12月10日更新:
修改了部份往期更新的內容
<2020>
12月9日更新:
刪去了結尾的部份個人觀點
7月11日重要更新:
作者開源了作品的存檔,並制作了一個數碼電路的教學存檔,一並放到了github上,有興趣者可以自取。
5月23日更新:
作者有話說,補在結尾。
5月8日更新:
(已刪除,原文為舊存檔的獲取方式,現已更新存檔和連結)
5月7日二更:
上傳了第二期工程影片。
5月7日更新:
發現影片不完整,現已補全,因影片時長原因,故分為兩段上傳。
5月5日更新:
本文已獲得作者授權轉載!
以下部份內容經過改編和最佳化,全文重新排版,以作者視角展示全部內容
文章摘自 @季文瀚 ——【基於Minecraft實作的電腦工程】
先獻上影片:
 基於MC實作的電腦工程_一期(1)
https://www.zhihu.com/video/1108885362205872128
基於MC實作的電腦工程_一期(1)
https://www.zhihu.com/video/1108885362205872128
 基於MC實作的電腦工程_一期(2)
https://www.zhihu.com/video/1108885440584773632
基於MC實作的電腦工程_一期(2)
https://www.zhihu.com/video/1108885440584773632
 基於MC實作的電腦工程_二期
https://www.zhihu.com/video/1109220128654315520
基於MC實作的電腦工程_二期
https://www.zhihu.com/video/1109220128654315520
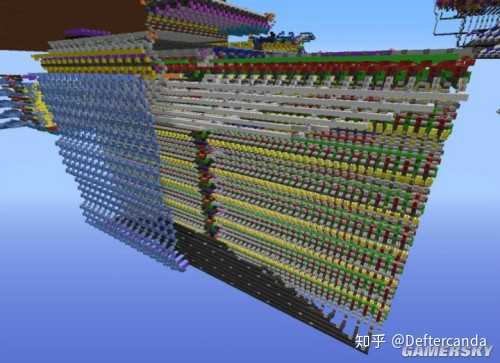
(下文圖片因來源問題不太清楚)
本工程基於一個叫Minecraft的遊戲,我使用的版本是1.4.7。之所以使用一個遊戲作為平台,是因為這個遊戲可以做到即時執行超大規模集成電路模型(大於10000個邏輯門)並且提供壯觀的視覺化效果(三維數碼電路)。
半年前我剛接觸這個遊戲的時候,想做一個簡單的小算盤。國外玩家兩年前已經有人做到了,基於整數ALU和直連總線的機器。我開始規劃做一個16bit的小算盤,輸入輸出路線一樣是直連的,也就是說這個小算盤完全是 專用的芯片 ,連微控制器的等級都不到。後來我發現這個遊戲可以實作更加復雜的東西。原因很簡單,遊戲只提供了「或」「非」邏輯電路,但理論上「或」「非」門可以表達一切邏輯。同時遊戲提供的基於活塞機械的斷路,繼電器的延時時序特性以及繼電器的鎖存特性會讓很多高級觸發器成為可能。換句話說,FPGA能實作的東西這個遊戲基本都能實作,區別在於這個遊戲提供的是一個純粹數學模型化的訊號系統,元器件是簡化的模型而不是現實中根據半導體材料設計的具有一定特性的電子元件,線上路連線的拓撲結構上也和現實中的電路不同。
在造小算盤到一半的時候我打算改微控制器,也就是具有「 圖靈完備性 」的簡單電腦,他可以執行一切電腦程式。我規劃了指令集架構,儲存器架構和指令發射方式等。隨著除法器,可讀寫儲存器,緩沖佇列等重要電路結構的設計成功,我開始有了一個大膽的設想,嘗試實作一個具有流水線結構,總線結構,溢位中斷,堆疊,標誌位寄存器,基本的分支預測和亂序執行等現代高級電腦技術的16bit RISC CPU以及一個附屬的包含超越函數的單精度浮點處理器32bit FPU(目前只規劃作為小算盤使用)。
工程進展順利,只是因為工程量巨大進度較慢。我已經將16bit整數小算盤改成了完全時序邏輯電路控制,並且有溢位判斷的小算盤。這在全世界Minecraft紅石電路玩家裏應該是首次。這個小算盤作為片外系統借用CPU的ALU部份進行運算並經過總線傳輸數據。目前CPU的ALU,主儲存器,和寄存器等EU部份已經完工,內部環狀總線已經完工,CU部份,也就是最繁瑣的部份正在建設中。而FPU部份已經完成了加法器,乘法器,三角函數運算單元,開方運算單元。至此,整個工程大約有10萬門以上的電路。
目前不可逾越的困難是遊戲的基準單位延時t是0.1秒,載入地圖最大範圍是長寬1024m,高256m的範圍,這就限制了電腦的運算速度以及造出來的硬件規模。特別是儲存器,我的片上程式儲存器只有1kb,這對於現實中的儲存器容量而言太小了。所以想利用這有限的空間做一個組譯編譯器,簡易的作業系統實在是太困難。
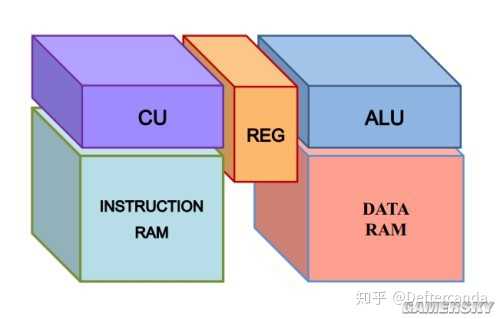
對於工程的介紹我分為6部份: 訊號系統,硬件單元和硬件演算法,儲存器架構和流水線,指令集架構,總線和時鐘,圖形顯示原理 。我盡量用非專業的語言來介紹,不可避免會用一些術語。
本工程需要的專業知識基本就是微機原理,數碼電路,少許編譯原理和電腦圖形學。
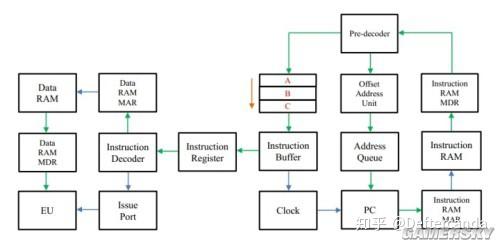
此處先貼上一張cpu架構圖。
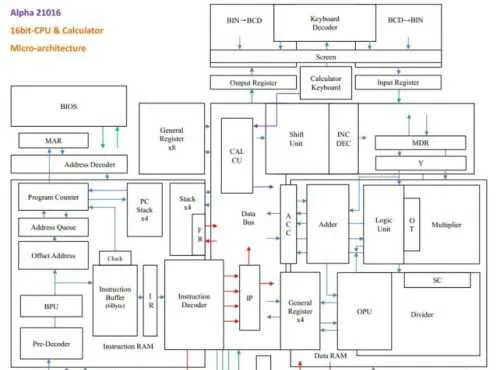

其中每一個方框都代表一個或若幹個硬件單元,小一點的大約一兩百個門電路,大的有幾千個門電路。架構圖基本是按照實際距離做的,在工程上方俯視看到的結構和架構圖可以一一對應。下面的俯檢視對應架構圖的右半部份(Data Bus以及其圍住的右下部份。

ps:目前決定把亂序執行模組取消。
一、訊號系統
構成超大規模訊號系統的邏輯等級基本如下:
基本訊號元件→基本邏輯門→復雜邏輯門→簡單功能結構:組合電路,時序電路,觸發器→復合功能結構→硬件功能單元→硬件功能模組→電腦
舉例如:
或門,非門→與門,異或門→全加器,訊號長度轉換器,多型選擇器,儲存器單元,譯碼器單元,求補碼單元,移位器單元→可讀寫儲存器,譯碼器,加法器,移位器,時鐘發生器→加減法器,乘法器,除法器,可讀寫儲存器陣列,寄存器,程式計數器→總線,ALU,CU→電腦
訊號元件:
先從邏輯底層開始介紹,最主要的原件只有四個,如下圖:

從左到右依次為:1.繼電器/二極管/鎖存器/延時器(同時兼有四個功能)2.紅石火把(高電平訊號源)3.紅石粉(紅石導線)4.黏性活塞(可推拉的開/通路元件)。
本工程占地大約600x600x200單位長度。
(原文這裏詳細介紹了這四個元件的特性,這裏就不說了,紅石老手都懂,不了解請自行搜尋)
視覺訊號與顯視器:
遊戲本身沒有顯示器這種東西,但是玩家可以透過各種方式實作視覺上的資訊傳遞。

