這又是一個高頻的場景面試題,同時,它也是一個沒有標準答案的、可以跟面試官討論很久的面試題。
對於這個面試題,我的觀點是:「 沒有完美的方案,只有最適合某場景的方案。」
這個問題表面上看是數據一致性的問題,其實根本上,又是數據一致性、系統效能和系統復雜度的選擇與取舍。
下面我們先歷數一下各種技術方案,環肥燕瘦兩相宜,總有一款適合你。
首先,分享一套我自己逐字寫的、深入淺出、細致易懂的高頻面試題詳解,旨在以 一站式刷題 + 解惑 的方式幫你提升學習效率,需要的請自取。
強烈建議近期有求職訴求的Javaer好好看看。
1、先更新MySQL,再更新Redis
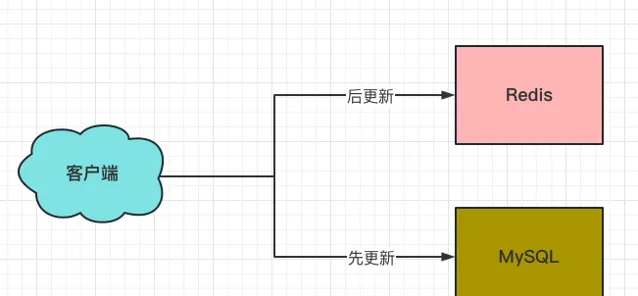
這個方案存在如下問題:
(1)如果先更新MySQL成功了,還未對Redis進行更新的間隙期,這時如果請求過來,讀到的都是Redis的更新前數據。
(2)如果先更新MySQL成功了,再更新Redis失敗了的話,後面的請求讀到的都是Redis的更新前數據,並且後續的補救方案很難做。
補救方案一:為Redis更新失敗,將MySQL中的對應數據也回滾了,以此達到兩者數據的一致性。但MySQL是主資料來源,它代表的是數據的「權威性」,這樣做顯然並不合理。
補救方案二:透過Redis重試更新的方式進行補救。但如果重試也失敗了,還要繼續重試嗎?是設定固定的重試次數,還是一直重試到成功為止?
另外,重試時間間隔設定多少?時間間隔設定長了,影響業務的時間也會變長;時間間隔設定短了,重試成功率又會降低。這些其實都是問題。
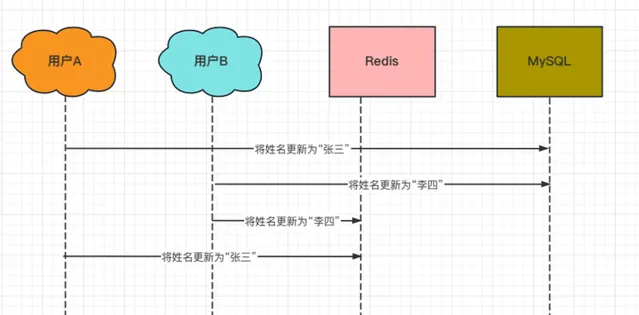
(3)兩個執行緒同時更新的並行問題,如下:
2、先更新Redis,再更新MySQL
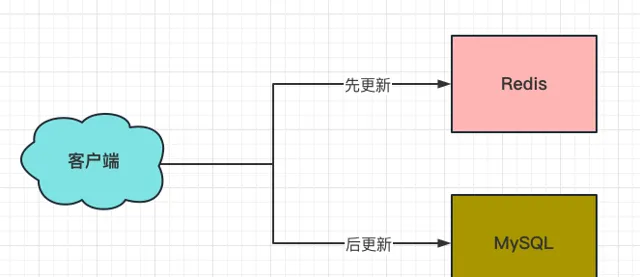
這個方案,要比方案一的「先更新MySQL,再更新Redis」合理一些。原因在於更新完Redis的話,哪怕還沒更新MySQL,這時如果請求過來,讀到的都是Redis更新後的新數據。
另外,先更新Redis成功,再更新MySQL失敗,可以透過再刪除Redis所對應的數據進行補救。
但其依然存在如下問題:
(1)如果先更新Redis成功了,再更新MySQL失敗了的話,還未對Redis所對應的數據進行刪除補救的間隙期,這時如果請求過來,讀到的都是Redis未生效的新數據。
