更全面的参考AI岗位面试题整理
大模型相关
1.了解Transformer吗?底层是什么结构?cuda中如何优化?
Transformer是一种基于注意力机制的序列模型,最初由Google的研究团队提出并应用于机器翻译任务。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer仅使用自注意力机制来处理输入序列和输出序列,因此可以并行计算,极大地提高了计算效率。
底层结构 :
Transformer的底层结构主要包括输入层、词嵌入层、编码器和解码器层以及输出层。
- 输入层:将输入的句子中的每个词表示成一个向量,然后输入到Transformer模型中。
- 词嵌入层:将输入层的向量作为输入,将每个词转化成一个更高维度的向量,以便模型可以更好地处理这些信息。
- 编码器和解码器层:Transformer模型的核心部分,它包含了若干个编码器和解码器层,负责将输入序列编码成一个稠密的向量表示,然后将这个向量解码成输出序列。
- 输出层:将解码器层的输出转化成输出序列中的词的概率分布。
CUDA中如何优化 :
在CUDA中优化Transformer模型主要涉及以下几个方面:
- 内存优化 :由于Transformer模型的计算涉及到大量的张量操作和内存访问,因此优化内存使用对于提高性能至关重要。可以使用半精度(例如float16)将张量保存在内存中,以减少内存占用。然而,当以较低精度计算梯度时,某些值可能太小,以至于被视为零,这种现象被称为「溢出」。为了防止「溢出」,原始论文的作者提出了一种梯度缩放方法。PyTorch从1.6的版本开始提供了一个包:torch.cuda.amp,具有使用自动混合精度所需的功能(从降低精度到梯度缩放),自动混合精度作为上下文管理器实现,因此可以随时随地的插入到训练和推理脚本中。
- 并行计算 :由于Transformer模型的并行计算能力很强,可以利用CUDA的GPU加速计算。通过合理安排线程和数据划分,可以最大化GPU的利用率,提高模型的计算速度。
- 优化算法 :针对Transformer模型的计算特点,可以采用一些优化的算法来进一步提高性能。例如,可以使用矩阵分解、低秩近似等技术来降低计算的复杂度。
- 缓存优化 :由于Transformer模型中涉及大量的数据访问,因此优化缓存的使用对于提高性能至关重要。可以通过合理安排数据布局、使用缓存友好算法(如kv cache等)等方式来提高缓存的利用率。
2.对大模型的理解。
大模型是指包含超大规模参数(通常在十亿个以上)的神经网络模型,具有以下特征:
- 巨大的规模:大模型包含数十亿个参数,模型大小可以达到数百GB甚至更大。这种巨大的模型规模为其提供了强大的表达能力和学习能力。
- 多任务学习:大模型通常会一起学习多种不同的NLP任务,如机器翻译、文本摘要、问答系统等。这可以使模型学习到更广泛和泛化的语言理解能力。
- 强大的计算资源:训练大模型通常需要数百甚至上千个GPU,以及大量的时间,通常在几周到几个月。这可以加速训练过程而保留大模型的能力。
- 丰富的数据:大模型需要大量的数据来进行训练,只有大量的数据才能发挥大模型的参数规模优势。
大模型在自然语言处理领域得到广泛应用,并正在彻底改变NLP任务的状态,催生出更强大、更智能的语言技术。大模型是AI发展的重要方向之一。同时,大模型也具有在各种自然语言处理任务中表现出色的能力,例如文本分类、情感分析、摘要生成、翻译等。大模型可以用于自动写作、聊天机器人、虚拟助手、语音助手、自动翻译等多个应用领域。
此外,大模型通常包含数十亿个参数,这使得它们能够捕捉到大规模数据中的复杂模式和规律,从而预测出更加准确的结果。这也是为什么大模型在自然语言处理等领域表现出色,能够应对更复杂、更庞大的数据集或任务的原因之一。
3.知道Faster Transformer吗?如何实现的?
FasterTransformer是一个库,用于实现基于Transformer的神经网络推理的加速引擎。对于大模型,它以分布式方式跨越许多GPU和节点进行推理。FasterTransformer包含Transformer块的高度优化版本的实现,其中包含编码器Encoder和解码器Decoder部分。基于FT可以运行完整的编码器-解码器架构(如T5大模型)以及仅编码器模型(如BERT)或仅解码器模型(如GPT)的推理。
使用cublas优化GEMM
矩阵乘法外的kernel:尽可能融合
4.Paged Attention有了解吗?
Paged Attention是一种对kv cache所占空间的分页管理策略。这是一种以内存空间换取计算开销的手段,与现今大模型训练中的recompute中间activation用于bwd的策略(以计算开销换内存空间)相反。
其原理是受操作系统中的分页(paging)算法启发,将序列中的KV缓存划分为KV块,每个块包含固定数量tokens的键(K)和值(V)向量。在注意力计算期间,Paged Attention内核分别识别和获取不同的KV块,这些块在物理内存上可能不连续。然后将查询向量与块中的键向量相乘得到部分注意力得分,再乘以块中的值向量得到最终注意力输出。这种设计使得KV块可以存储在非连续的物理内存中,从而使内存管理更加灵活。
Paged Attention极大的节约了keys values matrix的占用空间,可以做更大batch size的推理,目前tensorRT-LLM和vLLM都有这个策略。
深度学习相关
1.cuda中如何写Softmax?某个参数过大如何解决?