第一種是紅石燈。紅石燈被充能時會亮,不充能時不亮,這兩種狀態即可組成圖形,和電腦的bitmap一致。
第二種是陰影成像。即遊戲中白天光照條件下淺顏色的方塊凹陷處的陰影會和周圍的方塊形成反差,也構成了兩態訊號的影像。而實作方塊凹陷的方式就是黏性活塞。
向上傳輸和BUD:
向上傳輸是遊戲提供的一種訊號單向向上傳輸的方式,可以用兩種方塊實作。如圖,左邊的螢石,本身有自然發光的作用,同時可以用圖中方式向上疊放。正常的方塊這樣疊放肯定會擋住訊號,所以正常方塊向上向下傳輸必須螺旋盤疊,這樣會占據更大的空間,於是遊戲提供了單向向上傳輸節約空間。但是可惜遊戲沒有提供單向向下傳輸(至少我使用的1.4.7版本沒有提供),可以看到如圖中左邊的螢石訊號通路輸入端在上方,下方方塊的紅石導線沒有亮,而右邊的螢石通路輸入端在下方,上方方塊的紅石導線亮了。另一種單向向上傳輸的方塊是「半磚」,即只占一般空間的磚頭,如下左圖中右邊灰色的磚塊。因為只有一半高度,所以這樣盤疊不會擋住各自導線的連線。半磚同樣只實作單向向上傳輸。(此處的「螢石燈」和「半磚」我認為理解為透明方塊更好。透明方塊:對所有不具有完整實心方塊普遍特性的方塊的統稱。鑒別方法:充能法,卡頭法,箱子法等。)
BUD是遊戲中一類類似BUG的訊號特性。但是又不能叫做BUG,因為這些特性也可以看做是訊號系統的組成部份。由於遊戲編程中對於方塊更新的檢測機制存在一定局限性,所以一些方塊會被非正常啟用。有一次我偵錯路線出現了很奇怪的錯誤,排查了半天才發現是BUD問題。有些時候也可以利用BUD的特性做成特定功能的路線。

實際上遊戲中還是有BUG的,有一次我排查了一個多小時竟然發現某個錯誤的原因是這樣的:兩個相隔100多米毫無功能關聯的繼電器,當一個置於2檔的時候,另一個會工作不正常。這屬於遊戲難免會有的BUG,但是有時候一個小BUG會導致整個電腦癱瘓。
邏輯門
遊戲提供的二態訊號正好對應於二進制0和1,也對應於數碼電路裏用高低電平表示的訊號。所以二態訊號系統無論其實作的載體和方式如何,規律必定都是一樣的。所以可以用相同的組合和演算法構造更復雜的結構。
有了四種訊號元件如何進一步做成邏輯門呢?
非門 利用紅石火把被充能方塊熄滅的特性,輸出相反的訊號。
或門 更簡單,「 或 」在邏輯上就是只要任意一個輸入端(不僅僅是一共2個輸入端的情況)輸入訊號,輸出端就一定輸出訊號。如下左,兩個橙色的方塊為輸入端,只要有一個放上火把,綠色的輸出端就會輸出訊號。下右為簡單的組合邏輯,4個輸入端組成的 或門 加上輸出端的 非門 組成的 或非門 。這種電路一般用於「0判斷」,即輸入端全為0,輸出就有訊號,只要有一個輸入是1,輸出端的紅石火把就會滅。

可以證明只用 或門 和 非門 就能實作一切邏輯,遊戲的設計者也只設計了這兩種能直接實作的邏輯門, 這一點和現實的晶體管電路也很符合 。透過在空間上對或門和非門的組合排布就能實作更加復雜的邏輯門。

與非門如左,紫色為輸入端,橙色為輸出端,可以看出輸入端連著兩個紅石火把是兩個非門,火把中間通著導線是一個或門,真值表我就不寫了,簡單計算即可知這是一個與非門。常見的與非門套用也就是RS觸發器了,比如右邊這個基本RS觸發器,低電平有效,紫色輸入,橙色輸出,RSQQ非就隨便怎麽分配了,此時圖中輸入端均有效,輸出端無效,當輸入端從01或10置為00(高電平)時會鎖存。而當輸入端同時從00變為11時遊戲的方塊重新整理機制會預設選擇其中一個輸出端輸出1,另一個輸出端輸出0,當然本身就不用考慮會使用這種情況。所以用 與非門 構造的RS觸發器和現實中基本一致。
與門 比 與非門 復雜一點,只要在 與非門 基礎上加個 非門 的紅石火把就可以了。如下圖,下左為標準的 與門 ,兩個紅色的輸入端,紫色為輸出端,可以看出是3個 非門 和一個 或門 組成的邏輯電路。可能讀者仍然不便理解,我就將其轉化為框圖,如下中圖。簡單的計算可得只有當兩個輸入端同時輸入1時,輸出端為1,和與邏輯相同。下右兩個同樣為與門,只不過路線排布稍微變化即可變為空間構造不同的與門,可以用於各種不同的布線情況。

活塞斷路 其實也是 與 邏輯。廣義上的「 與 」可以看做同時滿足各自條件的若幹個輸入端才能使輸出端輸出特定訊號。比如下左上面的紫色輸入端輸入0,下面的紫色輸入端輸入1才能使綠色輸出端輸出1,而下右活塞原本擋住橙色路線,當活塞被啟用將藍色方塊推出時,會使凹下的橙色方塊路線與兩邊聯通,這時右邊的紫色輸入1,左邊的綠色才會輸出1。即這是輸入端必須全為1的標準 與門 。

之後的復雜訊號結構的介紹我都盡量簡略,如果真要從頭到尾講清楚,要寫一本書。其中涉及到的專業知識太多了,很難讓所有讀者都能理解,見諒。關於數碼電路和微機原理的各種基礎知識介紹我都從略。
異或門 是數碼電路裏非常重要的一類復雜邏輯門,是構造全加器以及一切具有ALU運算器結構單元的基礎。比較簡單的 異或門 設計如下圖左右兩種,除了紅石導線外,左邊一種用到了活塞,火把和中繼器,右邊一種只用了火把。 這兩種都是國外玩家設計的,是目前設計出來的體積最小的異或門。我一開始自己設計出的異或門比這兩種體積大一點。而基礎邏輯門的體積對電腦建設至關重要,基礎邏輯門稍微大一點整體結構就將超過地圖載入範圍。我的工程在設計上如果沒有這些高手玩家在基礎結構上的設計,是不可能實作的,因為用minecraft實作即時運算超大規模訊號系統最重要的難題就是體積問題。
這兩種異或門右邊一種較好,因為遊戲中的火把可以在1秒鐘內承受8次訊號變化才會熄滅,而活塞似乎承受不了這麽多次的變化,容易在快速的訊號變化中出現差錯。 所以我的電腦中基本都是采用右邊一種異或門。 兩個橙色方塊是 輸入端 ,紫色方塊是 輸出端 。

其他所有邏輯門都可以透過或,非門的組合得到,就不再詳述。
簡單功能結構
利用邏輯門的組合就可以設計適用於各種功能的訊號結構。
全加器:全加器可以看做是電腦最核心的部件,之前的一個異或門相當於一個半加器,兩個半加器可以組合成一個全加器。由第一種異或門組成的全加器 如下左,下右是4個相同的全加器級聯。

但是這種基於活塞的全加器不穩定,所以較為好的設計是如下圖的基於第二種異或門設計的全加器。兩個紅色為輸入端,藍色為進位端,紫色為本位輸出端。下右為兩個不同顏色的全加器級聯。

