一句话简单回答——就是 至少目前人类还没有找到一条通往AGI的可行路径,大语言模型这条路径所体现出来的人工智能,看起来可行性最高。
自从大模型爆火之后,我周围很多研究机器翻译十多年甚至几十年的朋友都在感慨,NLP经历了规则、统计和神经网络的三个阶段,筚路蓝缕,终于迎来了最黄金的时期。但,GPT的出现,并不等于机器就具备了「智能「」智慧「。因为要做出可解释、有知识、有道德、可自我学习,能准确进行推理的NLP系统,实际上是一个很高的目标,现在我们还离得很远。
所以,首先我们来讨论一下到底什么是自然语言。
人类的自然语言
这是个很难定义清楚的概念。
本质上,语言的出现是为了人类之间的沟通(我们当然希望计算机能全部拥有人类的视觉、听觉、语言和行动的能力,但语言是人类区别于动物的最重要的特征)。所以从这个意义上来说,研究自然语言,其实就是在研究如何让机器拥有更多的「认知智能」。
机器理解人类的语言很难吗?很难。
别看我们天天说话,聊八卦看新闻,看似轻松得很,但对计算机来说,人类的自然语言是非常难掌握的。这是因为人类语言最大的问题,就是知识表示的规则模糊性和歧义性。毕竟人类语言不是工程师设计出来的,而是人类发展过程中,「众约俗成」变成固定词汇和语法——没什么道理可言——说的人多了,大家就都认可了。
这种集体参与的结果,就是语词的含义和它们的使用规则,都非常不统一。一词多义,一义多词,在实际生活的使用场景中非常常见。
先看下面号称「中文十级」的两句话:
* 校长说:「校服上除了校徽别别别的,让你们别别别的,别别别的,非要别别的。」* 来到杨过曾经生活过的地方,小龙女动情地说:「我也想过过过儿过过的生活」
再来看下面这句含有「歧义性」的中文语言表述:
第一场,中国女排队大胜美国队;第二场,中国女排队大败日本队。请问:中国女排队赢了几场?上文中女排的「大胜」和「大败」,指代的都是「赢得比赛」这一个意思。这个指代虽然有点微妙,但根据上下文,我们还是能比较容易地做出判断。而想要计算机要做到这一点,那可就难得多了。
此外,人类的自然语言, 除了歧义性之外,自然语言处理面临的难点还包括抽象性、组合性、进化性等。
所以从人类语言本质属性的角度来讲, 自然语言处理属于认知智能,理解它、掌握它,就需要机器具备很强的抽象和推理能力,也因此,说「自然语言是智能的载体」,是完全说得过去的。
计算机算法的局限:理解自然语言
现阶段计算机上的所有行为,说到底,都可以转换为
数学和逻辑运算
。如果把计算机的行为抽象出来看,就是输入、计算、输出。
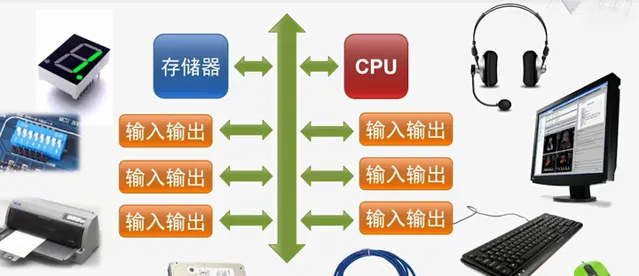
为了让计算机模仿人类思维、理解人类自然语言,人们先是发明了编程。比如,在冯诺伊曼计算机上,工程师编写各种处理规则。类似于:「小球如果碰到墙壁,就弹回来」,这些场景需要人类写出不同的程序来表达。
虽然这种解决问题的方式有点「笨笨的」,但只要程序能运行起来,还是能提升了很多工作效率。

不过比较无奈的是,现实中的问题总是千变万化。你写的某个程序能让「小球如果碰到墙壁就弹回来」,但当拿到真实的应用场景中的时候,你往往会发现,计算机让小球碰壁弹回来后,小球可能还会向另一处悬崖滚下去,然后粉身碎骨。

于是,工程师不得不使劲编写更多的程序,来弥补各种漏洞(Bug),以便让计算机学会应付各种可能的变数。
但变数无穷尽,而人力、时间有穷尽,在不断动态发展的世界中,漏洞是永远补不完的。
退而求其次,人们转而教计算机某个单一技能。比如下棋。但如果计算机只会下棋这一件事,在实际生产生活中也没太大的作用。
于是有人想:咱们是不是应该改个路子,让计算机模仿人类的大脑不就行了吗?
