學習 SVM 的最好方法是實作一個 SVM,可講理論的很多,講實作的太少了。
假設你已經讀懂了 SVM 的原理,並了解公式怎麽推匯出來的,比如到這裏:
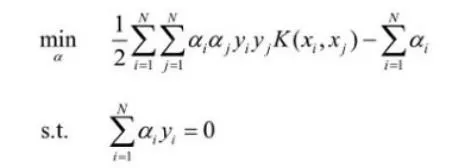
SVM 的問題就變成:求解一系列滿足約束的 alpha 值,使得上面那個函式可以取到最小值。然後記錄下這些非零的 alpha 值和對應樣本中的 x 值和 y 值,就完成學習了,然後預測的時候用:
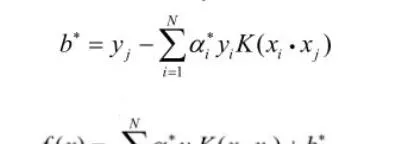
上面的公式計算出 f(x) ,如果返回值 > 0 那麽是 +1 類別,否則是 -1 類別,先把這一步怎麽來的,為什麽這麽來找篇文章讀懂,不然你會做的一頭霧水。
那麽剩下的 SVM 實作問題就是如何求解這個函式的極值。方法有很多,我們先找個起點,比如 Platt 的 SMO 演算法,它後面有虛擬碼描述怎麽快速求解 SVM 的各個系數。
第一步:實作傳統的 SMO 演算法
現在大部份的 SVM 開源實作,源頭都是 platt 的 smo 演算法,讀完他的文章和推導,然後照著虛擬碼寫就行了,核心程式碼沒幾行:
target = desired output vector
point = training point matrix
procedure takeStep(i1,i2)
if (i1 == i2) return 0
alpp = Lagrange multiplier for i1
y1 = target[i1]
E1 = SVM output on point[i1] – y1 (check in error cache)
s = y1*y2
Compute L, H via equations (13) and (14)
if (L == H)
return 0
k11 = kernel(point[i1],point[i1])
k12 = kernel(point[i1],point[i2])
k22 = kernel(point[i2],point[i2])
eta = k11+k22-2*k12
if (eta > 0)
{
a2 = alpp + y2*(E1-E2)/eta
if (a2 < L) a2 = L
else if (a2 > H) a2 = H
}
else
{
Lobj = objective function at a2=L
Hobj = objective function at a2=H
if (Lobj < Hobj-eps)
a2 = L
else if (Lobj > Hobj+eps)
a2 = H
else
a2 = alpp
}
if (|a2-alpp| < eps*(a2+alpp+eps))
return 0
a1 = alpp+s*(alpp-a2)
Update threshold to reflect change in Lagrange multipliers
Update weight vector to reflect change in a1 & a2, if SVM is linear
Update error cache using new Lagrange multipliers
Store a1 in the alpha array
Store a2 in the alpha array
return 1
endprocedure
核心程式碼很緊湊,就是給定兩個 ai, aj 然後叠代出新的 ai, aj 出來,還有一層迴圈會不停的選擇最需要被最佳化的系數 ai, aj,然後呼叫這個函式。如何更新權重和 b 變量(threshold)文章裏面都有說,再多偵錯一下,可以用 python 先偵錯過了,再換成 C/C++,保證得到一個正確可用的 svm 程式,這是後面的基礎。
第二步:實作核函式緩存
觀察下上面的虛擬碼,開銷最大的就是計算核函式 K(xi, xj),有些計算又反復用到,一個 100 個樣本的數據集求解,假設總共要呼叫核函式 20 萬次,但是 xi, xj 的組和只有 100x100=1萬種,有緩存的話你的效率可以提升 20 倍.
樣本太大時,如果你想儲存所有核函式的組和,需要 N*N * sizeof(double) 的空間,如果訓練集有 10 萬個樣本,那麽需要 76 GB 的記憶體,顯然是不可能實作的,所以核函式緩存是一個有限空間的 LRU 緩存,SVM 的 SMO 求解過程中其實會反復的用到特定的幾個有限的核函式求解,所以命中率不用擔心。
有了這個核函式緩存,你的 svm 求解程式能瞬間快幾十倍。
第三步:最佳化誤差值求解
註意看上面的虛擬碼,裏面需要計算一個估計值和真實值的誤差 Ei 和 Ej,他們的求解方法是:
E(i) = f(xi) - yi
這就是目前為止 SMO 這段為程式碼裏代價最高的函式,因為回顧下上面的公式,計算一遍 f(x) 需要 for 迴圈做乘法加法。
platt 的文章建議是做一個 E 函式的緩存,方便後面選擇 i, j 時比較,我看到很多簡易版本 svm 實作都是這麽搞得。其實這是有問題的,後面我們會說到。最好的方式是定義一個 g(x) 令其等於:
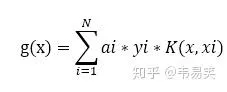
也就是 f(x) 公式除了 b 以外前面那一坨最費時的計算,那麽我們隨時可以計算誤差:
E(j) = g(xj) + b - yj
