刚好写了一片文章,挪过来一下。
要回答这个问题,我们首先要知道数字音量控制和模拟音量控制是如何工作的。
先说模拟音量控制。放大器的模拟音量控制按照发展历程大抵分为两种形式。
机械式电位器
从ALPS的RK系列碳膜电位器到高端的分立电阻的段位式电位器(如索六万的电位器),都是这一思路。传统的滑动变阻器虽然能保证平滑的音量调整,但一来小音量声道差异太大,二来容易产生滑动噪声,因此少在高端产品中见到。而段位式电位器虽然避免了滑动产生的摩擦噪声并解决了小音量偏音的问题,但由于有限的体积和庞大的分立电阻,导致旋转开关无法做出足够多的档位,保证全幅值的精细调整。通常见到的30段左右的这种电位器,在60dB的调节范围内甚至达到了一档2-4dB,响度跳变太大导致它更加适用于长时间处于高音量位置的小功率放大器。这两种电位器基本都是加在放大器输出级的分压式电位器,因此也无法保证放大器的输出阻抗恒定,通常在低成本放大器中见到。
数控式电位器
这里说的数控式其实是我自己为了方便取的名字,指的并不是数字电位器。从MCU控制继电器/复用器切换分立电阻到用R2R DAC芯片内的集成电阻阵列等等玩出花的方式,都属于数控式电位器,其本质还是模拟电位器,因为这种音量控制方式会对信号通路上的 所有信号 包括噪声信号一起衰减。继电器切换电阻网络的方式本来是用于射频领域的,因为到了高频世界,由于接触阻抗的不确定性和各种玄学的分布参数,需要避免一切可能不稳定的宏观机械接触,而改用高精度的集成电子开关控制,集成的电子开关的ns级响应速度更是把继电器的ms级响应速度甩了几个数量级。使用特征阻抗恒定的Π或T型电阻网络,可以使得放大器在全幅值都能有一致的频响特性,再加上MCU的信号可以控制多路,使得电阻衰减网络的音量控制方案在档位和精度上都达到了前所未有的高度。实际上许多的「数字音量芯片」如PGA2311和MUSES72320也正是这种数控模拟音量的方式,只不过它们将电阻网络也靠先进的半导体工艺集成进了芯片里,靠着高精度的激光切割做到了很低的误差和失真。这样靠继电器或者电子开关对衰减电阻进行切换的方式,使其调整精度高,静态性能非常优秀
然而还有抗干扰能力更加卓越的方式,也是目前模拟音量控制中最理想的方案——R2R式音量控制。这种方式利用了R2R芯片每部的加权电阻网络,输入的音频电压先以2进制加权递减的方式进行V-I转换,然后通过外部控制数据来切换R2R网络的合成输出电流,最后再通过I-V转换形成最后输出信号。因为电流信号在R2R网络中不会受外部干扰,因此这种类似D/A转换的音量控制方式可以做到极低的底噪和极高的信噪比(就如R2R型DAC),并且档位非常多,对应于2进制的控制位数。这种音量控制由于布线较为复杂,没有成品IC可用,需要独立进行嵌入式开发,所以只有一些有实力的厂家在高成本的产品上应用。
数字音量控制
而数字音量控制,我们这里以PCM这种录音行业通用的调制方式来举例(实际上DSD的音量调整也是通过SDM 多bit量化的方式进行的,与此大同小异)。PCM有采样率和位深,每个采样点的位深记录了该点的幅值大小,也就是音量大小。
例如对于16bit的DAC,满幅值即0dBFS对应的采样点应该是
1111 1111 1111 1111 = 65535
而静音无声对应的采样点应该是
0000 0000 0000 0000 = 0
而数字音量调节就是靠CPU/DSP去进行计算设定衰减所对应的新采样数据。
我们来看一个例子:
16bit的DAC中如何表示30003这个数值的采样呢?
0111 0101 0011 0011 = 30003
如果我们要将这个音量调低10dB,也就是乘上20*lg(-10)=0.3162,那么在16bit二进制整数表示中也就是:
0010 0101 0001 0000 = 9488
但是我们发现,精确的计算结果应该是
30003*0.3162=9487.7817
和整数数值很接近了,只有23ppm也就是0.023‰的误差,但仍然不够精确。
那么如果我们想要降低更多的音量呢?比如现在我们要调低35dB:
0000 0010 0001 0110 = 534
由于是二进制整数计算,所以最后只能取整。而精确结果是:
30003*0.0177828 = 533.5372
这这时我们发现,虽然绝对误差值仍然在±0.5内,但相对误差值已经飙升到886ppm也就是0.886‰.
信号幅值一直在变化,所以即使数字音量衰减在某个采样点碰巧能够对齐到整数,在其他绝大部分采样点肯定是无法对齐的,会丢失小数部分的精度,这就是量化误差,会引起DAC表现中的本底噪声,这种本底噪声称为量化噪声。
如果我们提高数字音量的量化精度呢?