这个研究开始很让人惊喜,因为人们发现,人脑的基本工作单元是神经元,也就是神经细胞。而神经细胞用的是二进制!
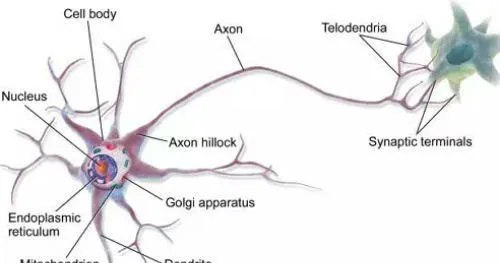
科学家很兴奋,打算用电子元件模仿神经元,做出「人造大脑」。理论上说,我们造出一个神经网络,就像一个初生婴儿的大脑,那么我们可以人类所有的已有知识都输入给它,让它像婴儿一样去探索世界。如果能实现这个目标,那么人工智能就不再只局限于某个单一技能了。
但很快科学家发现,人类的大脑实在太神奇了。「看,那是只狗狗!」,小朋友一句看似非常简单的判断,实际上需要大脑做千万次运算。人类大脑只有一公斤多一点,小这么个小小的东西,运算速度却是计算机不可企及的。
就像之前人类想要飞上蓝天,期望通过模仿鸟的飞翔来制造飞机,却一直没能成功,直到乔治·凯利提出空气动力学才迎来了转机。研究自然语言处理的早期科学家,也走过类似「鸟飞派」的弯路:他们试图让计算机通过模仿人的大脑来理解自然语言的含义,结果导致从上世纪50年代到70年代的研究成果寥寥。
但1970年以后「统计语言学」的出现,终于让自然语言处理发生了转机:弗里德里克·贾里尼克和他领导的IBM华生实验室,把自然语言分析变成了一个简单的数学问题——一个统计模型,即统计语言模型。他的出发点很简单:一个句子是否合理,不需要再分析语法和语义了,只看它的可能性大小就可以了。
2005年后,随着Google基于统计方法的翻译系统全面超过基于规则方法的SysTran翻译系统,彻底将基于规则的自然语言处理方法消灭。自然语言处理的研究也从单纯的句法分析和语义理解转换到了机器翻译、语义识别、文本生成、数据挖掘和知识获取。
而自2008年起,深度学习开始在语音和图像发挥威力。研究者先是把深度学习用于特征计算或者建立一个新的特征,然后在原有的统计学习框架下体验效果。比如,搜索引擎加入了深度学习的检索词和文档的相似度计算,以提升搜索的相关度。
自2014年以来,人们尝试直接通过深度学习建模,进行端对端的训练,并已经在机器翻译、问答、阅读理解等领域取得了进展,于是出现了深度学习的热潮。
这一切,为GPT的到来埋下了伏笔。
为什么大模型能通过自然语言训练表现出智能?