其他的組合電路,時序電路和觸發器就舉幾個例子。
前一部份已經介紹過RS觸發器,實際上並不常用。常用的是一些邊沿觸發的時序電路。下左圖為活塞開路的兩種最基本的套用,兩個同樣的藍色開路路線,作為輸入端的紅石火把左邊在下,右邊在上。左邊的藍色路線因為開路的節點(凹下去的地方)比開路輸入端的節點更靠近火把,而4檔繼電器的延遲為0.4秒,活塞的延遲為0.1秒,所以第0.5秒後活塞會伸出使路線開路,這時輸入端訊號就傳不到活塞了。而繼電器裏可以存下0.4秒的訊號,所以再過0.5秒活塞會收回,路線又會通。然後就會這樣迴圈的「開路-通路-開路-通路」下去,每1秒是一個迴圈。實際的效果就是每1秒鐘內可以輸出一個0.5秒的訊號。右邊那條路線輸入端通往活塞的節點在開路節點的前面,所以不受開路影響,只要輸入端有持久訊號就會在0.1秒後永久開路,使得下方輸出0.1秒的瞬間訊號。必須等待輸入端變為低電平活塞才會收回,這等價於一個上沿訊號。
下右圖是一個T觸發器,左邊紫色為輸入端,接一個上沿訊號發生器輸出0.2秒短訊號,右上綠色方塊是輸出端,T觸發器儲存一個訊號,高電平短訊號使觸發器工作,效果是使原有訊號翻轉並儲存輸出。

下左為短訊號轉1秒訊號器,實際上可以做出任意長度訊號之間的轉換,比如0.1秒轉4秒,5秒轉0.2秒等等。下右為3秒短訊號輪換器,即第0秒輸出短訊號到A端,第3秒輸出短訊號到B端,第6秒輸出到A端……

移位觸發器,也是很常用的一種結構,可以做成單向或雙向。

下左為時脈儲存器,即長度mt的訊號在長度nt為一個周期的環路中(n>m)作迴圈傳遞。時脈儲存器和訊號發生器組合可以變成電腦的時鐘訊號發生器。下右為短訊號阻斷器(名字值得吐槽,我也不知道該取什麽名字= =),可以濾去0.6秒以下的短訊號。

下左藍色部份為4路選擇觸發器,發射訊號選擇其中一路並儲存該狀態,之後發射訊號選擇其他某一路會清除之前的選擇並存進新的選擇。下右黑色部份為總線訊號清空單元,可以周期性的阻斷總線訊號通路。

儲存器:
見繼電器鎖存功能的介紹。鎖存單元8的並列,然後用同一根線控制鎖存,再用一根線控制儲存訊號的開閉,就組成了一個1byte的儲存器。大量儲存器組成3D陣列。相鄰奇偶編號儲存器加上byte/word切換控制模組。最後再用統一的譯碼模組編碼,就成了完整地儲存器。
復合功能結構
由簡單功能結構可以進一步組成復合功能結構,從而完整地實作某一功能。比如全加器級聯變成加法器;異或門和加法器串聯,然後級聯,再加上符號訊號端變成求補器等等。





硬件功能單元
復合功能單元能執行某一個完整的邏輯功能,比如加法器使兩個補碼相加,求補器使某個原碼求補碼。而硬件上加減法器的完整功能一般指從求補碼到加減法到求原碼返回寄存器或總線的完整過程。


硬件功能模組
功能單元足夠多的時候就會形成模組。比如加減法器,乘法器,除法器,移位器,布爾邏輯單元等等組成ALU;指令緩沖佇列,指令譯碼器,指令發射端等等組成CU;地址譯碼器,儲存器陣列,寄存器等等組成完整的具有等級結構的儲存器體系。功能單元的位置,朝向等都會大大影響布線的困難程度和延時的長短,這對整個電腦的執行效率有至關重要的影響。所以對功能模組的放置需要花很多時間計算,排列,布置。我花了很多時間不斷修改,調整。


二、硬件單元及硬件演算法
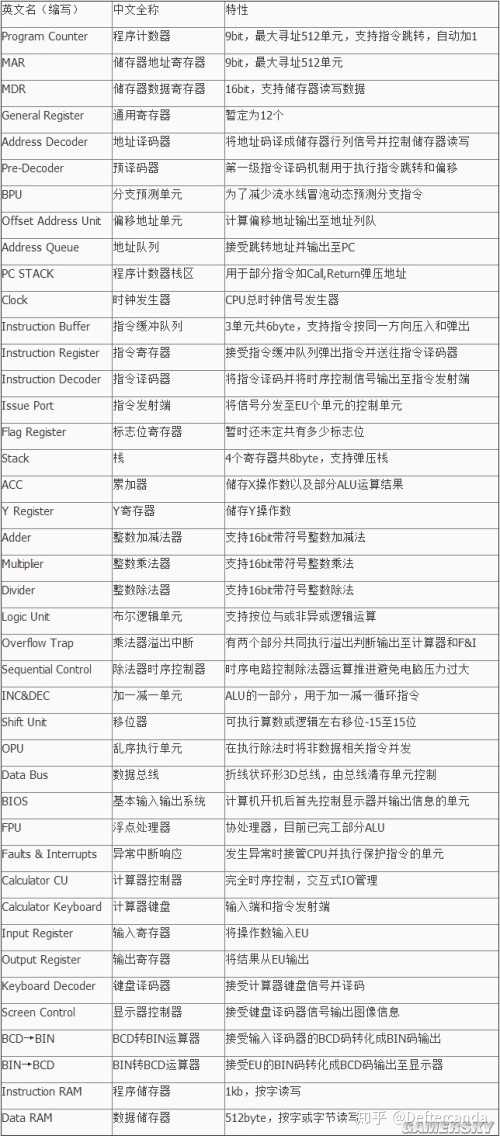
硬件單元列表及特性
硬件演算法
演算法對硬件設計是靈魂,好的演算法設計出來的硬件單元可能要比不好的設計節省10倍的運算時間,10倍的空間,10倍的建造精力。總之演算法決定ALU的一切。
加減法就是常見的補碼加法演算法,乘法就是級聯序列乘法,都沒什麽特別的。重點介紹後面幾個。
BCD/BIN轉換演算法
輸入端BCD轉BIN演算法(這個自己想出來的)
想法很直接,BCD十進制碼轉BIN二進制碼按照常規的數學運算就是十進制每一位乘上10的各自位數-1次方。比如123=1x10^2+2x10^1+3。這個反映到二進制演算法上就是將BCD每一位數的四個訊號乘以10的n次方的二進制值,n為該位數-1,最後所有位再加起來。重要的是這種演算法在硬件上實作很簡易,所以我也沒找其他演算法,就直接用了。

輸出端BIN轉BCD演算法
這個用的是通用的演算法,流程如下:
某二進制數一直做左移操作,每一次左移後從第一次移位進入的那個位向左每4個位切斷成一組(作為BCD數),然後判斷改組是否大於等於5,如果大於等於5則該組+3處理,小於5不用處理。所有組處理完後繼續移位,一直移到末尾進入第一次移位的那個位。文字介紹很別扭,可以結合下面的圖看。
借用mc論壇上的舉例介紹:
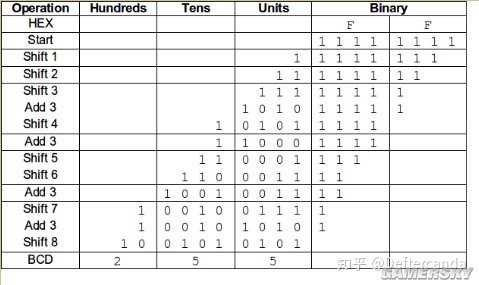
把Units,Tens,Hundreds和他們所處的那一列統稱為1組,另外Binary和它所在的那一列不算一組,表格一行一行看。1組數據對應一個BCD字元,2進制數有多少位就把它往左移多少位。左邊的英文是操作,shift是移位,add是加。Units組的最右邊一位就是上文指的「第一次移位進入的那個位」。
上圖是以255為例,下面再以123為例的流程如下:
123的二進制數是0111 1011
我們先將其左移1位,得到1111 0110
目前還在binary那列裏,所以繼續移位
得到0001 1110 1100
組裏的數碼小於5,繼續移
得到0011 1101 1000
繼續移位
得到0111 1011 0000
可以看到Units組裏的數碼已經大於5了,所以把當前該組裏的數據+3處理
到1010 1011 0000
繼續移位
得到0001 0101 0110 0000
Units組裏的數碼等於5,所以再加3
得到0001 1000 0110 0000
繼續移位
得到0011 0000 1100 0000
繼續移位
得到0110 0001 1000 0000
這次是Tens裏的數據大於5了,所以+3處理
得到1001 0001 1000 0000
因為在2進制數前面補了一個0,所以變成了8位元的數據,現在還差最後一次的移位
得到0001 0010 0011 0000 0000
結束