这里我们引入两个概念:
ENOB指有效位数(Effective Number of Bits),能反应一个系统的动态范围。
SNR指信噪比(Signal-to-Noise Ratio),顾名思义不多赘述。
对一个16bit的DAC,当音量衰减为-1dBFS的时候,SNR=97.63dB,ENOB=15.87:
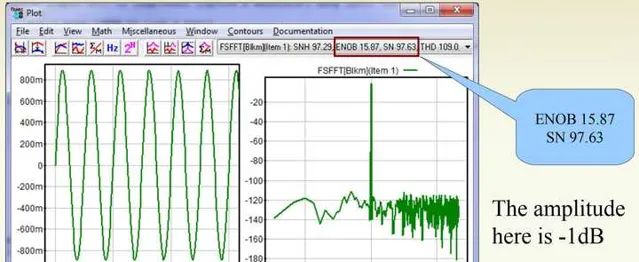
当将数字音量衰减到-10dBFS的时候,此时SNR=88.51,ENOB=14.35:
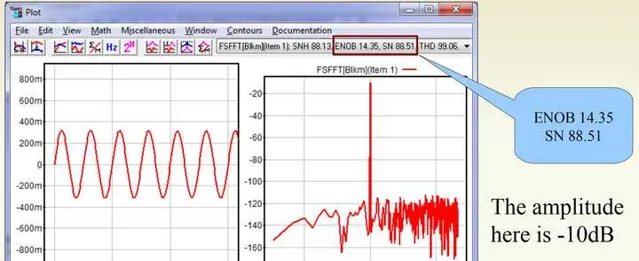
当将数字音量衰减到-35dBFS的时候,此时SN=63.18,ENOB=10.17:
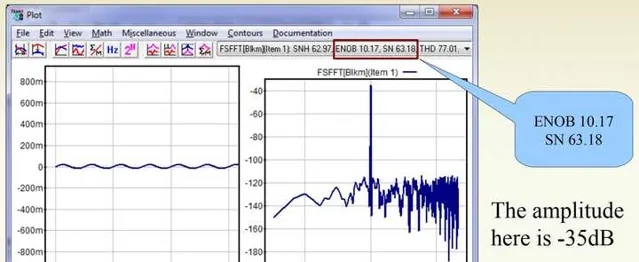
放在一起对比,我们发现,当数字音量在逐步衰减的时候,量化噪声并没有在下移。这就是为何大家通常会去避免数字音量控制。
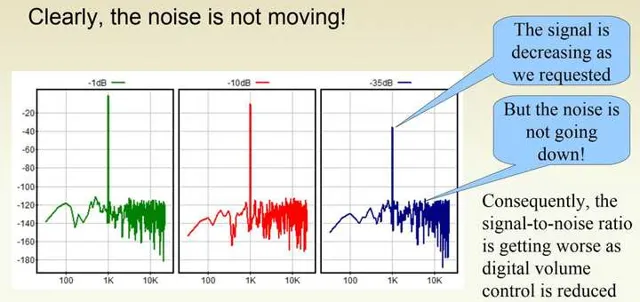
现在我们来看看模拟音量控制。在-1dBFS的时候SNR=98.53dB,ENOB=16.01:
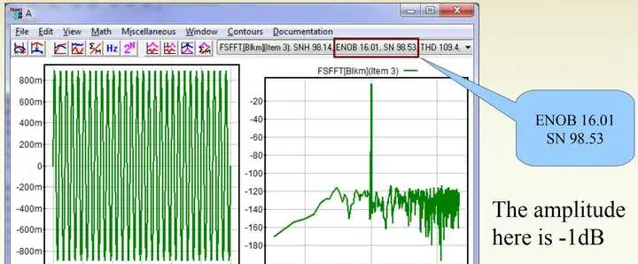
在-10dBFS的时候SNR=97.95dB,ENOB=15.94:
在-35dBFS的时候SNR=91.8dB,ENOB=14.94:
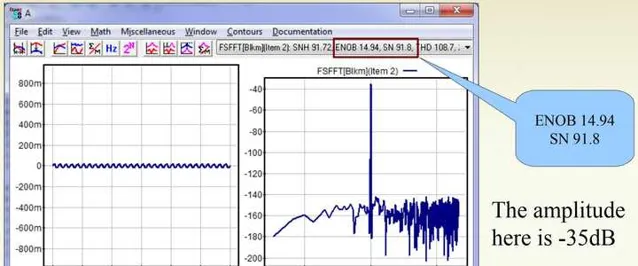
于是我们发现,在模拟音量控制进行音量衰减的时候,信号电平在衰减的同时,噪声电平也在几乎等比例地衰减。这使得整体SNR在调整音量的时候能够保持较高的水平。这也是为什么烧友们更偏向于使用模拟电位器的原因。

这样对比下来,还是模拟电位器有着比数字音量控制更优异的表现。那么我们可以优化改进数字音量吗?毕竟上面的例子中,DAC和信号都是16bit的,如果我们将16bit的信号喂进32bit DAC中会怎么样呢?