所以最好的辦法是對 g(x) 進行緩存,platt 的方法裏因為所有 alpha 值初始化成了 0,所以 g(x) 一開始就可以全部設定成 0,稍微觀察一下 g(x) 的公式,你就會發現,因為去掉了 b 的幹擾,而每次 SMO 叠代更新 ai, aj 參數時,這兩個值都是線性變化的,所以我們可以給 g(x) 求一個關於 a 的偏導,假設 ai,aj 變化了步長 delta,那麽所有樣本對應的 g(x) 加上一個 delta 乘以針對 ai, aj 的偏導數就行了,具體程式碼類似:
double
Kik
=
kernel
(
i
,
k
);
double
Kjk
=
kernel
(
j
,
k
);
G
[
k
]
+=
delta_alpha_i
*
Kik
*
y
[
i
]
+
delta_alpha_j
*
Kjk
*
y
[
j
];
把這段程式碼放在 takeStep 後面,每次成功更新一對 ai, aj 以後,更新所有樣本對應的 g(x) 緩存,這樣透過每次叠代更新 g(x) 避免了大量的重復計算。
這其實是很直白的一種最佳化方式,我查了一下,有人專門發論文就講了個類似的方法。
第四步:實作冷熱數據分離
Platt 的文章裏也證明過一旦某個 alpha 出於邊界(0 或者 C)的時候,就很不容易變動,而且虛擬碼裏也是優先再工作集裏尋找 > 0 and < C 的 alpha 值進行最佳化,找不到了,再對工作集整體的 alpha 值進行叠代。
那麽我們勢必就可以把工作集分成兩個部份,熱數據在前(大於0小於C的alpha值),冷數據在後(小於等於0 或者大於等於 C 的alpha)再後。
隨著叠代加深,會發現大部份時候只需要再熱數據裏求解,並且熱數據的大小會逐步不停的收縮,所以區分了冷熱以後你的 SVM 大部份都在針對有限的熱數據叠代,偶爾不行了,再全部叠代一次,然後又回到冷熱叠代,效能又能提高不少。
第五步:支持 Ensemble
大家都知道,透過 Ensemble 可以讓多個不同的弱模型組和成一個強模型,而傳統 SVM 實作並不能適應一些類似 AdaBoost 的整合方法,所以我們需要做一些改動。可以讓外面針對某一個分類傳入一個「權重」過來,修正 SVM 的辨識結果。
最傳統的修改方式就是將不等式約束 C 分為 Cp 和 Cn 兩個針對 +1 分類的 C,和針對 -1 分類的 C。修改方式是直接用原始的 C 乘以各自分類的權重,得到 Cp 和 Cn,然後叠代時,不同的樣本根據它的 y 值符號,用不同的 C 值帶入計算。
這樣 SVM 就能用各種整合方法同其他模型一起組成更為強大精準的模型了。
實作到這一步你就得到了功能上和效能上同 libsvm 類似的東西,接下來我們繼續最佳化。
第六步:繼續最佳化核函式計算
核函式緩存非常消耗記憶體,libsvm 數學上已經沒得挑了,但是工程方面還有很大改進余地,比如它的核緩存實作。
由於標準 SVM 核函式用的是兩個高維向量的內積,根據內積的幾個條件,SVM 的核函式又是一個正定核,即 K(xi, xj) = K(xj, xi),那麽我們同樣的記憶體還能再多存一倍的核函式,效能又能有所提升。
針對核函式的計算和儲存有很多最佳化方式,比如有人對 NxN 的核函式矩陣進行采樣,只計算有限的幾個核函式,然後透過插值的方式求解出中間的值。還有人用 float 儲存核函式值,又降低了一倍空間需求。
第七步:支持稀疏向量和非稀疏向量
對於高維樣本,比如文字這些,可能有上千維,每個樣本的非零特征可能就那麽幾個,所以稀疏向量會比較高效,libsvm 也是用的稀疏向量。
但是還有很多時候樣本是密集向量,比如一共 200 個特征,大部份樣本都有 100個以上的非零特征,用稀疏向量儲存的話就非常低效了,opencv 的 svm 實作就是非稀疏向量。
非稀疏向量直接是用陣列保存樣本每個特診的值,在工程方面就有很多最佳化方式了,比如用的最多的求核函式的時候,直接上 SIMD 指令或者 CUDA,就能獲得更好的計算效能。
所以最好的方式是同時支持稀疏和非稀疏,兼顧時間和空間效率,對不同的數據選擇最適合的方式。
第八步:針對線性核進行最佳化
傳統的 SMO 方法,是 SVM 的通用求解方法,然而針對線性核,就是:
K(xi, xj) = xi . xj
還有很多更高效的求解思路,比如 Pegasos 演算法就用了一種類似隨機梯度下降的方法,快速求 svm 的解權重 w,如果你的樣本適合線性核,是用一些針對性的非 SMO 演算法可以極大的最佳化 SVM 求解,並且能處理更加龐大的數據集,LIBLINEAR 就是做這件事情的。
同時這類演算法也適合 online 訓練和並列訓練,可以逐步更新的方式增量訓練新的樣本,還可以用到多核和分布式計算來訓練模型,這是 SMO 演算法做不到的地方。
但是如果碰到非線性核,權重 w 處於高維核空間裏(有可能無限維),你沒法梯度下降叠代 w,並且 pegasos 的 pdf 裏面也沒有提到如何用到非線性核上,LIBLINEAR 也沒有辦法處理非線性核。
或許哪天出個數學家又找到一種更好的方法,可以用類似 pegasos 的方式求解非線性核,那麽 SVM 就能有比較大的進展了。
後話
上面八條,你如果實作前三條,基本就能深入理解 SVM 的原理了,如果實作一大半,就可以得到一個類似 libsvm 的東西,全部實作,你就能得到一個比 libsvm 更好用的 svm 庫了。
上面就是如何實作一個相對成熟的 svm 模型的思路,以及配套最佳化方法,再往後還有興趣,可以接著實作支持向量回歸,也是一個很有用的東西。
--
相關閱讀:
韋易笑:kNN 的花式用法