Softmax函数常在神经网络输出层充当激活函数,将输出层的值通过激活函数映射到0-1区间,将神经元输出构造成概率分布,用于多分类问题中,Softmax激活函数映射值越大,则真实类别可能性越大。
softmax的计算过程:
- 先做一个 ReduceMax 求最大值操作,得到输入每一行的最大值;
- 然后做一个 BroadcastSub 减法操作,拿输入每一行的各点减去每一行的最大值;
- 然后做一个自然指数Exp 操作,对输入每一行的各点计算指数;
- 然后做一个 ReduceSum 求和操作,对输入每一行的各点求得的指数映射做一个求和;
- 最后做一个 BroadcastDiv 除法操作, 拿输入每一行的各点求得的指数映射除以4中得到的和;
如果某个参数过大,可以使用对数变换或指数变换将其转化为一个较小的范围,然后再进行Softmax计算。例如,可以使用
log1p
或
exp
函数进行对数变换或指数变换。
2.Dropout和BatchNorm在训练和推理时有什么区别?
训练时:
推理时:
3.谈谈无监督学习算法
无监督学习算法是一种机器学习算法,它不需要预先标记的数据来训练模型。相反,它从无标签的数据中学习数据的隐藏模式或结构。这种算法主要用于找出数据的隐藏模式或结构,而不是预测特定的标签。
以下是几种常见的无监督学习算法:
- 聚类算法:这是最常用的无监督学习算法之一。它将数据分成几个组,使得同一组内的数据项相互之间非常相似,而与其他组的数据项非常不同。常见的聚类算法包括K-均值聚类、层次聚类等。
- 降维算法:这种算法被用来降低处理高维数据的复杂性,同时尽量保留其原始数据的特性。常见的降维算法有主成分分析(PCA)和t-分布邻域嵌入算法(t-SNE)等。
- 自编码器(AutoEncoders):这是一种神经网络,它学习如何有效地编码输入信息,然后如何将这些信息重建为原始输入的近似表示。它们被用于降维或者特征学习。
这些算法在许多领域都有应用,如图像识别、语音识别、推荐系统等。
GPU相关
1. 描述一下SM的结构,在写kernel的时候共享内存大小和寄存器文件数量需要注意吗?
GPU的SM(流式多处理器)结构是围绕一个流式多处理器(SM)的扩展阵列搭建的,通过复制这种结构来实现GPU的硬件并行。每个SM都能支持数百个线程并发执行,每个GPU通常有多个SM。
在写kernel的时候,共享内存大小和寄存器文件数量是需要考虑的。
- 共享内存大小:共享内存是SM中非常重要的组件,它被所有CUDA核心共享。在写kernel时,需要合理使用共享内存,以避免频繁的内存访问和数据拷贝,从而提高程序的效率和性能。如果需要传递大量数据到kernel中,或者需要频繁访问数据,可以考虑使用共享内存。
- 寄存器文件数量:寄存器文件是SM中的另一个重要组件,它被CUDA核心使用。每个CUDA核心都有一个完全流水线化的整数算术逻辑单元(ALU)和一个浮点单元(FPU),每个核心都有一个与之相关的寄存器文件。在写kernel时,需要注意不要使用过多的寄存器文件,因为每个寄存器文件都需要消耗一定的硬件资源。
2. 共享内存和寄存器分别应该存放哪些数据,其用量与SM上活跃的线程块的关系?
- 共享内存:
3. bank冲突是什么?描述具体结构,如何解决?
GPU Bank冲突是指在使用GPU进行并行计算时,不同的线程或线程块试图同时访问同一Bank中的不同地址,导致访问冲突。
具体结构方面,GPU的内存被划分为多个Bank,每个Bank可以独立地服务一个线程。当多个线程同时访问同一个Bank的不同地址时,就会发生Bank冲突。
解决GPU Bank冲突的方法有多种,以下是一些常见的解决方法:
- 优化数据布局:通过合理地布局数据,减少不同线程或线程块之间的数据重叠,从而减少Bank冲突的可能性。
- 使用不同的Bank:对于需要同时访问同一Bank的不同地址的情况,可以通过使用不同的Bank来避免冲突。例如,可以使用不同的Bank来存储不同的数据部分,或者使用不同的Bank来存储不同的线程或线程块的数据。
- 增加Bank数量:通过增加Bank的数量,可以增加每个Bank的独立性,从而减少Bank冲突的可能性。
- 使用多播机制:当一个warp中的多个线程同时访问一个Bank的相同地址时,可以使用多播机制将该地址广播给这些线程,从而避免Bank冲突。
4. 说一下分支冲突,如果warp内有冲突,部分符合if条件,部分符合else条件,是否需要等待?