(2)如果先更新Redis成功了,再更新MySQL失敗了的話,然後再刪除Redis對應的數據也失敗的時候,應該如何處理?如果透過重試機制繼續進行刪除Redis的話,又會面臨之前說的重試次數和間隔期的問題。
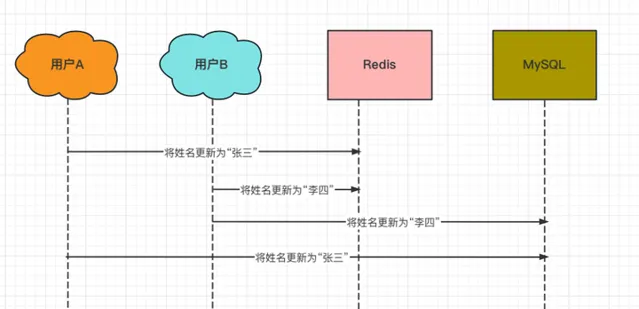
(3)兩個執行緒同時更新的並行問題,如下:
3、先更新MySQL,再刪除Redis
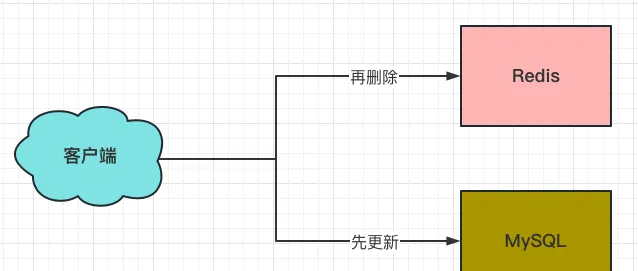
這個方案可以解決「並行更新」的問題,但依然會存在下面的兩個問題:
(1)如果先更新MySQL成功了,還未對Redis進行刪除的間隙期,這時如果請求過來,讀到的都是Redis的刪除前數據。
(2)如果先更新MySQL成功了,再刪除Redis失敗了的話,後面的請求讀到的都是Redis的刪除前數據,並且後續的補救方案很難做。
4、先刪除Redis,再更新MySQL
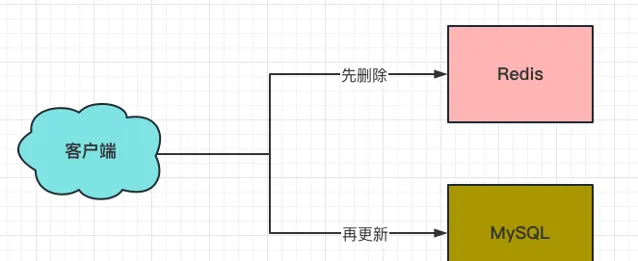
這個方案能解決方案3中遺留的兩個棘手的問題:
(1)如果先刪除Redis成功了,還未對MySQL進行更新的間隙期,此時對於該條數據而言,只存在於MySQL一個儲存載體中,也就沒有了數據一致性的問題。
(2)如果先刪除Redis成功了,再更新MySQL失敗了的話,此時對於該條數據而言,只存在於MySQL一個儲存載體中,所謂的補救方案也就不需要了,直接當這條數據沒更新成功。
OK,整體看起來似乎「天下無賊」了,但真的如此嗎?其實不然,如果配合上Redis的「讀策略」,還是會有數據一致性的問題。
4.1 先刪除Redis,再更新MySQL + Redis讀策略
Redis的讀策略:
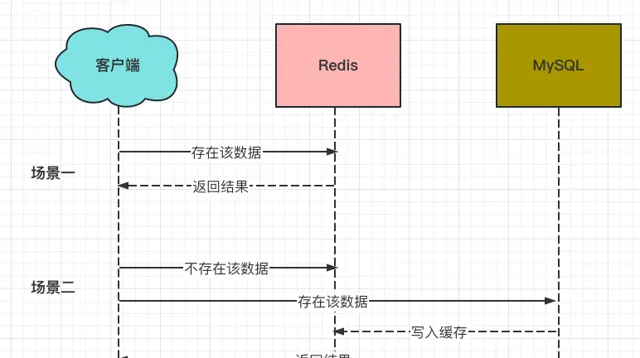
這樣一來,就會存在如下問題:
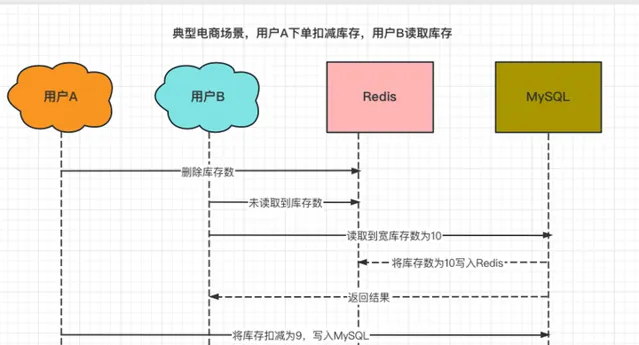
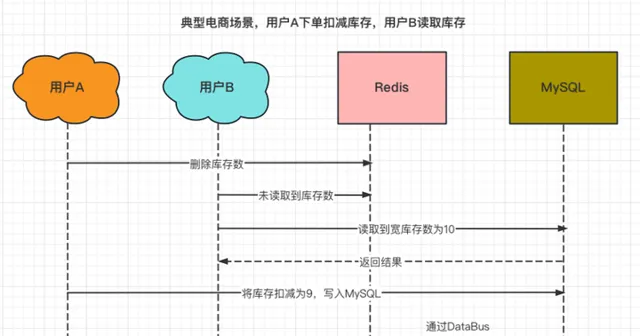
某商品的庫存數為10個,使用者A購買一件商品時進行庫存扣減,因此第一步先刪除了Redis中的庫存數。
這時,使用者B查詢該商品的庫存,發現Redis中並沒有該商品的庫存,於是從MySQL中讀取庫存數後,寫入到了Redis中(10個)。
然後,使用者A更新資料庫,將庫存數從10個扣減為9個。