我们还是沿用上面的例子,那么在32bit的DAC中:
0111010100110011.0000000000000000 = 30003
我们同样进行-35dB的数字音量衰减,也就是乘上0.0177828,结果是:
0000001000010110.1000100110000100 = 533.5372
而在十进制的表示中,精确的结果也确实是:
30,003 * 0.3162 = 533.5372
看看某32bit DAC的官方测试指标:
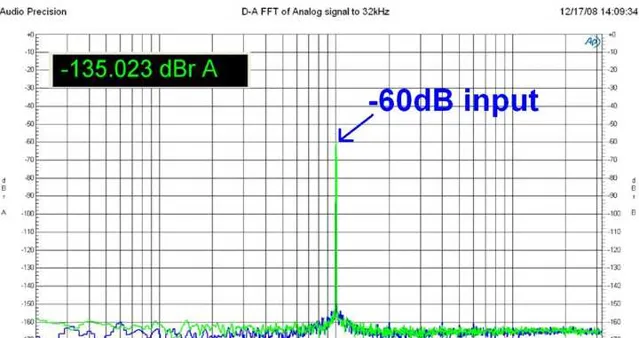
此时量化噪声水平已经接近于其本身的模拟底噪了。
我们发现,当数字音量控制有着足够的 计算位深 时,是几乎不会损失量化精度的。即使衰减加大,量化噪声也会随着信号电平一起衰减,直至达到整机的本底噪声电平。
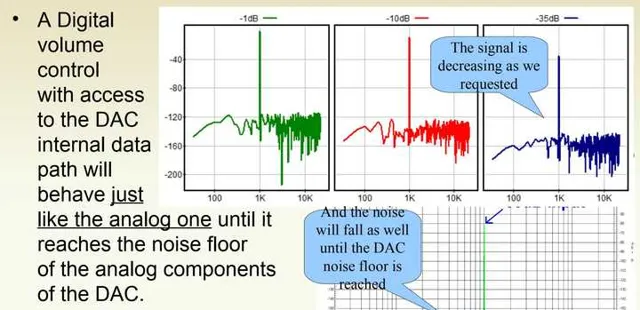
从这一段ESS给出的数据和讲义我们知道,在通常情况下,模拟音量控制还是有着更好的表现的,除非数字音量控制有着足够的有效位数,并且可以对进入DAC的数据直接进行计算(而不是位深不变的软件计算)。如果说有着底噪非常优异的模拟音量控制,那数字音量还是比不上模拟音量控制的。
以上是理论数据,我们再来看看一组硬件配置相近的同厂产品实测,其中一个是数控模拟电阻网络音量控制的旗舰,另一个是使用DAC内部32bit数字音量控制的次旗舰:
低增益最大输出的二者表现:


凭借更高的输出和更小的谐波,采用数字音量输出的「次旗舰」似乎有着比「旗舰」更低的总谐波失真+噪声,并且有着水平相当的互调失真。乍一看似乎「次旗舰」比「旗舰」更优秀,但如果我们把他们的输出电平均一化到50mV:
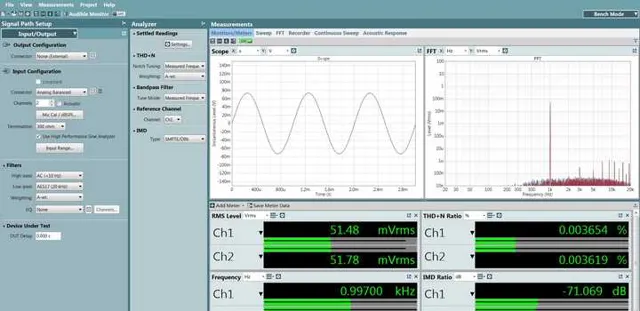
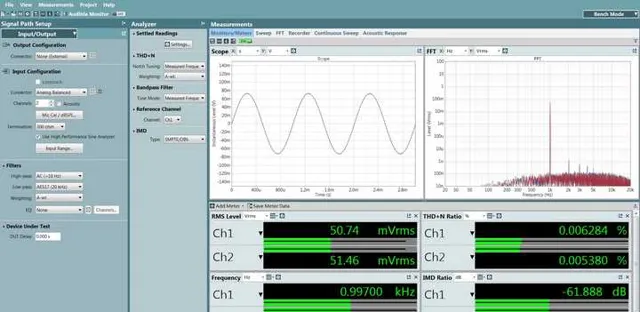
我们看到了和ESS讲义描述中基本符合的现象:采用模拟音量的「旗舰」,随着音量衰减,底噪有略微降低,而采用数字音量的「次旗舰」,随着音量衰减,底噪基本没有发生变化,因此在衰减到和日常听音音量相当的幅值水平时,谐波失真+噪声比「旗舰」落后了4dB左右,互调失真(非谐波成份)此时比「旗舰」落后了10dB。
甚至可以这么说,是模拟音量控制靠着小信号下的优势完成了整机指标的反超。
ESS关于数字音量和模拟音量的讲义:http://www. esstech.com/files/3014/ 4095/4308/digital-vs-analog-volume-control.pdf