GPU分支冲突是指在一个warp内部,如果一个线程的分支路径与其他线程的分支路径不同,就会发生分支冲突。当发生分支冲突时,GPU需要等待所有线程完成各自的分支路径,然后再继续执行。
如果warp内有冲突,部分线程符合if条件,部分线程符合else条件,那么GPU需要等待所有线程完成各自的分支路径。这意味着,即使部分线程已经满足条件并可以继续执行,其他线程也需要等待它们完成所有分支路径后才能继续执行。
GPU的分支冲突可能会导致性能下降,因为线程需要等待其他线程完成分支路径。在编写GPU代码时,需要尽量避免分支冲突的发生。可以通过优化数据布局、使用不同的Bank、增加Bank数量、使用多播机制等方法来减少分支冲突的可能性。
5.了解TensorCore的原理吗?
TensorCore是由深度学习引擎和特殊的硬件电路组成的,它可以执行高精度的矩阵乘法和矩阵加法运算,大大提高了深度学习模型中涉及到的矩阵计算的效率。TensorCore采用了16位浮点数(FP16)的数据格式,相对于传统的32位浮点数(FP32),它在存储和计算方面都具有更高的效率。
TensorCore的核心原理是混合精度计算。它可以将输入的FP16格式的矩阵乘法运算拆解成更小的矩阵乘法运算,然后通过一系列的指令和硬件电路将其计算得到的结果合并成最终的结果。这种混合精度计算的方式既保证了计算的精度,又提高了计算的速度和效率。
6.为什么用float4向量来存取数据?有什么好处?
使用float4向量来存取数据可以提高GPU编程的效率、节省内存空间、方便进行向量运算以及易于扩展。
- 高效的内存访问:GPU架构通常采用共享内存的方式,多个线程可以同时访问同一共享内存地址。使用float4向量可以充分利用这种并行访问的特性,提高内存访问的效率。
- 节省内存空间:与单独使用float类型的变量相比,使用float4向量可以减少内存占用。
- 高效的向量运算:GPU支持向量的运算操作,包括加法、减法、乘法、点积等。使用float4向量可以方便地进行这些运算操作,提高计算效率。
7.为什么使用双缓冲优化?了解cuda流和cuda graph吗?
使用双缓冲优化是为了解决帧缓冲区读取和刷新的效率问题。通过引入两个缓冲区,即双缓冲机制,GPU可以预先渲染好一帧放入一个缓冲区内,让视频控制器读取。当下一帧渲染好后,GPU会直接把视频控制器的指针指向第二个缓冲器。这样,效率会有很大的提升。
CUDA流表示一个GPU操作队列,该队列中的操作将以添加到流中的先后顺序而依次执行。可以将一个流看做是GPU上的一个任务,不同任务可以并行执行。使用CUDA流,首先要选择一个支持设备重叠(Device Overlap)功能的设备,支持设备重叠功能的GPU能够在执行一个CUDA核函数的同时,还能在主机和设备之间执行复制数据操作。支持重叠功能的设备的这一特性很重要,可以在一定程度上提升GPU程序的执行效率。
CUDA Graphs为CUDA中的工作提交提供了一种新模式。图是一系列操作,例如内核启动,由依赖关系连接,独立于其执行定义。这允许一个图被定义一次,然后重复执行。将图的定义与其执行分开可以实现许多优化:首先,与流相比,GPU启动成本降低,因为大部分设置都是提前完成的;其次,将整个工作流程呈现给CUDA可以实现优化,这可能无法通过流的分段工作提交机制实现。
8.除了MPI,有知道现在用的更多的GPU通信库吗?
除了MPI,现在常用的GPU通信库包括NCCL和CUDNN。
NCCL(Nvidia Collective Communications Library)是由Nvidia开发的库,专为多GPU和多节点环境中的高效通信而设计。它提供了一组API,用于实现数据并行计算中的集体操作,如广播、聚合和排序。NCCL在多GPU环境中表现出色,并且与CUDA紧密集成。
CUDNN(CUDA Deep Neural Network Library)是另一个由Nvidia开发的库,专为深度神经网络应用而设计。它提供了一组API和功能,用于实现高效的GPU加速神经网络计算。CUDNN提供了各种操作函数和算法,如卷积、池化、激活函数和损失函数等。它还支持各种神经网络架构,包括卷积神经网络、循环神经网络和全连接神经网络等。
这些库都为GPU通信提供了高效的解决方案,并支持大规模并行计算。它们与MPI类似,都提供了在分布式机器学习中实现GPU间通信的工具。
9.在Nsight Computing中,解释下L1 Cache命中率?