最終,Redis中的庫存數是10個,MySQL中的庫存數是9個。
4.2 先刪除Redis,再更新MySQL + Binlog同步
該方案將填充Redis的操作,改為透過DataBus和Canal同步Binlog的方式,這樣可以解決方案4.1中的Redis讀策略帶來的數據一致性問題。
但是,這種方案的適用於數據量不大,可以完全吃進Redis緩存中,並設定為永不過期的場景。
而那種數據量龐大到不能全部吃進Redis緩存中,需要在數據讀取的時機來寫入Redis,長時間未被讀取的數據則過期淘汰的場景,就不適合了。
因為這種方案的緩存命中率太低了,也就失去了其應有的價值。
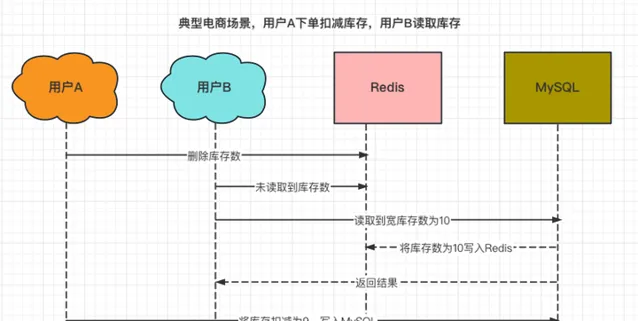
4.3 先刪除Redis,再更新MySQL + Redis讀策略 + 延時雙刪
這個方案稍復雜了一些,是在方案4.1中「先刪除Redis,再更新MySQL + Redis讀策略」,又增加了最後一步Redis刪除的操作。
它可以解決「最終,Redis中的庫存數是10個,MySQL中的庫存數是9個」的數據一致性場景。
也可以跟方案4.2中 「數據量龐大到不能全部吃進Redis緩存中,需要在數據讀取的時機來寫入Redis,長時間未被讀取的數據則過期淘汰」的不適合場景進行互補。
有人會說,這種方案也不能100%保證解決數據一致性的問題,如果最後一步刪除操作失敗了怎麽辦?
確實,它並不能保證100%。
但如果第一步刪除Redis成功了,第二步Redis讀策略恰好在這個間隙期發生並寫入Redis成功了,而第三步刪除Redis又失敗了,這種機率有多大?0.0000001%的可能性有沒有?
btw:此處請杠精留言,我最喜歡看到你們面紅耳赤、聲嘶力竭地杠的樣子,很性感。
5、分布式鎖
有人說,直接用分布式鎖,不就把問題都解決了嗎?幹嗎嘰嘰歪歪地寫這麽多字?
是的,分布式鎖完全可以解決一致性問題,但你別忘了,引入鎖機制的最大弊端是什麽?是效能。
而我們用Redis當緩存的初衷是什麽?還是效能。有句話怎麽說的來著?勿忘初心,方得始終。
結語
還是那句話,系統架構設計中,沒有銀彈,也沒有完美的方案,只有最適合某場景的方案。
分享一套我自己逐字寫的、深入淺出、細致易懂的高頻面試題詳解,旨在以 一站式刷題 + 解惑 的方式幫你提升學習效率,需要的請自取。
強烈建議近期有求職訴求的Javaer好好看看。










