这是个直指大模型本质的好问题,我觉得也是大模型研究里最重要的问题,应该没有之一。当然也有不少人认为大模型就是鹦鹉学舌,没有智能,如果这样就架空了这个问题,没有的东西当然无需解释其背后的原因。当然,我个人倾向认为大模型具备真正意义上的智能,后面内容都试图在证明这一点。
关于智能、AGI与SAI
首先,什么是智能?简化地理解,可以把「智能」理解为完成复杂任务的能力集合 E 。我们可以把能比较好地完成某个具体问题A的能力叫做「A任务智能」,不论解决这个问题的主体是人(Carbon-E,碳基能力集)还是机器(Silicon-E,硅基能力集),这个不重要,重要的是问题解决得是否足够好。比如我们可以有翻译智能(是否能够实现完美翻译)、情感计算智能(是否能够准确判断情感倾向)等。我们一般所说的通用智能,指的是这些能力构成的合集 E 。
形式化地说,假设解决某个具体问题A的能力定义为函数y=f_{taskA}(x) ,意味着对于输入 x ,通过 f 函数映射能够给出完美的标准答案 y (意思是在测试集合上任务A准确率足够高),比如翻译函数 f_{translate}(x) ,可以把英文翻译成中文,再比如摘要函数 f_{summarize}(x) ,可以给出好的主旨内容……。所以,我们说的通用智能,就是很多复杂任务函数的集合 E=\{f_{taskA}(x),f_{taskB}(x)….f_{taskX}(x)\} 。达成这种通用人工智能的具体主体,可以是人脑这种碳基湿件(f_{task}^{carbon}(x) ),也可以是电脑这种硅基干件( f_{task}^{silicon}(x) )。所谓人类智能,无非是说实现能力集合 E 的主体是人,而AGI(通用人工智能)无非是说实现能力集合E的主体是GPU,如此而已。
假设每个任务我们都可以量化评估,那么当下述条件成立时:
Condition: \{f_{taskA}^{silicon}(x)>= f_{taskA}^{carbon}(x) \& f_{taskB}^{silicon}(x)>= f_{taskB}^{carbon}(x)…..\& f_{taskX}^{silicon}(x)>= f_{taskX}^{carbon}(x)|f_{task}(x)\in E\}
也就是说,如果每项任务,机器都做得和做这个任务最好的人差不多或者比人做得好,那么我们就得到了AGI。当然这是种比较严格的要求,能够满足上述条件的其实已经是超人工智能(Super Artificial Intelligence, SAI)了,因为人作为一个群体,领域专家和普通人做一个任务效果也是天差地别的,如果我们把这里的人定义为领域专家,则是一种对AGI相对高的要求,而如果是普通人,则是相对低的一种AGI要求。
所谓图灵测试,就是指的构造一个测试集合TestSet(x)=\{TaskA(x_1),TaskB(x_2)…...TaskX(x_n)\} ,帘幕背后一个Carbon-E,一个Silicon-E,用来判断上述条件是否成立。不过话说回来,图灵测试是对AGI的「部分降格测试」,就是说即使你是SGI,也得在能力集合E中的某些任务方面降低智商,表现得弱一点才能通过图灵测试,因为如果你表现得过于强大反而让人很容易判断出「GPU你不是人」。所以图灵测试其实是弱化了上述条件,把里面的大于等于换成了「约等于」,而且图灵测试里的Carbon-E指的是人类的平均水准,GPU在某个任务上表现的太强或者太弱都会被轻易分辨出来。将来某一天,要想让Silicon-E通过图灵测试,很可能需要有意地调低某些方面的能力才行。
大语言模型学到了怎样的智能