L1 Cache命中率是指程序在L1 Cache中成功找到所需数据的比例。在GPU计算中,由于数据在GPU内存和L1 Cache之间频繁移动,因此L1 Cache命中率对于性能至关重要。
通过关注L1 Cache命中率,可以了解程序中数据访问模式与GPU内存和缓存之间的交互情况。如果L1 Cache命中率较低,则意味着程序需要从GPU内存中读取数据,这可能导致性能下降。
10.GPU指令集优化方面了解吗?PTX相关的优化了解吗?
GPU指令集优化是提高GPU程序性能的重要手段之一。在GPU编程中,通过选择合适的指令集和优化指令的使用,可以减少内存访问、提高计算速度和减少功耗。
PTX(Parallel Thread Execution)是NVIDIA的GPU汇编语言,它提供了一套丰富的指令集,用于描述GPU上的并行计算任务。PTX优化主要是针对PTX指令的优化,包括指令的选择、调度和执行等方面。
在PTX优化方面,可以考虑以下几个方面:
- 指令选择:根据具体的计算任务和数据访问模式,选择合适的PTX指令,以最大化计算性能和效率。
- 指令调度:合理安排指令的执行顺序,减少依赖关系和冲突,提高指令的执行效率。
- 内存访问优化:通过减少内存访问次数、提高内存访问效率等方式,减少内存带宽的占用,提高计算性能。
- 循环展开:通过将循环展开为多个迭代并行执行的方式,减少循环的开销,提高计算性能。
11.GEMM是计算密集型还是访存密集型算子?
GEMM(General Matrix Multiply)是一种常见的矩阵乘法运算,可以应用于深度学习、科学计算、图像处理等领域。在GPU编程中,GEMM通常被视为一个计算密集型算子,因为它涉及到大量的乘法和加法运算。
然而,GEMM也可以被认为是访存密集型算子,因为它需要从内存中读取大量的数据。在GPU上执行GEMM时,通常会将输入矩阵和输出矩阵存储在GPU的显存中,然后通过GPU的并行计算能力来执行矩阵乘法操作。因此,GEMM既涉及到大量的计算操作,也涉及到大量的内存访问操作。
在实际应用中,为了提高GEMM的性能,通常会采用一些优化技术,如共享缓存、数据重用、矩阵分块等。这些优化技术可以减少内存访问次数和等待时间,提高程序的执行效率。因此,虽然GEMM既涉及到计算密集型操作也涉及到访存密集型操作,但通过优化技术可以将其转化为高效的计算操作。
12.cutlass中如何对GEMM进行优化的?
CUTLASS是一个NVIDIA的开源模板库,旨在提供一种用较小的成本写出一个性能不是那么差的GEMM的能力。CUTLASS内置了针对GEMM的meta schedule,能够让计算尽量掩盖访存延迟从而达到不错的性能。
在CUTLASS中,对GEMM进行优化的方式主要有以下几个方面:
- 缓存利用:利用GPU的缓存来减少内存访问次数。通过将数据缓存在GPU的缓存中,可以减少从内存中读取数据的次数,从而提高程序的执行效率。
- 数据重用:在GEMM中,经常需要重复使用相同的数据。通过将数据缓存在GPU的显存中,可以避免频繁地从内存中读取相同的数据,从而提高程序的执行效率。
- 矩阵分块:将大矩阵拆分成小块,然后分别进行计算。这样可以减少内存访问的次数,并且可以利用GPU的并行计算能力来加速计算。
- 优化循环结构:通过优化循环结构,可以减少循环次数和分支判断,从而提高程序的执行效率。
- 优化指令使用:通过选择合适的指令和优化指令的使用,可以提高程序的执行效率。例如,选择适合的乘法和加法指令,避免不必要的内存访问和数据转换等。
13. 知道TensorRT吗?部署过推理模型吗?
TensorRT是NVIDIA发布的深度学习模型推理优化器和部署工具。它能够实现高性能的推理,支持跨平台,包括NVIDIA GPU、CPU和FPGA等。
对于TensorRT的部署,它提供了API和工具,使得开发者能够将深度学习模型部署到云端、边缘和嵌入式设备上。TensorRT支持多种深度学习框架,包括TensorFlow、PyTorch、MXNet等,同时也支持多种编程语言,如Python、C++等。
在部署推理模型方面,TensorRT可以优化模型的计算性能、内存使用和能源效率等。它通过多种优化技术,如融合乘法运算、剪枝、量化、静态图优化等,实现高效的推理。同时,TensorRT也提供了多种API和工具,如TensorRT-API、TensorRT-Server等,方便开发者进行模型的部署和推理。
CPU相关
1.对Arm或者x86有什么了解?