除法演算法
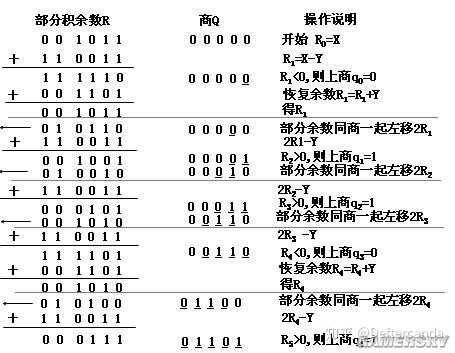
整個序列的除法器利用減法判斷符號來決定上商和恢復余數。由於除法在硬件上的運算密度比較高,序列除法器如果讓它完全不受時序控制直接序列推進運算會讓電腦負擔太大的運算量導致卡頓。這個的主要原因是訊號在時間上的重疊,初始訊號一開始就傳送到了最後,每一行的部份積余數一算完,後面所有的訊號都要全部改變一次,會導致幾千個紅石火把每一秒經歷若幹次變化(還好總數比8小不至於崩潰)。所以我又設計了一個控制運算推進的時序電路,最終卡頓的情況比原來好了許多。
設計出來的硬件單元前文已給出,再貼兩張細節。


浮點加減法演算法
這個也是用的通用演算法。
按照下面幾個步驟來:
浮點數由階碼和尾數構成,可以看做是二進制的科學計數法。階碼就相當於科學計數法的那個冪次方數,尾數就相當於有效數碼的具體數值。比如0.11x2^3,其中0.11是尾數,3是階數。IEEE754標準的浮點數規格如下

要不要用偏正值其實無所謂,只要知道單精度浮點數(single precision floating point)的位數是32bit,指數位數=8,尾數位數為=23,還有一位符號位。其中指數位數中有一位是指數的符號位即表示其範圍為-127到127,不算這個符號位就是指偏正值0-255,其實含義是一樣的。而單獨的那個符號位是給整個浮點數用的。
設有兩個浮點數x和y,它們分別為
x=2Ex•Mx
y=2Ey•My
其中Ex和Ey分別為數x和y的階碼,Mx和My為數x和y的尾數。
(1) 比較階碼大小並完成對階
兩浮點數進行加減,首先要看兩數的階碼是否相同,即小數點位置是否對齊。若二數階碼相同,表示小數點是對齊的,就可以進行尾數的加減運算。反之,若二數階碼不同,表示小數點位置沒有對齊,此時必須使二數階碼相同,這個過程叫作對階。要對階,首先應求出兩數階碼Ex和Ey之差,即△E = Ex-Ey。若△E=0,表示兩數階碼相等,即Ex=Ey;若△E>0,表示Ex<Ey;若△E<0,表示Ex>Ey。當Ex≠Ey 時,要透過尾數的移動以改變Ex或Ey,使之相等。原則上,既可以透過Mx移位以改變Ex來達到Ex=Ey,也可以透過My移位以改變Ey來實作Ex=Ey。但是,由於浮點表示的數多是規格化的,尾數左移會引起最高有效位的遺失,造成很大誤差。尾數右移雖引起最低有效位的遺失,但造成誤差較小。因此,對階操作規定使尾數右移,尾數右移後階碼作相應增加,其數值保持不變。顯然,一個增加後的階碼與另一個階碼相等,增加的階碼的一定是小階。因此在對階時,總是使小階向大階看齊,即小階的尾數向右移位(相當於小數點左移)每右移一位,其階碼加1,直到兩數的階碼相等為止,右移的位數等於階差△E。
(2) 尾數求和運算
對階結束後,即可進行尾數的求和運算。不論加法運算還是減法運算,都按加法進行操作,其方法與定點加減法運算完全一樣。我這裏就照搬常用加減法器。
(3) 結果規格化
在浮點加減運算時,尾數求和的結果也可以得到01.ф…ф或10.ф…ф,即兩符號位不等,這在定點加減法運算中稱為溢位,是不允許的。但在浮點運算中,它表明尾數求和結果的絕對值大於1,向左破壞了規格化。此時將運算結果右移以實作規格化表示,稱為向右規格化。規則是:尾數右移1位,階碼加1。當尾數不是1.M時需向左規格化。
(4) 舍入處理
在對階或向右規格化時,尾數要向右移位,這樣,被右移的尾數的低位部份會被丟掉,從而造成一定誤差,因此要進行舍入處理。簡單的舍入方法有兩種:一種是"0舍1入"法,即如果右移時被丟掉數位的最高位為0則舍去,為1則將尾數的末位加"1"。另一種是"恒置一"法,即只要數位被移掉,就在尾數的末尾恒置"1"。
在IEEE754標準中,舍入處理提供了四種可選方法:
就近舍入 其實質就是通常所說的"四舍五入",這是預設的常用方法。例如,尾數超出規定的23位的多余位數碼是10010,多余位的值超過規定的最低有效位值的一半,故最低有效位應增1。若多余的5位是01111,則簡單的截尾即可。對多余的5位10000這種特殊情況:若最低有效位現為0,則截尾;若最低有效位現為1,則向上進一位使其變為 0。
朝0舍入 即朝數軸原點方向舍入,就是簡單的截尾。無論尾數是正數還是負數,截尾都使取值的絕對值比原值的絕對值小。這種方法容易導致誤差積累。
朝+∞舍入 對正數來說,只要多余位不全為0則向最低有效位進1;對負數來說則是簡單的截尾。
朝-∞舍入 處理方法正好與 朝+∞舍入情況相反。對正數來說,只要多余位不全為0則簡單截尾;對負數來說,向最低有效位進1。
本浮點加減法器符合IEEE754單精度fp32浮點標準,但由於體積問題沒有使用舍入法,所以精度有一定損失。

正余弦演算法
這個用的是經典的cordic叠代演算法中的旋轉座標演算法。公式推導如下:
將平面座標系中向量(Xi , Yi)旋轉角度θ得到新向量(Xj , Yj)
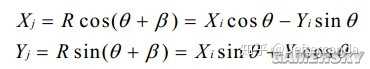
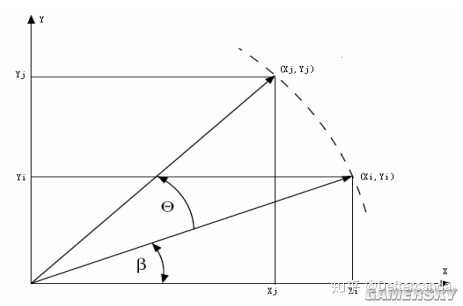
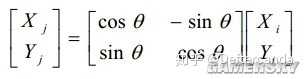
可以看出θ如果拆成許多個小θ,即θ=θ1+θ2+θ3+…+θn,那麽作n次旋轉即可得到結果。
為了方便二進制硬件運算,現構造一個θ序列:
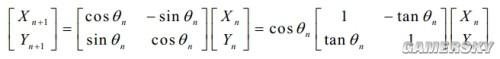
先不管cos θn,構造θn=arctan(1/2^n),並且滿足
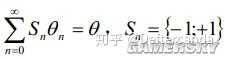
Sn表示θ的正負,也就是說構造出的這列θn前面要加正負號,以反復偏大偏小的趨勢逼近θ。每一步旋轉的角度Zn滿足如下條件
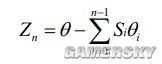
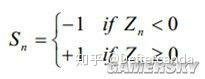
綜上得
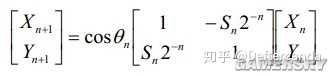
經過N次叠代後
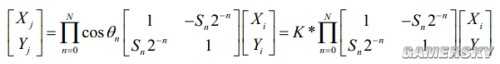
這個K就是一坨cosθn的連乘,定義為增益因子。
取無限次叠代值為
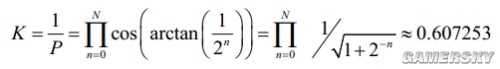
P為K的倒數。Cordic演算法有幾種模式,這裏只取旋轉模式。將上述矩陣化為數列得
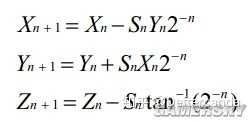
N次叠代後
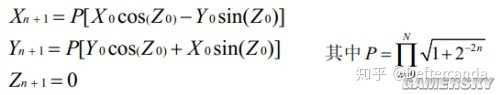
然後就是套三角函數了,取X0=K,Y0=0,Z0=α,那麽N次叠代之後
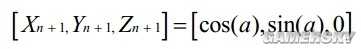
正余弦就算出來了。沒了。
用在硬件上的優勢是,該演算法從矩陣去除cos因子之後就在盡力構造簡易的二進制運算比如加減和移位。需要預先算好那個K的值精確到指定位數,還要算arctan(1/2^n),這些都要放到儲存器裏。
其中細節不說了,最後我設計出的玩意兒就下面這貨。

