剛好寫了一片文章,挪過來一下。
要回答這個問題,我們首先要知道數碼音量控制和模擬音量控制是如何工作的。
先說模擬音量控制。放大器的模擬音量控制按照發展歷程大抵分為兩種形式。
機械式電位器
從ALPS的RK系列碳膜電位器到高端的分立電阻的段位式電位器(如索六萬的電位器),都是這一思路。傳統的滑動變阻器雖然能保證平滑的音量調整,但一來小音量聲道差異太大,二來容易產生滑動雜訊,因此少在高端產品中見到。而段位式電位器雖然避免了滑動產生的摩擦雜訊並解決了小音量偏音的問題,但由於有限的體積和龐大的分立電阻,導致旋轉開關無法做出足夠多的檔位,保證全幅值的精細調整。通常見到的30段左右的這種電位器,在60dB的調節範圍內甚至達到了一檔2-4dB,響度跳變太大導致它更加適用於長時間處於高音量位置的小功率放大器。這兩種電位器基本都是加在放大器輸出級的分壓式電位器,因此也無法保證放大器的輸出阻抗恒定,通常在低成本放大器中見到。
數控式電位器
這裏說的數控式其實是我自己為了方便取的名字,指的並不是數碼電位器。從MCU控制繼電器/復用器切換分立電阻到用R2R DAC芯片內的整合電阻陣列等等玩出花的方式,都屬於數控式電位器,其本質還是模擬電位器,因為這種音量控制方式會對訊號通路上的 所有訊號 包括雜訊訊號一起衰減。繼電器切換電阻網絡的方式本來是用於射頻領域的,因為到了高頻世界,由於接觸阻抗的不確定性和各種玄學的分布參數,需要避免一切可能不穩定的宏觀機械接觸,而改用高精度的整合電子開關控制,整合的電子開關的ns級響應速度更是把繼電器的ms級響應速度甩了幾個數量級。使用特征阻抗恒定的Π或T型電阻網絡,可以使得放大器在全幅值都能有一致的頻響特性,再加上MCU的訊號可以控制多路,使得電阻衰減網絡的音量控制方案在檔位和精度上都達到了前所未有的高度。實際上許多的「數碼音量芯片」如PGA2311和MUSES72320也正是這種數控模擬音量的方式,只不過它們將電阻網絡也靠先進的半導體工藝整合進了芯片裏,靠著高精度的激光切割做到了很低的誤差和失真。這樣靠繼電器或者電子開關對衰減電阻進行切換的方式,使其調整精度高,靜態效能非常優秀
然而還有抗幹擾能力更加卓越的方式,也是目前模擬音量控制中最理想的方案——R2R式音量控制。這種方式利用了R2R芯片每部的加權電阻網絡,輸入的音訊電壓先以2進制加權遞減的方式進行V-I轉換,然後透過外部控制數據來切換R2R網絡的合成輸出電流,最後再透過I-V轉換形成最後輸出訊號。因為電流訊號在R2R網絡中不會受外部幹擾,因此這種類似D/A轉換的音量控制方式可以做到極低的底噪和極高的訊噪比(就如R2R型DAC),並且檔位非常多,對應於2進制的控制位數。這種音量控制由於布線較為復雜,沒有成品IC可用,需要獨立進行嵌入式開發,所以只有一些有實力的廠家在高成本的產品上套用。
數碼音量控制
而數碼音量控制,我們這裏以PCM這種錄音行業通用的調制方式來舉例(實際上DSD的音量調整也是透過SDM 多bit量化的方式進行的,與此大同小異)。PCM有取樣率和位深,每個采樣點的位深記錄了該點的幅值大小,也就是音量大小。
例如對於16bit的DAC,滿幅值即0dBFS對應的采樣點應該是
1111 1111 1111 1111 = 65535
而靜音無聲對應的采樣點應該是
0000 0000 0000 0000 = 0
而數碼音量調節就是靠CPU/DSP去進行計算設定衰減所對應的新采樣數據。
我們來看一個例子:
16bit的DAC中如何表示30003這個數值的采樣呢?