Arm架构是一种精简指令集(RISC)处理器架构,它的特点是低功耗、低成本和高性能。Arm架构广泛应用于嵌入式系统设计,如手机、平板电脑、智能家居等。由于Arm架构的低功耗特点,它非常适合移动通讯领域,符合其主要设计目标为低耗电的特性。
x86架构是一种复杂指令集(CISC)处理器架构,它的特点是支持多种指令集和操作系统,具有较高的兼容性和扩展性。x86架构广泛应用于个人计算机、服务器、工作站等领域。由于x86架构的通用性和扩展性,它也适用于各种不同的应用场景,如游戏、科学计算、人工智能等。
在性能方面,Arm架构和x86架构各有优缺点。Arm架构具有低功耗和高性能的特点,但它的指令集相对较少,且不支持x86指令集和操作系统。而x86架构则具有较广泛的指令集和操作系统支持,但它的功耗相对较高,且价格也相对较高。
2.知道CPU的体系结构吗?介绍一下内存结构。
CPU的体系结构包括多个层次,从底层到高层依次是:
- 逻辑部件:包括算术逻辑运算单元(ALU)和移位操作器等,用于执行定点或浮点算术运算操作、移位操作以及逻辑操作,也可执行地址运算和转换。
- 控制部件:负责控制CPU的操作,包括数据、控制和状态的总线。
- 寄存器部件:包括通用寄存器、控制寄存器和状态寄存器等。通用寄存器可保存指令执行过程中临时存放的寄存器操作数和中间(或最终)的操作结果。
至于内存结构,通常包括以下几个层次:
- Cache:高速缓存(Cache)是一种位于CPU和主存(Main Memory)之间的容量小但存取速度高的存储器,用来存放CPU访问的主存地址映射表及相应的数据,也可以说,高速缓存就是数据与CPU间的一个「缓冲」。在高速缓存中的数据存放是CPU近期访问过的数据,如果CPU再次需要这些数据时,可以直接从高速缓存中读取,而不需要再从主存中读取。
- 主存:主存是计算机硬件的一个重要组成部分,也称内存或内储存器,其作用是存放指令和数据,并能由中央处理器直接随机存取。
- 外存:外存是指除计算机内存及CPU缓存以外的储存器,此类储存器一般断电后仍然能保存数据。常见的外存有硬盘、软盘、光盘等。
3.设计多CPU系统的时候需要注意什么?如何保证缓存一致性?
设计多CPU系统时,需要注意以下几个方面:
- 负载均衡:确保各个CPU之间的负载均衡,避免某些CPU过载而其他CPU处于闲置状态。
- 通信延迟:多CPU之间需要进行通信,因此需要考虑通信延迟对系统性能的影响。
- 内存一致性:多CPU访问同一内存区域时,需要保证内存一致性,避免出现数据不一致的问题。
为了保证缓存一致性,可以采用以下方法:
- 总线锁:通过总线锁机制,当一个CPU访问某个内存区域时,其他CPU无法访问该区域,直到第一个CPU完成访问。
- MESI协议:MESI协议是一种常用的缓存一致性协议,它定义了四种状态:Modified(修改)、Exclusive(独占)、Shared(共享)和Invalid(无效),用于表示缓存行在不同CPU之间的状态。
- MOESI协议:MOESI协议是MESI协议的扩展,增加了Owner(拥有)状态,用于表示缓存行在哪个CPU上。
- 写回策略:当一个CPU修改某个内存区域时,需要将该区域写回到主存中,其他CPU的缓存行也需要相应地更新。
- 写分配策略:当一个CPU需要写入某个内存区域时,需要先将该区域分配到缓存中,然后再进行写入操作。这样可以保证写入操作的一致性。
基本功
1.C++虚函数,使用场景,继承时,析构函数设定成虚函数。
C++中的虚函数主要用于实现多态性,允许子类重写父类的函数。使用场景主要包括需要动态绑定函数行为的场合,如:
- 抽象基类:虚函数允许派生类重写基类中的虚函数,使得在派生类中可以定义自己的行为。
- 动态绑定:虚函数使得在运行时根据对象的实际类型(子类类型)确定要调用的函数,实现了动态绑定。
- 接口实现:虚函数可以用于实现接口,使得派生类必须实现接口中的所有虚函数,从而实现了多态性。
在继承时,如果基类的析构函数不是虚函数,那么在派生类的对象销毁时,只会调用派生类的析构函数,而不会调用基类的析构函数。如果基类的析构函数是虚函数,那么在派生类的对象销毁时,会先调用派生类的析构函数,然后再调用基类的析构函数。这样可以确保对象被正确地销毁,避免了内存泄漏等问题。
因此,为了保证多态性和正确的内存管理,通常将基类的析构函数设置为虚函数。
2.C++三大特性,动态多态和静态多态。
C++中的三大特性是封装、继承和多态。
- 封装:封装是把抽象的数据(变量)和实现的方法(函数)封装在一起,形成一个对象。这样做的目的是隔离出影响范围,让代码更容易理解和维护。
- 继承:继承是从已有的类派生出新的类,新的类能够继承现有类的各种属性和行为,并且可以增加新的能力。继承可以提高代码的可重用性,减少代码冗余。
- 多态:多态是指允许派生类对象以基类的方式表现自己。这是通过虚函数实现的,虚函数在基类中声明,在派生类中重写。当通过基类指针或引用调用虚函数时,会根据对象的实际类型调用相应的函数。