如开头提到的,自然语言是人类思维的载体,也是知识凝练和传承的载体。智能跟语言密不可分。人类的思想,科技、历史、文明都是通过语言文字来记载和承载的。
也因此,自然语言跟机器语言、数学语言相比最大的不同是存在规则模糊性和歧义性(即语言可以有各种理解方式),特别是当各种模糊性和歧义性组合在一起,很容易就形成一个难以解决的爆炸性问题,这就意味着需要有一种类似于今天 的大模型这样的「智能体」或者说,需要一种「具备智力」的工具和解决方法出现。大模型能学会理解和使用人类语言,也就意味着它有能力在各种复杂的事物中寻找模式和规则,然后用这些规则做推理。
我们可以从技术演进的角度来看,过去几十年来,科学家一直在寻求解决知识的表示以及知识调用的方法(可以说每次知识表示和调用方式的转变都会引起产业界巨大的变革)。
在大规模出现之前,知识最早是以数据库的方式存储在计算机内部,你想调用它就需要 SQL 语句等,需要人去适应机器,即使是这样今天看起来比较「Low」的技术,当时也产生了很多伟大的公司,如 Oracle 等。
后来,大量的知识是存储在互联网里,这种知识是非结构化存储的,包括文本、图像,甚至视频等,要想调用这里面的知识,我们就不需要学 SQL 语句,只要用关键词,通过搜索引擎的方式就可以把存储在互联网中的知识调用出来。现在 ChatGPT 仍然会存互联网的知识,但是它不是以显示的方式存储,而是以参数的方式存储在大模型中。
ChatGPT以及一系列超大规模预训练语言模型的成功,为自然语言处理带来新的范式变迁——即从以BERT为代表的预训练+精调(Fine-tuning)范式,转换为了以GPT-3为代表的预训练+提示(Prompting)的范式。