大语言模型通过自回归语言模型任务(Autoregressive Language Model),以预测Next Token的方式,利用Transformer结构,从海量数据中自监督得学到了能力集合E中的很多能力,在很多任务上的能力可以和人能力相当或超过人类,当然仍然有不少人类具备的能力它仍然做得很差,无法与人类相比,这是为何我们说大语言模型是通向AGI的一条可行道路,但是目前肯定还未达成AGI的原因。
从上面我们对AGI的形式化描述可看出,顺着这条道路往下走,就是找出那些大语言模型还做得不够好的任务E_{sub}=\{f_{task_i}(x),i=1...k\} ,然后逐一加强大模型在这些方面的能力。所以这个事情继续往后走,会面临三种可能的未来场景:
场景一:未来我们能够获得AGI,且是一种渐进达成的AGI,就是通过逐渐攻克 E_{sub} 里的任务来达成的,我们可以把这种可能称为「渐进智能派」。
场景二:某天AGI就突然爆发性地降临人世,这个概率不太大,但是并非完全不可能。只有一种情况下才会让这种场景发生,就是说Sub_E里的任务之所以做不好,都根源于共性的一个或者两个难题与原因,只要我们能够解决这一两个难题,那么所有问题迎刃而解,AGI一夜降临,我们可以把这种可能称为「突然降临派」。目前看「逻辑能力/数学能力」以及「图像理解」能力可能是其中的两个关键症结所在,所以不能排除哪一天我们有非常简单有效提升大模型这几种基本能力的方法,也许AGI会一夜到来。
场景三:存在另外一种可能,就是未来某天,我们发现大模型的现有机制,从根本上决定了很多人类具备的能力,它是不可能具备的,也就会否决掉大模型能够带来AGI的可能性,这样可能大模型的路子只能通向有限能力,我们需要重新找到一条能够达成AGI的新的道路。目前并不能排除这种可能性,因为我们对于大模型内在运行机制了解得太少,所以无法从机制角度作出能与否的判断。我们可以把这个情形称为「有限智能派」。
每人看法不同,我个人偏乐观一些,觉得上述三个场景的出现概率大概会是:渐进智能派70%的可能性;突然降临派20%的可能;有限智能派10%的可能性。这个问题真正的答案我相信未来两到三年内就会揭晓。
如果我们归纳下现有对大模型机制解释(Mechanistic Interpretation,MI)的研究结果,当然,目前机制解释还没有深入到能直接给出大模型是怎样的方式学到了什么样的智能这种程度,不过大脉略看样子已经初步展现出来。如果在现有研究基础上做一些简单推论,大致可以看出大语言模型形成了怎样的智能。我今年5月份在之前的
里也大致探讨过这个问题,目前看有些具体细节可能需要做一些小修正,但是大逻辑目前感觉并没有什么问题,这里算是结合最近半年新的研究结论做个总结。
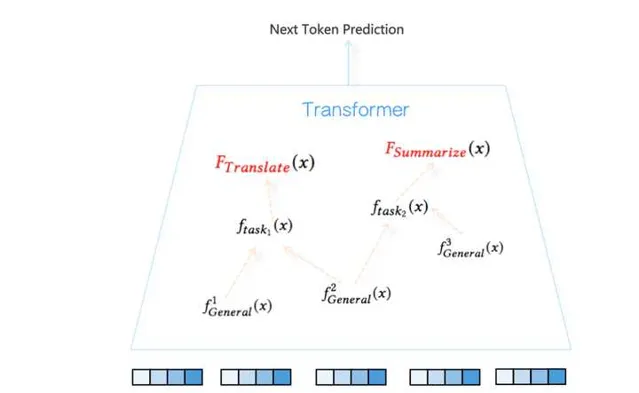
我们知道,大语言模型在很多任务上效果是很好的,比如机器翻译超过了专业机器翻译系统、文本摘要能力也很强、代码能力也不错….。我们拿机器翻译来说,这说明大语言模型已经学到了一个很好的机器翻译函数 y=f_{translate}(x) ,但是机器翻译这个事情是非常复杂的,在Transformer内部大模型是怎么处理的呢?从目前研究结论看,具体解决某个任务,应该通过预训练过程,在Transformer内部形成了解决这个任务的特定任务回路(Circuits),当输入x和任务prompt(比如instruct=」翻译下面内容」)后,Transformer会由低向上地逐步激活各层这个回路涉及到的路径,并把信息逐步上传,最终到最上层token by token地输出正确答案。任务回路由Transformer特定层的特定self attention节点及特定FFN单元构成,attention负责从上文找到重点信息并拷贝到last token位置,负责关键信息集成,FFN负责对信息进行转换。从这点看,和人类大脑的运行机制是非常相似的,人类大脑解决不同任务也会激活特定的脑回路。(目前还没有研究找出机器翻译的回路,这个回路可能会比较复杂,不过已发现了很多相对简单任务的专用回路,我相信每个特定任务应该都能找到对应的神经网络回路)