至于动态多态和静态多态,它们都是多态性的表现形式,但实现方式和应用场景有所不同。
- 动态多态:通过虚函数实现的多态称为动态多态。动态多态的实现是在运行时根据对象的实际类型确定要调用的函数。这种方式增加了程序的灵活性和可扩展性,因为可以在运行时根据需要选择合适的函数。 一个类只能有一个虚函数表。在编译时,一个类的虚函数表就确定了,这也是为什么它放在了只读数据段中。 虚函数表是在编译时确定的,属于类而不属于某个具体的实例。虚函数在代码段,仅有一份。
- 静态多态:通过模板实现的多态称为静态多态(例如 奇异递归模板 CRTP ,一种模板元编程技术,子类类型作为模板参数传入父类,用于在静态多态的情况下实现类似于虚函数的行为,而避免了虚函数表的开销。它通过模板的继承和静态多态性来实现动态多态性的效果。)。静态多态的实现是在编译时根据类型参数确定要使用的函数或类。这种方式可以提高代码的可重用性和可维护性,因为可以在编译时检查类型参数是否匹配,避免了运行时错误。
3.多继承的问题,模版特化和偏特化。
多继承是C++中的一个特性,它允许一个类从多个基类继承属性和行为。然而,多继承也带来了一些问题,其中最著名的是钻石问题(Diamond Problem)。
钻石问题发生在两个基类都继承自一个共同的基类,并且派生类同时继承这两个基类时。在这种情况下,如果两个基类对派生类有不同的成员函数实现,那么在派生类中就会有两个不同的函数实现可供选择,导致二义性。
为了解决钻石问题,C++提供了两种特化方式:模板特化和偏特化。
- 模板特化:模板特化是一种通用的特化方式,它针对特定的类型进行特化。在模板特化中,可以为特定的类型定义一个新的函数实现,该实现将覆盖在基类中的函数实现。这样可以确保在派生类中只使用特化后的函数实现,避免了二义性。例如,假设有两个基类Base1和Base2都继承自一个共同的基类Base,并且派生类Derived同时继承了Base1和Base2。如果Base1和Base2都定义了一个名为foo的成员函数,那么在Derived中就会有两个不同的foo函数可供选择。为了解决这个问题,可以定义一个模板特化,为Derived类型提供一个新的foo函数实现。这样,在Derived中调用foo函数时,将只使用特化后的函数实现,避免了二义性。
- 偏特化:偏特化是一种更具体的特化方式,它只针对特定的类进行特化。在偏特化中,可以为特定的类定义一个新的函数实现,该实现将覆盖在该类及其所有派生类中的函数实现。这样可以确保在派生类中只使用偏特化后的函数实现,避免了二义性。例如,假设有两个基类Base1和Base2都继承自一个共同的基类Base,并且派生类Derived1和Derived2都继承了Base1和Base2。如果Base1和Base2都定义了一个名为foo的成员函数,那么在Derived1和Derived2中就会有两个不同的foo函数可供选择。为了解决这个问题,可以定义一个偏特化,为Derived1和Derived2类型提供一个新的foo函数实现。这样,在Derived1和Derived2中调用foo函数时,将只使用偏特化后的函数实现,避免了二义性。
4.说一下线程和进程的区别,线程之间共享内容,进程和线程通信。
线程和进程的区别:进程可以类比为一个餐厅,而线程就是在餐厅里面工作的员工
线程之间共享内容:
进程和线程通信:
5.静态库和动态库的原理,符号表,单例模式。
静态库和动态库的原理:
符号表:
单例模式:
6.快速排序,归并排序,堆排序时间复杂度一样,结合CPU的缓存访问来看,哪个效率最高?
快速排序、归并排序和堆排序的时间复杂度在理论上的平均情况或最坏情况下是相同的,都是O(n log n)。但是,实际效率会受到许多因素的影响,其中之一就是CPU的缓存访问模式。
在现代计算机架构中,CPU的缓存是一个重要的性能因素。由于内存访问速度远远慢于CPU的处理速度,因此CPU通常会使用多级缓存来存储最近访问的数据。当数据在缓存中时,访问速度会非常快,这称为缓存命中。如果数据不在缓存中,则需要从主内存中获取,这称为缓存未命中,并且会导致显著的延迟。
考虑到这一点,以下是这三种排序算法在CPU缓存方面的性能分析:
- 快速排序 :快速排序通常具有优秀的缓存局部性。这是因为它采用分而治之的策略,将数据划分为较小的子数组,并在递归过程中处理这些子数组。这些子数组通常能够很好地适应缓存的大小,从而减少缓存未命中的次数。
- 归并排序 :归并排序在合并步骤中可能会表现出较差的缓存性能。当合并两个已排序的子数组时,通常需要不断地在两个数组之间来回切换,这可能导致频繁的缓存未命中。然而,归并排序在处理链表或外部排序(数据不能完全加载到内存中)时可能是一个更好的选择。
- 堆排序 :堆排序在构建和调整堆的过程中可能会表现出较差的缓存局部性。因为它需要不断地在堆的顶部和底部之间移动数据,这可能导致非连续的内存访问和缓存未命中。
从CPU缓存的角度来看,快速排序通常具有更好的性能。然而,实际性能还会受到其他因素的影响,如数据的分布、输入规模、硬件特性等。
7.代码和文件较多时,如何定位内存错误的问题?