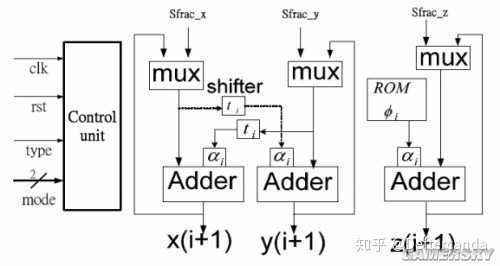
註:1.由於我懶得去用數學軟件打公式,以上數學公式的圖片均截取自一篇來自桂林電子科技大學李全,陳石平糊付佃華的論文【基於CORDIC 演算法的32 位浮點三角超越函數之正余弦函數的FPGA 實作】
2.我不打算讓三角函數運算單元加入FPU結構了,所以沒做成IEEE754標準,只給浮點小算盤用。
開方演算法
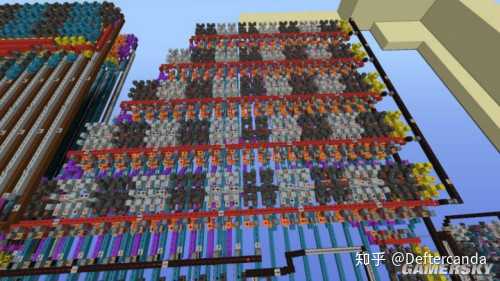
特殊函數小算盤除了三角函數外另一種運算是7位運算元開方運算,輸出4位元開方結果和4位元余數。

該演算法在硬件上實作很簡單,只需要用到加法器和移位器即可,所以在本工程中實作出來的體積不大。最終實作了一個23位開方根器,如下圖直角梯形部份。
特殊函數小算盤的執行結果顯示如下兩圖範例

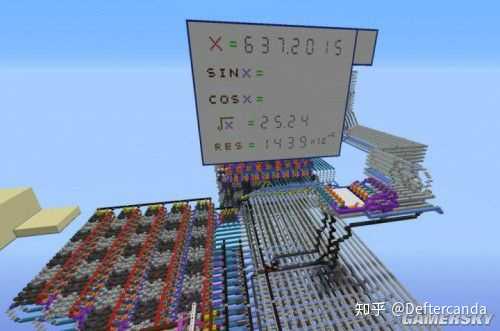
三角函數運算輸入4位元定點有效數碼的角度,輸出sin值和cos值,運算+輸出時間約為130秒輸出sin值,再過10秒輸出cos值,輸入角限制為0-83.88度之間。開方運算輸入7位有效數碼,可以選擇小數點在第三位或整數形式,輸出結果為4位元開方結果和4位元余數,運算+輸出時間約為50秒輸出開方值,再過10秒輸出余數。
三、儲存器架構和流水線
因為還沒有做完這一部份,可能還會有修改,所以就簡要的介紹一下。
現代電腦都是圍繞儲存器為中心,因為儲存器容量極其巨大,其占用的晶體管數量遠遠超過用於運算和指令分配的其他邏輯單元。
比如一顆GPU,拿GK104為例,一共30多億晶體管,片上緩存就占了芯片面積的接近三分之一。這還只是第一級的讀取機制,緩存分一二三級,後面還有主儲存器(記憶體),還有硬碟,這些容量每一級都要比上一級大了大約兩個數量級。容量大,晶體管多,電流流過的時間長,最終讀取到數據的時間必然變長。但是處理器時時刻刻都在做運算,如果第一時間不能取到需要的指令和數據,流水線就會空置。現代處理器運算速度和儲存器延遲的鴻溝越來越大,電腦核心技術基本都是圍繞儲存器開展的。為了填補這拉開的時間差所造成的瓶頸,各種流水線結構,總線結構,硬件演算法孕育而生。
流水線技術使得整個指令流程前後重疊,能最大限度利用每一個硬件單元。早期CPU流水線級數較小,現在的CPU一般都是十幾級流水線。流水線級數也不是越大越好,因為存在一些情況,比如較晚的分支預測錯誤,會導致流水線冒泡。
本工程使用Harvard結構,相對於Neumann結構。程式儲存器和數據儲存器分開放置。程式儲存器1kb,數據儲存器0.5kb。由於指令是統一的雙字節,所以程式儲存器只按字(雙字節)存取。而數據格式可以是單字節(低8位元),也可以是雙字節,所以數據儲存器可以按字或按字節存取。
寄存器方面,ALU用ACC存放X運算元和運算結果,這裏的運算結果都是需要雙運算元的那些邏輯運算指令比如加減乘除與或異或,另一個運算元由Y寄存器存取。除法的余數最終會輸出到最靠近除法器輸出端的那4個寄存器的末端一個。所以如果之後要使用余數,就要避免在轉移余數之前使用該寄存器做其他事情。另外還有8個通用寄存器供自由使用,一共可自由支配的寄存器有13個,ACC+12個通用寄存器。再算上棧區的4個單元,就一共有17個。
儲存器陣列是3D的,也就是具有長寬高三個向量。為了給一個長方體的每一個單元編碼,我采用的是先用地址碼的低4位元給個面編碼,再用地址碼的高5位給一條線編碼,一個面乘以一條線正好覆蓋了整個長方體。
通往儲存器的地址線是總線分出來的支線,數據線也是一樣的。這兩列線分別連到儲存器的3D結構裏。地址線就連到剛才說的譯碼高5位和低4位元,數據線的16個bit每一根連到每一個儲存單元的對應bit。數據線先分散後集中。
本工程因為體積和延時問題的特殊性,主程式儲存器只有1.5kb,訪存速度相對於真實的電腦快多了,所以這個並不是瓶頸,可以在相對較短的時間內取到想要的指令。所以本想借這個優勢實作指令全流水,也就是依靠復雜的分支預測機制將流水線漏洞封死。後來嘗試做了一下,發現問題還是很多,比如預譯碼,預跳轉中PC的占用沖突和布線困難,前一條跳轉指令和後一條跳轉指令的沖突,如果想要做出來,開銷過於巨大,基本上CU的體積要增加0.5倍,這對我之後的工作影響很大故棄之,改為二位動態分支預測器來執行分支預測,這樣流水線會冒氣泡,但是損失不大。為了最大限度的縮小流水線氣泡,我前後進行了相當多細微的改進。
流水線:取指→預譯碼,預執行→譯碼(→間指)→執行(→寫回)
完整的流水線,一條指令會經歷如下過程:當指令緩沖佇列的指令條數小於4條時,先載入已經處於載入端的下一地址的指令,然後發出一個訊號往PC,PC將當前儲存的地址傳送至程式儲存器MAR,然後PC+1,地址譯碼器將相應地址的指令A傳送至程式儲存器MDR的載入端,如果是跳轉指令等需要修改PC的指令則預執行指令。意思是將程式指標類指令全部放在另一個流水線分叉上執行。如果不是跳轉指令,則MDR將A指令壓入指令緩沖佇列。如果此時緩沖佇列裏有ABC三條指令按這個順序排列,那麽等待C先彈出,然後B彈出,最後輪到A彈出至IR,IR將A送往指令譯碼器,控制訊號通完各EU單元前端。等待前面的B指令執行完了 ,然後正式執行A指令。此時如果有間指周期,則將數據地址輸送至地址譯碼器,從寄存器或數據儲存器讀取數據送到相應單元。然後執行指令。執行完畢如果有寫回周期則執行寫回。一條指令執行完畢。期間在指令緩沖佇列和IR中如果前面有一條指令是條件跳轉指令並且分支預測錯誤,會使緩沖佇列和IR清存。PC發射正確的地址重新取指。
藍線是控制訊號,綠線是數據訊號,紅色字母和橙色箭頭是指令佇列的順序壓進方式。
另:本工程的所謂記憶體實際上是硬碟,因為我的程式是儲存在這裏面的,關機的時候我不會把儲存器清空。不過這個問題無關緊要。
四、指令集架構
指令格式和取指方式:
ALU Instruction Formats
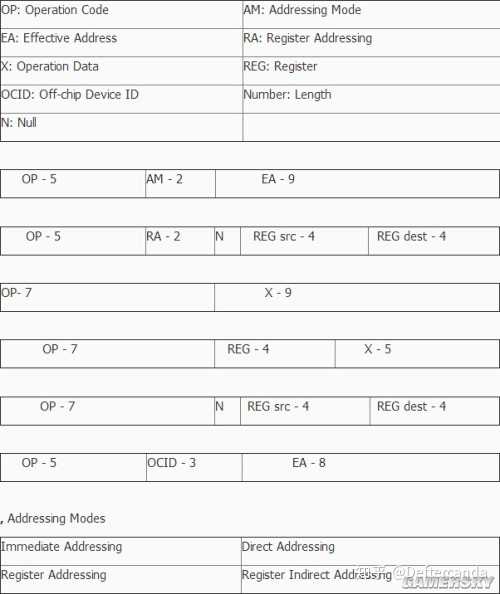
由於CU還沒做完,指令機器碼可能還有較大變動,所以是暫定表,這一部份也不多介紹。其中有一些指令是我特殊設計出來為了節約程式碼,所以助憶碼不一定規範(有些縮寫就是在瞎編)。
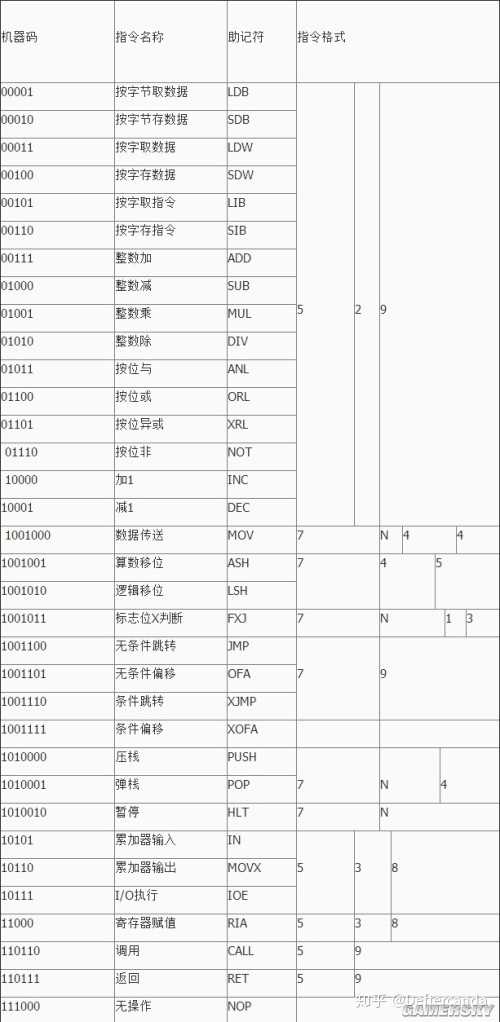
1. 數據傳送指令:MOV,PUSH,POP,RIA
MOV指令支持除了MAR,MDR,PC和棧區之外的寄存器之間的數據傳送;
PUSH和POP指令為壓棧和彈棧,原地址和目標地址均為寄存器,當棧滿時PUSH則無效,原棧區數據不變,以溢位中斷處理;
RIA指令可實作單字節的立即數寫入寄存器,設計該指令的目的是為了使寄存器賦初值等操作更靈活,節約指令周期。
2. 數據讀寫指令:LDB,SDB,LDW,SDW,LIB,SIB
LDB,SDB,LDW,SDW均為對數據儲存器的讀寫操作,讀操作均由儲存器傳輸至ACC,寫操作均由ACC至儲存器;
LIB,SIB均為對程式儲存器的讀寫操作,讀操作均由儲存器傳輸至ACC,寫操作均由ACC至儲存器;
這6種操作均支持4種尋址方式。
3.算術運算指令:ADD,SUB,MUL,DIV,INC,DEC
ADD,SUB,MUL,DIV均為取運算元於Y寄存器,然後與ACC進行算術運算,結果存於ACC。當尋址方式為寄存器尋址時,指令格式為

