=3 。這個過程比基準方法節省了很多傳輸的數據量。原本需要傳8位元,現在只需要傳3位元。圖1-4是整個過程的示意圖。
2. GPT是對數據的無損壓縮
前面介紹了算術編碼的原理,它可以實作無損壓縮,從而減少數據傳輸的量。我們的目標是最小化傳輸的量,也就是最小化二分尋找的次數。
為了計算二分尋找的次數的上界,可以用一個直觀的方法。還是用上面的例子,x_{t+1} = 3 。將x_{t+1} 的區間均勻鋪滿整個[0,1] 區間,假設p = P(x_{t+1}=3 | x_{1:t}, f) ,那麽會分成m= {\large\lceil} \dfrac{1}{p}\large\rceil 個區間,那麽大約要查詢\log m 次。如果不考慮取整的誤差,可以得到二分尋找的次數,表示為如下的形式。
|z_{t+1}| \sim \log m \sim -\log p\tag3 實際上,二分尋找的次數的上界可以表示為如下的形式。
|z_{t+1}|\le \lceil \log \dfrac{1}{p}\rceil \lt -\log p + 1 \\\tag4
這樣就可以知道傳輸數據集 D_n 的代價 S_1 ,表示為如下的形式。 \begin{align} S_1 & = |f_1| + \sum_{t=1}^n |z_{t+1}| \\ & \lt |f_1| + \sum_{t=1}^n [-\log P(x_{t+1} | x_{1:t}, f) + 1] \\ & = |f_1| + n + \sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1) \end{align} \\\tag5
如果仔細觀察,會發現-\log P(x_{t+1} ) 其實就是訓練時x_{t+1} 這個 token 的 loss。所以可以進一步發現\sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1) 這一項就是訓練曲線下方的面積,具體範例如圖2-1所示。
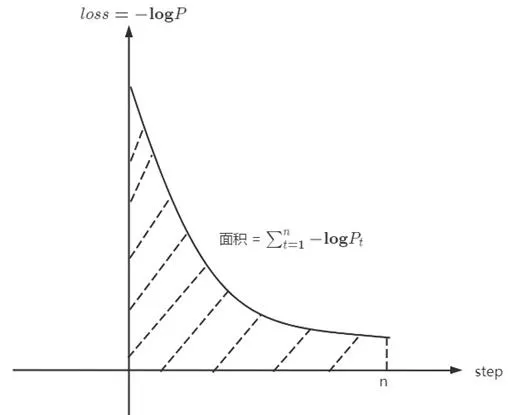
因此,GPT的訓練過程本質上就是對整個數據集 D 的無損壓縮。圖2-2詳細展示了GPT無損壓縮的每一項內容。
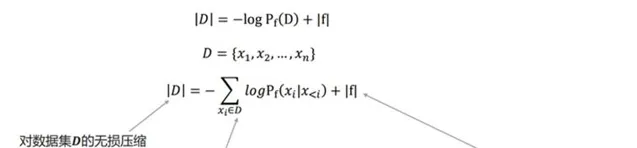
按照上述方式計算並儲存z_{t} ,那麽 "訓練程式碼 + 所有的z_t " 便是對數據集D 的無損壓縮。只是在平時訓練中計算得到下一個token的分布,並且計算loss進行反傳後,便扔掉了這個分布,自然也沒有計算並儲存z_t 。但是「無損壓縮」和「模型訓練」的過程是等價的。
有了壓縮的量化公式,便可以很方便地計算壓縮率,下面是壓縮率的計算公式。 \begin{align} r_n = 1 - \dfrac{S_1}{S_0} \gt 1 - \dfrac{|f_1| + n + \sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1)}{|f_0| + n \log m} \end{align} \\\tag6