- 使用调试工具 :大多数现代编程语言都有内置的调试工具或调试器,可以帮助你定位和解决内存错误。例如,如果你使用的是C++,你可以使用GDB或Visual Studio的调试器。如果你使用的是Python,你可以使用pdb或PyCharm的调试器。
- 代码审查 :仔细审查你的代码,查找可能导致内存泄漏或错误的常见问题。例如,检查是否正确地释放了所有的资源,是否正确地关闭了所有的文件和网络连接,以及是否正确地处理了所有的异常。
- 使用内存分析工具 :内存分析工具可以帮助你查看程序运行时的内存使用情况。例如,如果你使用的是C++,你可以使用Valgrind、Massif以及ASAN工具。如果你使用的是Python,你可以使用memory_profiler工具。
- 代码分解 :将复杂的代码分解成更小的、更易于管理的部分。这样可以帮助你更容易地找到问题所在。
- 简化问题 :尝试简化你的代码,移除可能导致问题的部分。这样可以帮助你更快地找到问题所在。
- 阅读错误消息 :当程序崩溃或出现错误时,仔细阅读错误消息。错误消息通常会提供有关问题的详细信息,包括错误发生的文件和行号。
- 搜索相关问题 :在搜索引擎中搜索你的错误消息,看看是否有其他人遇到过类似的问题,并找到了解决方案。
- 寻求帮助 :如果你无法解决你的问题,可以向你的同事、朋友或在线社区寻求帮助。他们可能能够提供新的观点或建议。
手撕算法题
1.CUDA Reduction或者向量相乘等可以转化为Reduction的Kernel。
Reduction操作通常用于将一个数据集中的元素进行归约操作,例如求和、最大值、最小值等。通过将Reduction操作转化为Kernel函数,可以充分利用GPU的并行处理能力,提高计算效率。
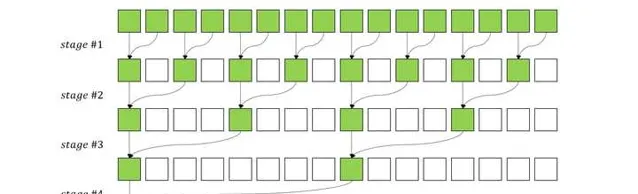
template
<
typename
T
,
int
blockSize
>
__global__
void
reduce_kernel_1
(
const
T
*
data
,
const
size_t
n
,
T
*
result
)
{
__shared__
T
sdata
[
blockSize
];
// 共享内存中声明一个大小为 blockSize 的数组 sdata。
//获得当前 thread 在 block 中的索引 tid,以及当前需要处理元素在 data 中的全局索引 globalId。
//再将数据从全局内存载入共享内存,如果 globalId 超过了数组大小,则将对应位置的元素设置为 0
int
tid
=
threadIdx
.
x
;
int
globalId
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
sdata
[
tid
]
=
globalId
>=
n
?
0
:
data
[
globalId
];
__syncthreads
();
//同步当前 block 中的所有 thread,直到所有数据拷贝完成。
//在每个 stage 中,只有能被 2 * s 整除的 thread 才会参与计算,比如,
//当 s = 1 时,只有 tid = 0, 2, 4, 6, ... 的 thread 参与计算,
//当 s = 2 时,只有 tid = 0, 4, 8, 12, ... 的 thread 参与计算,以此类推。
for
(
int
s
=
1
;
s
<
blockSize
;
s
*=
2
)
{
// 参与计算的两个元素位置为 tid 和 tid + s,计算结果被赋予 tid 所在位置。
if
(
tid
%
(
2
*
s
)
==
0
)
{
sdata
[
tid
]
+=
sdata
[
tid
+
s
];
}
__syncthreads
();
//在两次 stage 之间,需要调用 __syncthreads() 同步方法确保当前 stage 的所有元素完成计算。
}
//由于每个 stage 之后,s 都会翻倍,因此总的 stage 数量为 log2(blockSize)
//最终规约结果被保存在了 sdata[0],因此只需要 thread #0 将 sdata[0] 的数据加到 result 的第一个位置即可,
//这里使用 atomicAdd 确保多个 block 不会发生冲突。
if
(
tid
==
0
)
{
atomicAdd
(
&
result
[
0
],
sdata
[
0
]);
}
}
2.CUDA实现数组排序算法(双调排序)
当序列的前半段和后半段都是单调的时候,或者可以通过循环移位使前半段和后半段都是单调的时候,该序列就称作双调序列.