即該格式指令支持目標寄存器,結果由ACC存至目標寄存器;
INC和DEC指令只支持寄存器直接尋址。
4.邏輯運算指令:
ASH,LSH,AND,ORL,XRL,NOTASH和LSH指令只支持寄存器內數據移位操作,移位數值為立即數,取值範圍-15到+15;
AND,OR,XOR指令和算術運算指令同格式;
NOT,LSH指令為單運算元指令。
控制轉移類指令參考流水線架構。
關於尋址位數。因為儲存器很小,我在16bit的雙字節指令裏正好塞下了5位的基本操作碼,2位的尋址方式和9位的儲存器尋址。9位尋址對應512個程式儲存器單元共1kb,也正好對應了512個數據儲存器單元512byte,所有可用空間都填滿了。所以不能再擴充記憶體,也用不到像8086一樣的造過於復雜的段式記憶體管理,那樣的MMU會給系統造成很大的延遲。
五、總線和時鐘
把總線單拉出來講是因為本工程CPU的延遲瓶頸在總線而不是儲存器。儲存器體積雖然大但是立體結構使得訊號傳輸時間相對較短。由於本工程CPU的EU部份介面太多,還都是16bit,還要考慮ALU輸入輸出介面朝向的問題,排了半天也很難將這些介面的距離縮短,最終變成了一個折線形排布。此時就需要總線將所有介面貫通起來。而本工程總線的一個重要特點是環狀的,因為遊戲用繼電器實作訊號傳輸具有二極管特性,只能單精靈通(做成雙向很麻煩),所以總線如果實作從任意段輸入任意段輸出只能走環路。環路雖然增加了一倍的距離,其延遲還在可以接受的範圍內,大約5.8秒(每一個bit位的總線一共58個繼電器800多米長)。最大的難題是當總線在某一周期的任務完成後,需要進行下一輪數據傳輸。但是因為環路的特性,繼電器的儲存器效應會讓環路保持原有的訊號。此時必須加一個開路裝置將原有的訊號阻斷。按照平常的思路在某一個環路節點加一排活塞將路線切斷,訊號會在總線裏拖尾5.8秒(因為繼電器會儲存相同長度訊號,切斷的節點其一邊的訊號會沿環路繞一大圈傳輸到另一邊後才會最終消失)。這樣的話一個周期一共要耗費11.6-12秒,這長度實在是難以接受。
在我本以為實在沒辦法解決這個延遲問題準備向其妥協的時候,突然想到了一個解決方案:總線清存也用時序邏輯控制。也就是說在總線上找若幹個節點都放上一排開路活塞,每一次傳輸完畢後所有活塞在同一時間切斷路線,那麽這時需要考慮的延遲時間就是相隔最遠的兩個節點之間的距離差。比如最後的成品中相隔最遠的兩個節點是180米,那麽就是1.2秒的訊號拖尾,從原來的5.8秒節省到1.2秒,總的單周期時間正好是7秒。只需要加一個總線控制電路讓其和系統時鐘同步就可以了。而且這樣設計的另一個好處馬上凸顯:在這1.2秒的清存時間裏,指令發射端正好可以做各種調整工作,此時不需要使用總線,打了一個時間差,意味著各器材都充分利用到了時間間隙,是一個讓我很驚訝的非常巧合的設計,感覺就好像有一種內在驅動力會讓這一切看起來就應該是這樣契合一樣。
下圖黑色方塊部份為總線清存器(第一部份已經提到過一次)。圖中藍白相間的,橙灰相間的,以及深灰色的路線全是總線,藍白相間的是高八位,橙灰相間的是低八位,深灰色的是轉角處的路線。顏色不同只是為了方便辨識節點和高低位,沒有功能上的區別。黑色方塊上有很多繼電器都是時序控制電路,用於周期性的向活塞輸出開路訊號。每7秒輸出一個1.2秒的訊號將一段一段的訊號阻隔直到全部消失。