大模型能做很多任务,意味着Transformer通过预训练形成了很多复杂回路,也就是说这些回路分别负责能力集合 E 中某个函数f的实现。于是问题来了,不同任务回路之间存在怎样的关系呢?我归纳了类似GPT这种大语言模型智能的所谓「智能三性」,即大模型的智能体现出了组合性、可复用性以及抽象性。
所谓「组合性」,指的是对于复杂的任务函数f来说,大模型通过组合若干简单的子任务回路来达成处理复杂事情的能力,就是类似f_{task}=f_1(f_2(x),f_3(x)) 这种,大模型存在完成特定功能的子回路,复杂回路由若干简单子回路构成,这体现了大模型通过「组合性」来拆解复杂任务的能力。
所谓「可复用性」,指的是某些相对简单的特定子回路,会出现在多个不同任务的任务回路中,形成了通用子回路被不同任务复用的情况,这个从道理上讲是很合理的,很明显子回路复用增加了模型参数的表达效率,使得模型参数能被更充分地利用。
所谓「抽象性」,指的是Transformer由低到高对输入内容的加工,抽象能力越来越强。底层主要对token以及n-gram的token片段进行表征,属于具体信息编码,在逐步上传过程中,会逐步出现抽象的神经元或者attention head,比如输入内容如果是英文或中文,上层会有专有的神经元进行表征响应,在神经网络中间层也会出现识别句子句法结构的神经元,再往上还会有更抽象的专用神经元。能够具备逐层抽象性是大模型具备高级智能的明显证据。
总体看,大语言模型形成智能的内部组织结构,看起来非常像我们写的代码的内在逻辑结构。比如一个复杂的程序可以拆分成组成模块,每个模块完成相对简单的功能,这体现了功能的组合性;有些基础模块被很多其它模块调用,这体现了功能的可复用性;由简单模块简单功能逐步到复杂功能解决复杂问题,这体现出了一定的抽象性。只不过,程序结构是人类智能赋予的外在组织形式,而大模型的内在运行机制和组织形式是在Next token prediction过程中自己学到的。
关于大模型智能的「组合性」以及「抽象性」在上面列的文章里有提到相关的研究,至于「可复用性」,当时在文中有提及,不过只是当时我个人的猜测,缺乏证据,下半年出现了相关研究,这里列两个证据。
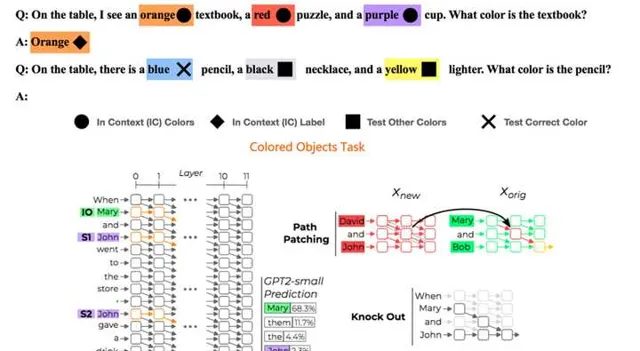
一个证据来自于「Circuit Component Reuse Across Tasks in Transformer Language Models」。它研究两个看着有些相似性的任务「Colored Objects Task 」和「Indirect Object Identfication Task」是否存在重叠的任务回路。两个任务具体干什么可以参考上图的例子,那么这两个任务是否会有重叠回路呢?
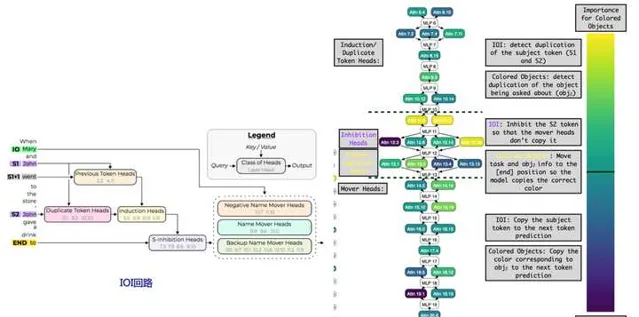
事实上,两者的功能主要是靠Transformer不同层的特定「注意力头」来实现的,且两个任务存在大量任务回路重叠。参考上图右侧子图,紫色代表IOI回路独有的attention head,黄色代表CO回路特有的attention head,浅蓝色的则是两者共享的attention head,可以看出两个任务存在大量回路重叠,回路重叠比例大约78%。上图左侧子图展示了IOI回路的内部构成,可以看出IOI回路又是由「Duplicate Heads」(负责识别上文中重复出现的内容)、「Induction Heads」(负责从上文拷贝特定的内容到next token输出)以及「S-inhibition Heads」(负责抑制上文中特定内容,不让它出现在next token输出中)等子回路构成,这体现出上面提及的大模型智能的「组合性」及「可复用性」(Induction Heads是广泛被使用的结构,比如ICL应该与这个注意力机制有密切关系)。