归并实现
bool
compare
(
int
a
,
int
b
,
bool
descending
=
true
)
{
return
(
a
<
b
&&
descending
)
||
(
a
>
b
&&
!
descending
);
}
void
mergeSort
(
int
*
a
,
int
n
,
bool
descending
=
true
)
{
int
stride
=
n
>>
1
;
int
t
=
0
;
for
(
int
i
=
0
,
j
=
stride
;
i
<
stride
;
i
++
,
j
++
)
{
if
(
compare
(
a
[
i
],
a
[
j
],
descending
))
// 两半对应元素组个比较交换
{
t
=
a
[
j
];
a
[
j
]
=
a
[
i
];
a
[
i
]
=
t
;
}
}
if
(
stride
>=
2
)
{
mergeSort
(
a
,
stride
,
descending
);
// 前半段
mergeSort
(
a
+
stride
,
stride
,
descending
);
// 后半段
}
}
void
hBitonicSortRecursive
(
int
*
a
,
int
n
,
bool
descending
)
{
int
stride
=
2
;
int
inter_step
=
1
;
while
(
stride
<=
n
)
{
inter_step
=
(
stride
<<
1
);
// Order
for
(
int
i
=
0
;
i
<
n
;
i
+=
inter_step
)
{
mergeSort
(
a
+
i
,
stride
,
descending
);
}
// Reverse order
for
(
int
i
=
stride
;
i
<
n
;
i
+=
inter_step
)
{
mergeSort
(
a
+
i
,
stride
,
!
descending
);
}
stride
=
inter_step
;
}
循环实现
void
hBitonicSort
(
int
*
a
,
int
n
,
bool
descending
)
{
int
t
=
0
;
int
half_stride
=
1
,
hs
=
1
,
s
=
2
;
int
hn
=
n
>>
1
;
for
(
int
stride
=
2
;
stride
<=
n
;
stride
<<=
1
)
{
s
=
stride
;
while
(
s
>=
2
)
{
hs
=
s
>>
1
;
for
(
int
i
=
0
;
i
<
hn
;
i
++
)
{
bool
orange
=
(
i
/
half_stride
)
%
2
==
0
;
int
j
=
(
i
/
hs
)
*
s
+
(
i
%
hs
);
int
k
=
j
+
hs
;
//printf("Stride: %d, s: %d, i: %d, j: %d, k: %d\n", stride, s, i, j, k);
if
((
descending
&&
((
orange
&&
a
[
j
]
<
a
[
k
])
||
(
!
orange
&&
a
[
j
]
>
a
[
k
])))
||
(
!
descending
&&
((
orange
&&
a
[
j
]
>
a
[
k
])
||
(
!
orange
&&
a
[
j
]
<
a
[
k
]))))
{
t
=
a
[
k
];
a
[
k
]
=
a
[
j
];
a
[
j
]
=
t
;
}
}
s
=
hs
;
}
half_stride
=
stride
;
}
}
cuda核实现
__global__
void
gBitonicSort
(
int
*
a
,
int
n_p
,
bool
descending
)
{
unsigned
int
tid
=
threadIdx
.
x
;
int
stride_p
,
half_stride_p
,
s_p
,
hs_p
,
hs
,
i
,
j
,
k
,
t
,
hn
;
bool
orange
;
hn
=
1
<<
(
n_p
-
1
);
half_stride_p
=
0
;
for
(
stride_p
=
1
;
stride_p
<=
n_p
;
stride_p
++
)
{
s_p
=
stride_p
;
while
(
s_p
>=
1
)
{
hs_p
=
s_p
-
1
;
hs
=
1
<<
hs_p
;
for
(
i
=
tid
;
i
<
hn
;
i
+=
blockDim
.
x
)
{
orange
=
(
i
>>
half_stride_p
)
%
2
==
0
;
j
=
((
i
>>
hs_p
)
<<
s_p
)
+
(
i
%
hs
);
k
=
j
+
hs
;
if
((
descending
&&
((
orange
&&
a
[
j
]
<
a
[
k
])
||
(
!
orange
&&
a
[
j
]
>
a
[
k
])))
||
(
!
descending
&&
((
orange
&&
a
[
j
]
>
a
[
k
])
||
(
!
orange
&&
a
[
j
]
<
a
[
k
]))))
{
t
=
a
[
k
];
a
[
k
]
=
a
[
j
];
a
[
j
]
=
t
;
}
}
__syncthreads
();
s_p
=
hs_p
;
}
half_stride_p
++
;
}
}
3.CUDA不考虑共享内存,只使用全局内存来做向量矩阵乘法,向量是行主序,矩阵乘向量和向量乘矩阵哪种访存和计算模式更好?说一说哪种用到了归约?
4.有n个线程和n个元素,在logn时间内对n个元素进行排序。
5.leetcode常见面试百题和魔改题。
TODO
-
两数之和(简单)
-
合并两个有序数组(简单)
-
移动零(简单)
-
斐波那契数(简单)
-
两数之积(简单)
-
最长回文子串(简单)
-
三数之和(简单)
-
最长递增子序列(简单)