時鐘暫定為總線周期7秒,取指周期5秒。所有訊號的源頭都是CU的時鐘訊號發生器發出的。一般的指令都是1或2周期,所以一般執行一條指令需要7或14秒,乘除類的運算指令時間較長,最長的除法指令需要6個周期。所以這個電腦的運算速度根本指望不上了,一個極簡單的程式就會執行幾分鐘。畢竟是在「電腦即時模擬電腦」,所以速度什麽的已經盡力做到最快了。
PS:在最新版的DATA BUS中,我做了相當多的改進,比如互聯駐存機制,每一個節點都可以儲存訊號,使訊號可以在同一周期內一直停留在環路內。
七、圖形顯示原理
說實話,顯視器是最難做的東西之一,因為完全是時序邏輯在控制還要顧及到和使用者的互動。而且圖形的東西對面積體積時間等問題要求極其嚴格(現實中的顯視器沒必要考慮那麽多,因為這些都不是瓶頸)。而圖形處理器就更是天方夜譚了,有很多玩家會說要是在Minecraft 裏造一台電腦可以玩Minecraft就吊炸天。這顯然不可能,而且想做一個純粹靠通用處理器運算來玩的小遊戲都絕對不可能。比如貪吃蛇這種影像重新整理率低的遊戲,肯定做不出來。
先簡單介紹一下現實中的圖形處理器以及顯視器是如何工作的,這對理解一些設計理念有很大幫助,也能解釋為啥MC裏如此難以實作標準意義上的顯卡。這一部份專業術語過多,僅供做相關參考,可以直接跳過看下面本工程的圖形器材的設計。
現實中的圖形顯示是按照「圖形流水線」(graphic pipeline)來完成的。一般我們玩的3D遊戲中,顯卡是影像處理的器材。顯卡的核心是GPU,CPU將應用程式的影像請求發送往GPU,GPU是圖形處理器,作為協處理器。作業系統將所有的器材統一編址,並具有各自規範,所以每一個作業系統要呼叫GPU必須要有相應GPU的軟件驅動程式。現在的GPU較為獨立,CPU大部份時間不參與圖形運算。GPU直接執行的是shader API,驅動程式指導GPU執行shader API,GPU的硬件結構將API編譯成一條一條instruction。現在常用的shader API是OpenGL和Direct3D。由於圖形運算是密集型並列運算,所以GPU內部有成百上千的unified shader ALU組成若幹模組如nVIDIA GPU中的SM或者AMD GPU中的CU ,這些模組是程式設計師直接面對的物件,包含FPU,Load/Store Unit和SFU等等。還有TMU,Tessellator,rasterizer等等流水線上其他的功能單元,我們叫這些東西為:Fixed Function Unit。GPU的底層指令按照warp/wave的模式每一個指令周期都有成百上千條被發射,這些指令相關性小,一般都是頂點,像素,幾何或紋理的shader指令。指令列隊叫thread,每一個thread都會對應一個像素或頂點,若幹shader ALU組成的vector單元同一時間用不同數據執行不同thread中相同的指令(因為front-end單元稀缺)。 每一個周期有成百上千個thread的某些指令被處理完,若幹周期後所有thread都處理完,這時候一張畫面就被初步執行完了,一般都是接近百萬個像素點比如1280x720分辨率的顯視器。之後圖形流水線會將畫面光柵化-rasterization,經過各種紋理,抗鋸齒處理後,完整的具有正確幾何資訊和顏色資訊的畫面就處理完了。然後該幅畫面就被送往幀緩存-framebuffer,這個是在視訊記憶體中劃出來的模組,等到合適的時機,該幅畫面就傳送往顯視器輸出,一張畫面稱為一幀。每秒鐘一個GPU繪制出幾十張這樣的畫面,人的肉眼就會看到流暢的畫面。
GPU是典型的SIMD結構,單指令多數據的大規模並列運算。並且其運算的數據多為浮點型。GPU耗費的晶體管數量會大於CPU,需要造一大堆重復的ALU陣列和寄存器陣列。
下面貼三張GPU架構圖,都是AMD(ATI)和nVIDIA這兩年的GPU產品(2013年前後)。
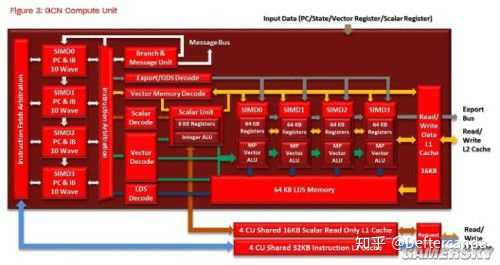
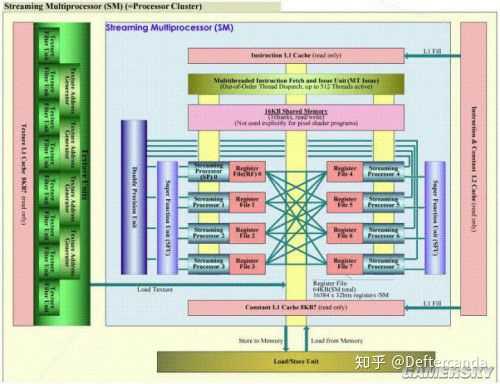
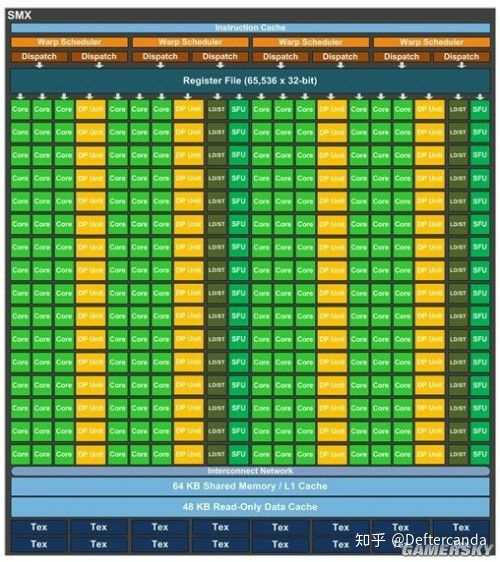
可以很明顯的看出GPU一般重複結構較多,都是SIMD陣列加上少數dispatch和其他shading pipeline結構,所以如果在minecraft中簡化到極致,比如每一個模組只造一個單元確實可以造出一個具有完整結構的顯卡,但是想要做一個可以持續輸出流暢畫面的GPU對於minecraft來說基本是不可能,光是造一個浮點ALU就要占據幾百乘以幾百乘以幾十的體積。假若一個螢幕按照30x30的像素來計算,並且是bitmap,只有亮暗兩種色彩。就算是2D的影像程式,一共900個像素,再放寬條件要求每3秒才出一幀,那麽每一秒鐘也要處理300個像素,按照最簡單的2D指令,假若平均一個像素只需要3條指令就能得出其是亮還是暗,那麽就需要300個ALU每秒運算3次。到這裏也不需要考慮其他什麽圖形流水線了,光是ALU團簇已經這麽多,造出標準意義的顯卡基本不可能。很多玩家認為在minecraft裏面可以造出執行minecraft的電腦,這種宏圖大業是不可能完成了。就算是常用的顯示程式比如作業系統界面,也沒不可能造出滑鼠這種東西了,因為不可能做出點控的器材。
然後回歸正題,既然造標準意義的顯卡不可能,那麽就退而求其次,做一些功能弱一些的顯示器材,比如說只要求顯視器輸出部份字元,並不要求其控制每一個像素。這樣可行度會大大提高。
演示影片中的小算盤和字元顯視器都是可以控制輸出字元的顯示器材。那麽該如何用盡量少的電路來實作這些結構並且能夠讓其反應迅速呢?又如何增加顯示器材與玩家的互動性呢?
前面已經介紹過minecraft中常見的影像訊號組成方式:紅石燈和陰影。影片裏正好展示了這兩種,小算盤和電子表部份用的是陰影,字元顯視器用的是紅石燈。為什麽這樣選擇呢,這和方塊的特性也有一定關系不過這個無關緊要。先來介紹小算盤的數碼顯示。
常接觸微控制器的人很容易看出我用的是七段數碼顯視器。七段顯視器顧名思義,所有十進制數碼資訊都可以由七個部份組成的,3橫4豎。電話機,老式收銀機上的數碼都是用這種方式顯示的。「8」這個數碼是最復雜的,它把7個段都用到了。