0111 0101 0011 0011 = 30003
如果我們要將這個音量調低10dB,也就是乘上20*lg(-10)=0.3162,那麽在16bit二進制整數表示中也就是:
0010 0101 0001 0000 = 9488
但是我們發現,精確的計算結果應該是
30003*0.3162=9487.7817
和整數數值很接近了,只有23ppm也就是0.023‰的誤差,但仍然不夠精確。
那麽如果我們想要降低更多的音量呢?比如現在我們要調低35dB:
0000 0010 0001 0110 = 534
由於是二進制整數計算,所以最後只能取整。而精確結果是:
30003*0.0177828 = 533.5372
這這時我們發現,雖然絕對誤差值仍然在±0.5內,但相對誤差值已經飆升到886ppm也就是0.886‰.
訊號幅值一直在變化,所以即使數碼音量衰減在某個采樣點碰巧能夠對齊到整數,在其他絕大部份采樣點肯定是無法對齊的,會遺失小數部份的精度,這就是量化誤差,會引起DAC表現中的本底雜訊,這種本底雜訊稱為量化雜訊。
如果我們提高數碼音量的量化精度呢?
這裏我們引入兩個概念:
ENOB指有效位數(Effective Number of Bits),能反應一個系統的動態範圍。
SNR指訊噪比(Signal-to-Noise Ratio),顧名思義不多贅述。
對一個16bit的DAC,當音量衰減為-1dBFS的時候,SNR=97.63dB,ENOB=15.87:
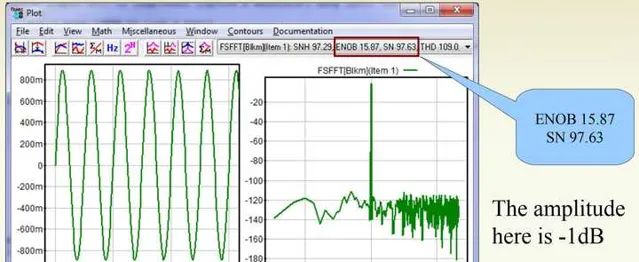
當將數碼音量衰減到-10dBFS的時候,此時SNR=88.51,ENOB=14.35:
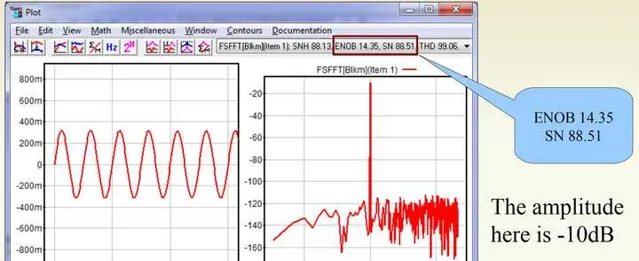
當將數碼音量衰減到-35dBFS的時候,此時SN=63.18,ENOB=10.17:
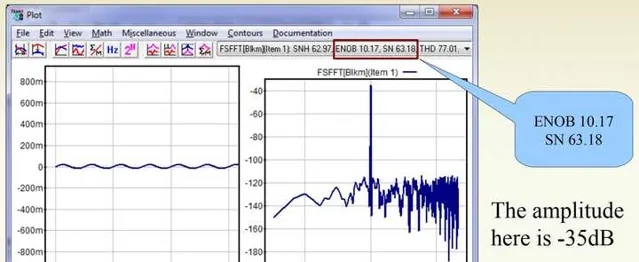
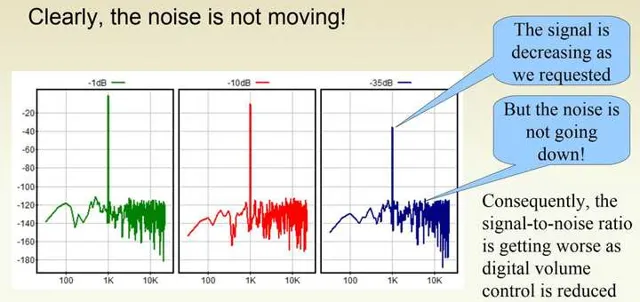
放在一起對比,我們發現,當數碼音量在逐步衰減的時候,量化雜訊並沒有在下移。這就是為何大家通常會去避免數碼音量控制。
現在我們來看看模擬音量控制。在-1dBFS的時候SNR=98.53dB,ENOB=16.01:
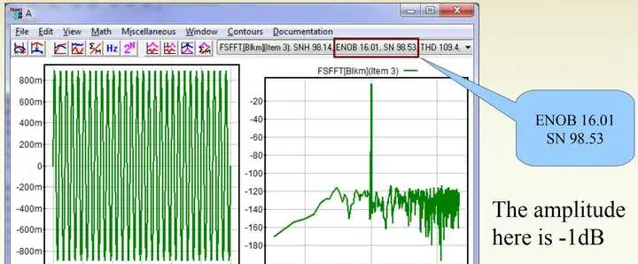
在-10dBFS的時候SNR=97.95dB,ENOB=15.94:
在-35dBFS的時候SNR=91.8dB,ENOB=14.94:
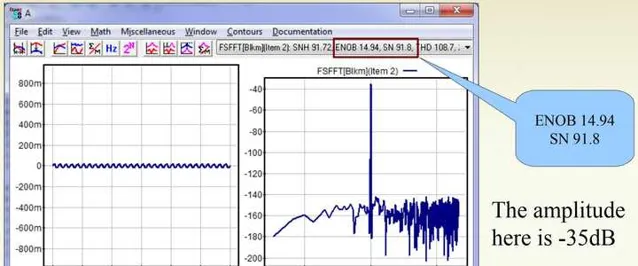
於是我們發現,在模擬音量控制進行音量衰減的時候,訊號電平在衰減的同時,雜訊電平也在幾乎等比例地衰減。這使得整體SNR在調整音量的時候能夠保持較高的水平。這也是為什麽燒友們更偏向於使用模擬電位器的原因。

這樣對比下來,還是模擬電位器有著比數碼音量控制更優異的表現。那麽我們可以最佳化改進數碼音量嗎?畢竟上面的例子中,DAC和訊號都是16bit的,如果我們將16bit的訊號餵進32bit DAC中會怎麽樣呢?
我們還是沿用上面的例子,那麽在32bit的DAC中:
0111010100110011.0000000000000000 = 30003
我們同樣進行-35dB的數碼音量衰減,也就是乘上0.0177828,結果是:
0000001000010110.1000100110000100 = 533.5372
而在十進制的表示中,精確的結果也確實是:
30,003 * 0.3162 = 533.5372
看看某32bit DAC的官方測試指標:
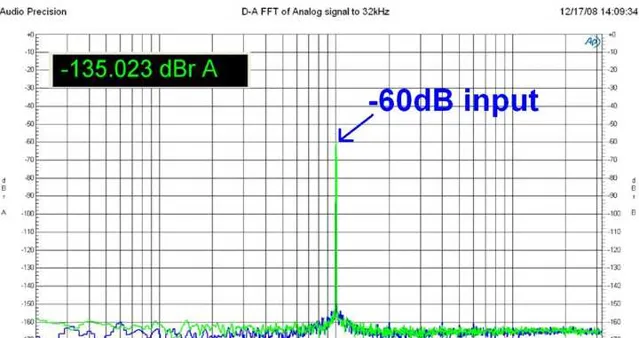
此時量化雜訊水平已經接近於其本身的模擬底噪了。
