从数字电路的角度来看,如果CPU没有流水线,那么整个CPU的逻辑全部都是组合逻辑。
组合逻辑最大的问题就是如果一个tick(频率的倒数,也叫周期)涉及到的逻辑门很多,那么信号传输的路径就会很长,我们把对这个tick能跑多快影响最大,最长的那条路径叫做「关键路径」。
这条路径的长度越长,他所要经过的逻辑门个数越多,那么信号在这条路径上传输的延时就会变长。那么当频率太快的时候,可能前一个信号还在逻辑门里面跑,后一个信号马上又输入进了逻辑门,导致无法正常工作。所以组合逻辑的频率就不能跑的太快。
流水线就不一样了,由于流水线将一条很大的组合逻辑线路切割成了多个小Module来跑,每个Module之间的状态通过Register和Wire来传输。这样做的话,从单个信号来看,反而要跑的路径变长了,因为要多走一些Register和Wire。所以从这里可以看出题主的命题【CPU流水线设计的级越长,完成一条指令的速度就越快】是错误的。
我们平时用电脑,肯定不是开机之后只执行一条指令就关机了,而是有非常多的任务要做。那么这时候每个Module就可以在不同的时间针对不同的任务使用,而不是单周期里面一个组合逻辑里面的一个信号走完,在走下一个信号进去。所以从多任务处理来看,流水线增大了吞吐量,也就是每秒可执行的任务数量。
从这里还可以看出一个事实,就是加入了流水线机制之后,所需要的Register和Wire会增多,这些部件会直接增大IC芯片的制造成本。增大功耗和发热量。所以流水线是典型的用空间,功耗,发热换取较快的执行速度(主频)。
我们在用Intel(Altera)的FPGA芯片,在Quartus II开发套件里面有个工具叫做TimeQuest,它可以帮助我们做STA静态时序分析。时序约束的意思就是检查我们当前的数字电路设计,当一个信号走完整个top module(顶层设计模块)的时候,还剩多少slack(时间余量)。
当这个值为正的时候,说明在当前频率下,这个设计是没问题的,但是如果再超一点频的话,可能导致这个频率周期内,信号无法走完整个组合逻辑,就会导致slack为负数,显然这个设计是不太稳定的,虽然可能极端情况下(例如如果工作温度过高或者过低,FPGA供电电压上下波动影响,可能导致信号建立速度变快)可以正常工作,但是一般情况下仍然有失败,死机,数据错乱的风险。
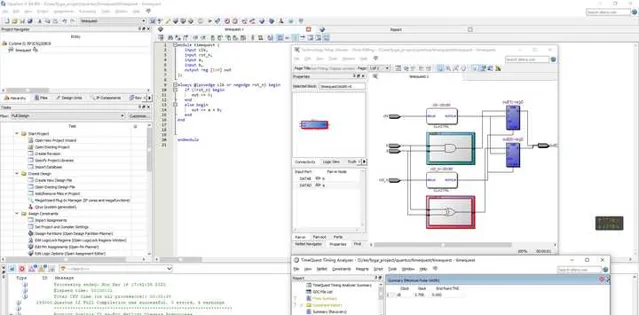
如图所示就是一个最简单的1 bit全加器在set clock为100MHz的情况下,在Intel(Altera) Cyclone II FPGA下的时序约束报告,slack报告时间余量还有7.758ns,说明我们约束这个器件在100MHz的主频下工作是OK的。也就是意味着这个加法器的设计在Cyclone II这款器件上是可以成功跑在100MHz的。
我们平时对CPU超频,其实和做STA静态时序分析差不多,例如利用BIOS这样的程序不断调整倍频,就像Quartus II里面不断调整PLL锁相环的倍频参数一样。然后开机跑各种烤鸡测试软件判断CPU执行各种任务是否正常,就相当于TimeQuest去验证每条路径的slack是否为正。因为执行一些普通Office等办公软件,可能只会用到一些整数操作指令,这些指令所涉及到的CPU芯片里面的组合逻辑电路比较少所以时间余量很大可以正常工作,而烤鸡软件烤FPU,烤SSE,AVX各种扩展指令集,这些电路因为带宽大,可能比较复杂,相当于把一些关键路径时序很恶劣的电路也去执行一遍,检查这些时序最恶劣的路径的时间余量是否充足。这也证明了为什么有些时候超频可以正常开机,但是开游戏或者视频转码就死机。
最终通过不断挑战试探,找出这块CPU里面关键路径的slack的最小值能到多少,也就是主频可以超到多高。
最后你问的问题【为什么不集成更多的扩展指令集呢。】
事实上RISC的目的就是用更少的指令集做更多的事情,所以集成更多指令集和设计理念是相反的。
指令集分为基础指令集和扩展指令集。基础指令集就是X86,比如mov,jmp那些的,扩展指令集是一些SSE,AVX指令集,这些指令集只有在处理向量,媒体计算才需要用到。即使用不到,他也会在CPU里面占用面积和制造成本,还有静态功耗。
RISC-V这个ISA指令集架构里面的基础指令集甚至只有I型整数加减计算指令,其他乘除法,浮点运算单元全部都作为扩展指令集来处理,这样的好处就是最大化兼容性。因为编译器和程序员只要兼容基础指令就好了。事实上从宏观统计来看,嵌入式领域的乘除法或者浮点运算用的都很少,或者计算量很小可以改成用基础指令集里面的加减法来模拟(乘法用多个加法模拟,除法用多个减法模拟)。
至于X86的CPU我研究的不是很多,但是我猜也是类似的思想。(Intel统计过基础指令集和现有指令集能覆盖50%以上的应用场景,所以剩下不到一半的那些本应该做进扩展指令集的指令都通过显卡GPGPU通用计算或者USB硬件加速卡或者PCI-E接入FPGA硬件加速卡来解决了)