那麽如何用二進制電路表示十進制數呢?編碼的原則是越簡單越好,顯然10個十進制數碼可以用10個4位元二進制數表示,比如3是0011, 9是1001,這就是BCD碼。電腦說到底就是一堆不同種類的碼來回轉換的過程。要達到數碼顯示到螢幕上的過程,需要如下步驟:二進制碼發射到A單元上,A單元將二進制碼對應的十進制數連線到各數碼對應的七段資訊上,比如0100是數碼4,而4對應的七段資訊如上圖是左上,右上,中,右下四個段,最後這四個段每段3個方塊的活塞抽回來,則數碼4就被顯示出來,這整個過程譯碼了兩次,一次是二進制碼BIN轉十進制碼BCD一次,然後十進制碼轉對應的七段資訊是第二次。字元顯示也一樣是這種原理,具體後面具體再說。
上面所提的A單元就是譯碼器。電腦裏充斥了各種譯碼器。下圖為BIN轉BCD再轉七段資訊的譯碼器(橙色條形方塊下面的部份)。這個譯碼器經過極度的體積壓縮保證它占據的體積是所能實作的最小的。因為一連串字元排在一起,如果譯碼器較寬,一個一個排在一起會占據較大空間使數碼看起來松散。實際上整個工程每一個單元的體積我都盡了最大努力將其壓縮,這耗費非常大的腦力和精力。關於如何在三維結構上壓縮電路也可以單拉出來寫幾千字。

小算盤還需要控制端按鈕轉BIN譯碼器,多位BIN轉BCD譯碼器和多位BCD譯碼器轉BIN用於和CPU溝通,這些比較復雜就不多說了和顯示器材無關,上面部份已經介紹過演算法。
字元顯視器是點陣式的,即在一個5x5像素的點陣上顯示一個字元,如下圖5x5顯示器單元上的字母N,和七段顯視器一樣,後面一長串就是BIN轉字元轉5x5像素譯碼器。

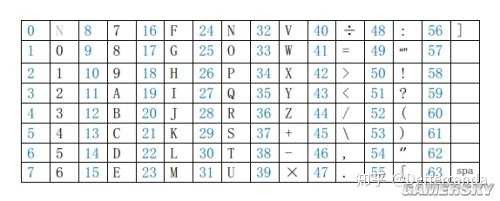
我使用的是自己設計的縮減版的ASCII碼,只有不到64個字元,如下表,我暫時稱之為ASCII X碼。
遊戲中能做到的最小像素是2x2個紅石燈,之所以不能做到1個紅石燈為一個像素,是因為體積上不可能做到在那麽小的空間裏控制每一個紅石燈的亮滅。而就算2x2的紅石燈為一個像素,也很難做到點控。關於這些字元譯碼的具體電路結構不作詳述,下面貼幾張字元顯視器的流水線結構,影片裏也有介紹:
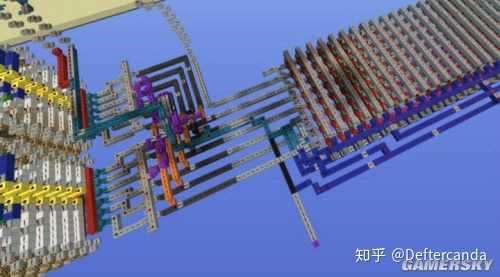



做這個顯視器耗費了較長的時間,我一開始的設計方案體積大概是這個的三倍,後來突發奇想解決了不少技術問題縮小了體積並改為完全的時序控制。現在還缺電腦鍵盤的互動式控制和其他幾個模組的顯示單元。
現在顯視器的鍵盤也制作完畢了,可以打字,修改,光標前後左右移位等


下面用幾段話回顧影片裏展示的功能。
首先是小算盤的功能:
1.時序控制
2.bit整數加減乘除,除法輸出商和余數
3.溢位判斷:輸入溢位,輸出溢位,除數為0:
然後是電子表功能:
1.關:
2.顯示0點0分0秒到23點59分59秒
3.過按鈕精確調整時間
關於電子表多說幾句。電子表對於整個CPU而言只是一個獨立的附屬物,我把它當做主要的展示品是因為電子表視覺化的效果比較好。原本我想再錄一些關於總線技術和流水線技術的影片,但是太抽象了看著都困就作罷。電子表電路原理很簡單,就是用移位觸發器迴圈一些數碼而已。重點不在原理而在電路體積大小。我花了些精力將電子表的體積壓縮到如下圖這樣,應該是非常迷你了。

最後是字元顯視器功能:
1.何標準儲存器並輸出儲存器中的字元資訊。
2.字元可換行換頁。
3.互動式操作,單字元控制(這個還沒做完所以影片裏沒有)。
影片裏有個字幕寫錯了,有一句話裏welcome沒有加最後那個e,不過已經費勁千辛萬苦把超清影片傳到優酷裏,就懶得重新壓影片再傳上去了。
關於工程的架構名稱:Alpha21016。之所以取這個名字,是為了紀念十幾年前DEC(Digital Equipment Corporation)的Alpha架構,那是一個處理器時代的傳奇,可惜商業上並不成功。Alpha組的人很多後來都去了Intel和AMD,並立下了汗馬功勞。
綜合影片和日誌粗略的介紹了一下工程,題目說是「技術細節」實際上還有好多沒介紹的,就先不說了,真要寫完估計要寫一本200多頁的書。具體的規劃細節比如各種重要功能結構的設計,指令集的設計,硬件單元介面排布,儲存器空間位置,流水線級數,動態分支預測,亂序執行,顯視器控制原理等等實在寫不動,這篇已經寫了2萬多字了(被我刪的刪,改的改,減的差不多了)。
最後再次感謝大家的支持!!!(這句是原文)
最新進展圖(2014年8月25日)



目前CPU已經可以執行若幹種機器指令(以MOV為主):通用寄存器賦值,按字/字節+立即數/間接/直接尋址。
詳細設定如下:
指令名稱:數據儲存器取數據至X寄存器
指令目標:將數據儲存器中的某一字/字節數據傳輸至X寄存器中
指令格式:00001 0/1 0/1 addr(9)
對應含義:指令碼 直接尋址/立即數尋址 按字/按字節 數據地址
備註:如果地址為奇數且為按字尋址,則改地址數據賦值到目的寄存器高8位元
指令名稱:傳輸MOV
指令目標:通用寄存器之間的數據傳輸
指令格式:1000000 x reg(4) reg(4)
對應含義:指令碼 無效 源寄存器地址 目的寄存器地址
指令名稱:加減乘除
指令目標:將被運算元取出傳輸至Y寄存器四則運算後儲存至X寄存器
指令格式:00100/00101/00110/00111 0/1 0/1 addr(9)
對應含義:加/減/乘/除 直接尋址/立即數尋址 取數計算/直接計算 數據地址
備註:只支持按字讀取數據儲存器
指令名稱:寄存器間接尋址
指令目標:將某寄存器中數據作為地址傳輸至MAR,取數後傳輸到任意寄存器
指令格式:1000001 0/1 reg(4) reg(4)
對應含義: 指令碼 按字/按字節 地址寄存器地址 目的寄存器地址
備註:Y寄存器不支持作為地址寄存器,其他寄存器都可以
————文末割一下,割割割割割————
2019年5月23日更新:
作者的話:
本文完成於2014年,時隔五年在知乎上因為被轉載而突然火起來,並受到很多褒獎和贊美,作為作者我感到很榮幸也感到很惶恐。有一些媒體朋友聯系我希望能夠繼續擴大傳播,我在此表示,本作品因為時間和精力有限最終沒有完全實作預先規劃的內容,並且現在已經有很多玩家可以做出類似的作品,我覺得本作品並沒有足夠的分量繼續在中文互聯網裏刷流量。實際上,一個電腦或微電子專業的本科生或研究生只要肯花時間,完全有能力做出類似的作品,只不過因為我在遊戲裏去實作它,在呈現方式上比較吸引人而已。我本身並不是電腦專業出身,出於對硬件的興趣愛好做了這樣一個作品。由於我本身專業基礎薄弱,寫的文章裏難免也會有錯誤和疏漏,希望大家的包涵和指正。
如果我的作品可以激起更多人探索電腦科學或者其他工程科學的熱情的話,就已經達到我想要的最好的目的。 希望年輕一代,尤其是中國的年輕一代,以後可以湧現出更多不拘一格的技術人才,在各自的領域創造出充滿想象力和創造力的作品。再次謝謝大家!
————我割,我割割割割割割————
我也想說兩句:
為什麽大家都要揪著延遲不放呢?只是快慢的問題而已,這不影響電腦的制造。