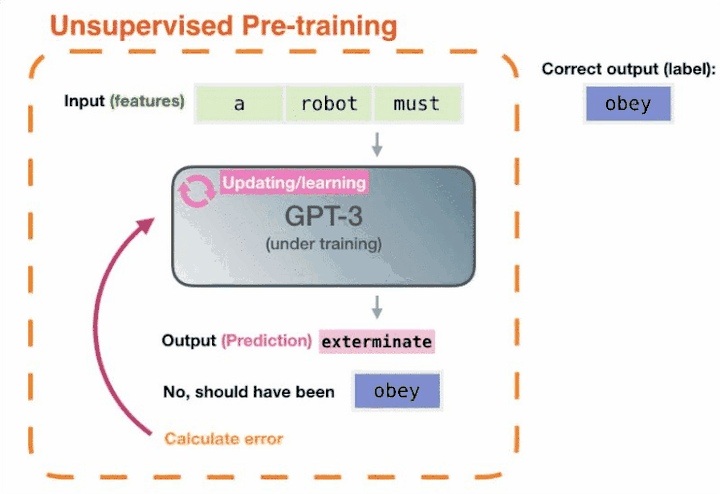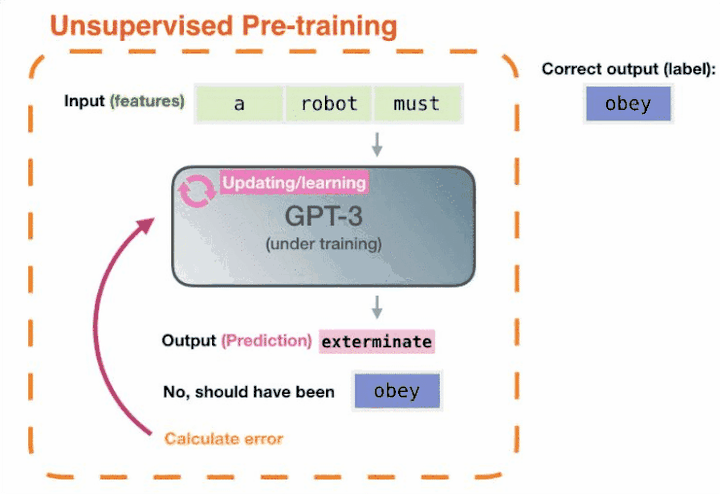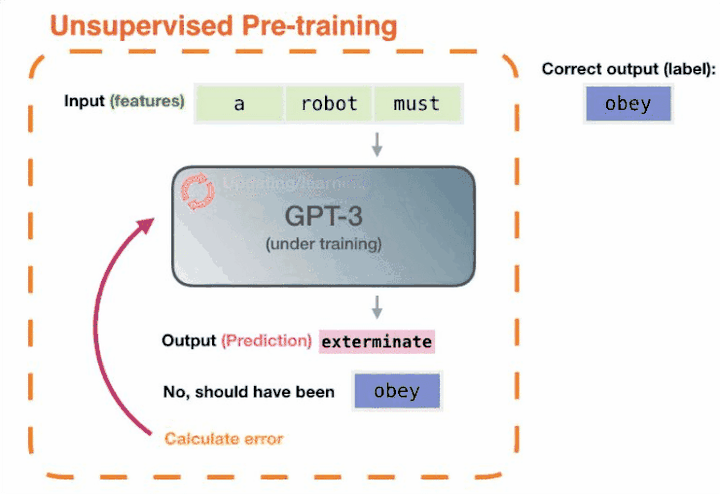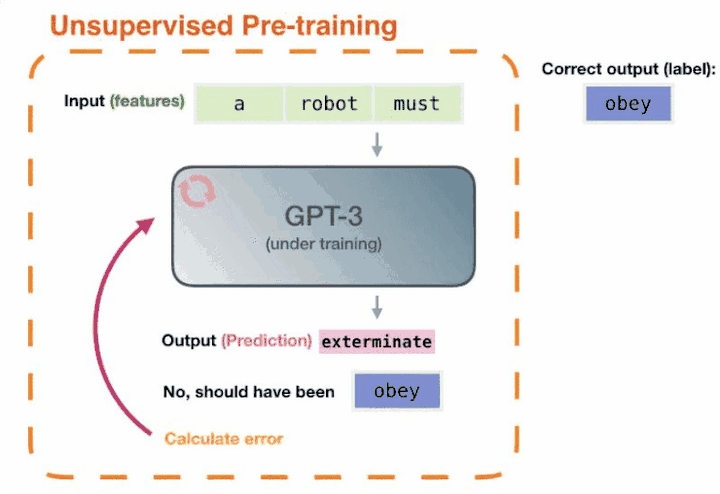
我们再回过头来看,GPT-3 两年前就能完成这样的任务,但为什么没有引起这么大的轰动呢?因为它没有解决好另外一部分问题,即怎样把这些知识调用出来。而ChatGPT就很好的解决了这个问题——通过自然语言的方式就可以很好的把这些知识调用出来。
ChatGPT 等于把这两块打通了,让计算机有了智能涌现(顿悟)。这才引发了人工智能方向性的改变。说白了,也就是大模型在学习人类自然语言的同时,其实是把语言承载的知识也都学会了,TA能自己从数据里总结规律。

这也正是GPT不同寻常的地方——传统的计算机技术,由基于公式和统计,可以做非常精确的计算。而GPT做的,不是基于「已有命令「行事,其实这就具备了人类的本领:观察世界,总结规律,获取新知识。
不过,尽管今天的大模型能够生成非常连贯而有逻辑性的语篇,对语言自身规律的掌握已经达到甚至超过普通人的水平。但是,对语言所负载的知识、经验,尤其是道德、文化、价值观等的把握,大模型还需要向人学习。
这背后,是因为现阶段,人工智能的本质,仍然只是一种数学统计模型的具体应用。说白了,本质上还是一个计算器。只是这个计算公式超级复杂,运算速度超快而已(所谓的「大力出奇迹「)。

所以很多人都在期待通用人工智能的来临,期待未来AI能用这些知识解决复杂的问题,像人一样进行推理、发明和创造。从这个意义上来说,从语言到知识再到智能,这就算是大模型到通用人工智能的总体路线了吧。