這也解釋了為什麽模型越大,往往表現越智能,更容易出現湧現。這是因為模型越大,往往loss越低,從而壓縮率越高,模型越智能。(這裏是根據資料壓縮理論,就是壓縮率越高,模型越智能)。
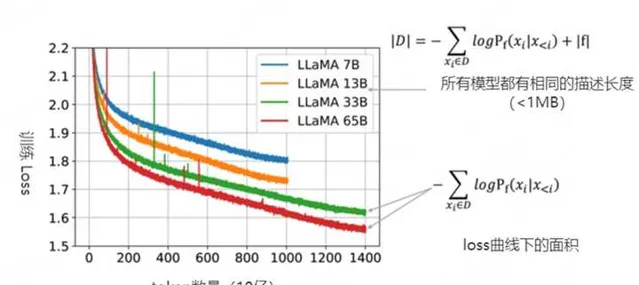
上圖2-3是 LLaMA 模型的一些訓練曲線,綠線和紅線表示的兩個模型只在數據集上訓練了1個epoch,因此可以把訓練損失視為| D |中下一個詞(next-token)預測損失。同時也可以粗略地估計模型的描述長度(~1MB)。即便模型的參數量不同,但LLaMA 33B和LLaMA 65B兩個模型有著相同的數據描述長度(用於訓練的程式碼相同)。但65B模型顯然有著更低的訓練損失,把兩項相加,可以看出65B實際上是更好的壓縮器。
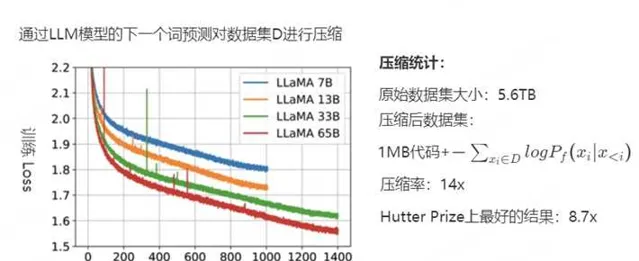
下圖2-4是更具體的數據,用於初始化和訓練模型的程式碼約為 1MB,粗略地計算負對數似然大約是 400GB,而用於訓練的原始數據是5.6TB的文本,因此該模型的壓縮率為14倍。而Hutter Prize上最好的文本壓縮器能實作8.7倍的壓縮。接下來,討論一下壓縮率的變化。
假設訓練穩定,loss 平滑下降收斂到 \lim_{t\rightarrow\infty} -\log P(x_{t+1} | x_{1:t}, f_1) = - \log p^* ,那麽當數據集D 無限增長時,壓縮的極限可以表示為如下形式。
\begin{align} r & = \lim_{n \rightarrow \infty} r_n \\ & = \lim_{n \rightarrow \infty} 1 - \dfrac{|f_1| + n + \sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1)}{|f_0| + n \log m} \\ & = \lim_{n \rightarrow \infty} 1 - \dfrac{|f_1| + n + n(- \log p^*)}{|f_0| + n \log m} \\ & = 1 - \dfrac{1-\log p^*}{\log m} \\ & = 1 - \log_m 2 + \log_m p^* \\ \end{align} \\\tag7
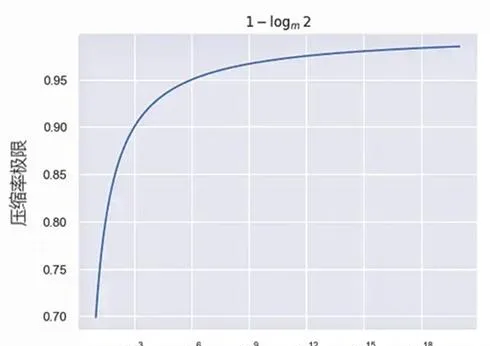
當 p^* \to 1 (預測得完全準確),壓縮率的曲線如圖2-5所示。由此可見,預測下一個詞(next token prection)看似簡單,但是卻可以用壓縮理論完美地解釋,這也是為什麽OpenAI堅持「預測下一個詞」的原因。
雖然像GPT這樣的大模型可以實作壓縮機制,但是這種壓縮方式也有局限性。比如對於所有的一切都進行壓縮非常不現實,像素級的影像建模開銷非常大,對影片進行像素級別的建模非常不現實。還有就是非常多在現實中的數據可能是無法直接觀測到的,不能指望透過壓縮所有可觀測到的數據實作通用人工智能。以圍棋遊戲AlphaZero為例,觀察有限數量的人類遊戲不足以實作真實的突破。相反,需要其智能體(Agent)自行進行對弈並收集數據中間的數據。
參考