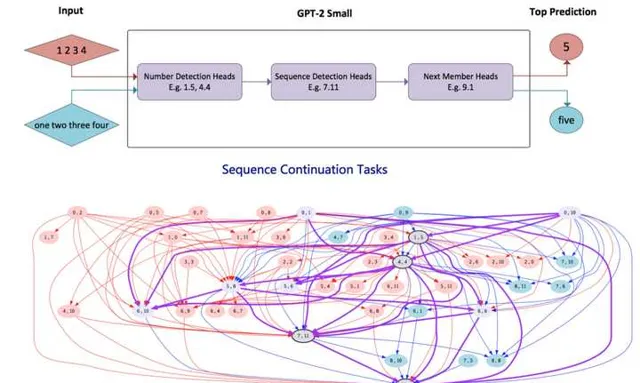
另外一个证据来自于「Locating Cross-Task Sequence Continuation Circuits in Transformers」。如上图所示,它探索对于比如数字形式的序列类似「1,2,3,4」以及单词形式的数字序列「one,two,three,four」这两种表面看似不同但内在有相似性的任务,回路是否有重叠。结论是两者存在大量回路重叠,这个内部回路涉及到了「数字检测」、「序列检测」以及「下一数字预测」子回路,这些子回路在这两个任务之间存在大量注意力头的共享。
上面两个证据说明了两个任务越是相似,则有越大比例的内部任务回路是共享的,这充分证明了大模型智能存在任务回路的「可复用性」。
为什么大语言模型可以形成智能
既然大语言模型可以很好完成很多任务,说明起码它具备了能力集合E中的很多能力。那么接下来的问题是:为何大语言模型可以通过预训练获得解决这些任务的能力呢?
目前并没有研究结论,因为这个课题看上去太宽泛了。不过,我相信这个问题的答案很可能极为简单,所有关于大模型秘密的答案应该都藏在预训练数据里。
这个答案很可能是(猜测,谨慎参考):大模型预训练通过自回归方式进行的Next Token Prediction,它是个非常好的代理任务(Proxy Task)。所谓代理任务,是说尽管我要做机器翻译任务,但是我不直接拿机器翻译数据和目标函数来训练模型,而是通过其它任务比如Next Token预测来实现。那为啥Next Token预测对很多任务的代理效果这么好呢?这是因为,大模型看似以自监督方式在做Next Token预测,但是因为预训练数据的多样性,对于很多任务来说,预训练数据中存在和这些任务有监督学习非常类似的数据,而正是这些数据,使得大模型可以通过看似自监督的方式在进行有监督训练,由此得到了解决很多任务的能力。目前虽无定论,但我相信正确答案离此不远。

我们拿具体任务来说,比如为何大语言模型翻译能力这么强?你看看上面这张图应该就明白为什么了。互联网上存在大量类似上面的双语网页,一句中文对应一句英文,当大模型在做Next Token Prediction的时候,当Next Token是中文对应的英文的时候,其实就是在做机器翻译的有监督学习,只不过是以Next token 这种看似自监督的模式而已。
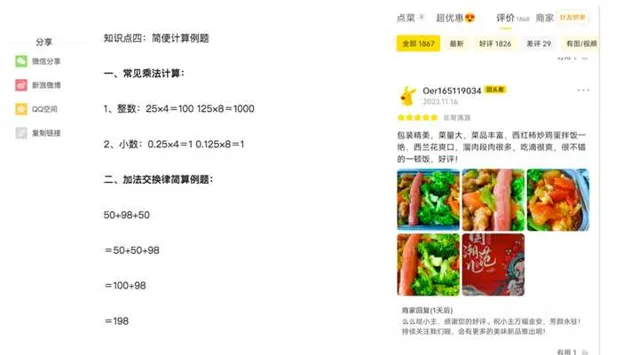
再比如,大模型的数学能力从何而来?情感计算能力从何而来?看看上面我给的两个例子大概就明白了,当Next Token预测到「等于号」的时候,以及当Next Token预测到「好评」的时候,如果预训练数据中大量存在此类数据,就是在对数学和情感判断做有监督训练,只不过是以Next Token的自监督形式存在而已,本质上还是在做有监督学习。很多其它能力的获得大概率跟这些情况是很类似的。
所以原则上,如果我们觉得大模型哪些能力还不够好,那很简单,把这个任务相关或类似的数据加进去,应该就会直接提升这种任务的效果。而这得益于Next Token Prediction这种好的代理任务,以及互联网开放数据的多样性,包含了类似有监督学习形式的任务数据。
总而言之,数据是大模型智能的最关键因素,数据多样性决定了大模型智能的下限(提升效果较差任务的效果),而数据质量决定了大模型智能的上限(提升效果较好任务的效果)。