我們發現,當數碼音量控制有著足夠的 計算位深 時,是幾乎不會損失量化精度的。即使衰減加大,量化雜訊也會隨著訊號電平一起衰減,直至達到整機的本底雜訊電平。
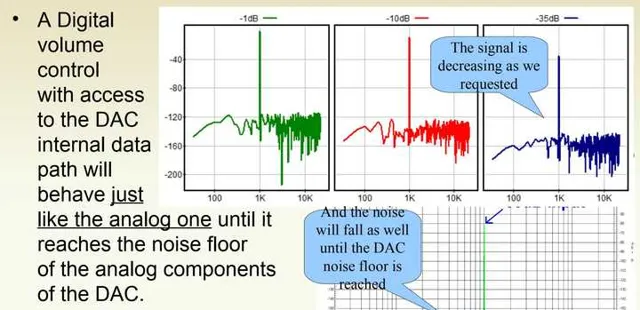
從這一段ESS給出的數據和講義我們知道,在通常情況下,模擬音量控制還是有著更好的表現的,除非數碼音量控制有著足夠的有效位數,並且可以對進入DAC的數據直接進行計算(而不是位深不變的軟件計算)。如果說有著底噪非常優異的模擬音量控制,那數碼音量還是比不上模擬音量控制的。
以上是理論數據,我們再來看看一組硬件配置相近的同廠產品實測,其中一個是數控模擬電阻網絡音量控制的旗艦,另一個是使用DAC內部32bit數碼音量控制的次旗艦:
低增益最大輸出的二者表現:


憑借更高的輸出和更小的諧波,采用數碼音量輸出的「次旗艦」似乎有著比「旗艦」更低的總諧波失真+雜訊,並且有著水平相當的互調失真。乍一看似乎「次旗艦」比「旗艦」更優秀,但如果我們把他們的輸出電平均一化到50mV:
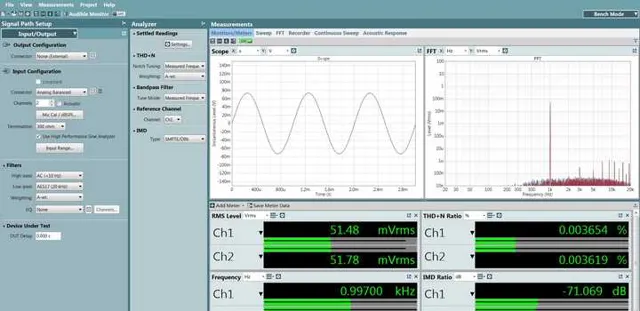
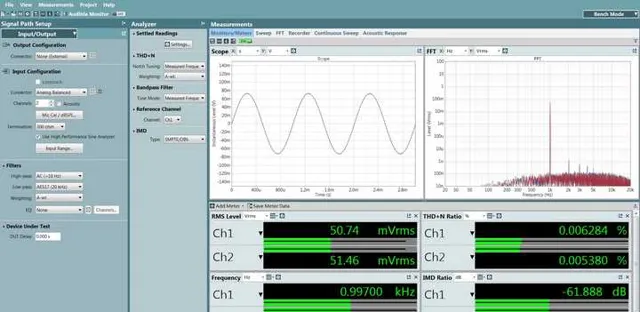
我們看到了和ESS講義描述中基本符合的現象:采用模擬音量的「旗艦」,隨著音量衰減,底噪有略微降低,而采用數碼音量的「次旗艦」,隨著音量衰減,底噪基本沒有發生變化,因此在衰減到和日常聽音音量相當的幅值水平時,諧波失真+雜訊比「旗艦」落後了4dB左右,互調失真(非諧波成份)此時比「旗艦」落後了10dB。
甚至可以這麽說,是模擬音量控制靠著小訊號下的優勢完成了整機指標的反超。
ESS關於數碼音量和模擬音量的講義:http://www. esstech.com/files/3014/ 4095/4308/digital-vs-analog-volume-control.pdf











