今天來說一個老生常談的問題,來看一個實際案例:
現有業務中往往都會透過緩存來提高查詢效率,降低資料庫的壓力,尤其是在分布式高並行場景下,大量的請求直接存取 Mysql 很容易造成效能問題。
有一天老板找到了你......
老板:聽說你會緩存?
你:來看我操作。

你設計了一個最常見的緩存方案,基於這種方案,開始對使用者積分功能進行最佳化,但當你睡的正酣時,系統悄悄進行了下面操作:
1、執行緒 A 根據業務會把使用者 id 為 1 的積分更新成 100
2、 執行緒 B 根據業務會把使用者 id 為 1 的積分更新成 200
3、在資料庫層面,由於資料庫用鎖來保證了 ACID,執行緒 A 和執行緒 B 不存在並行情況,,無論資料庫中最終的值是 100 還是 200,我們都假設正確
4、假設執行緒 B 在 A 之後更新資料庫,則資料庫中的值為 200
5、執行緒 A 和執行緒 B 在回寫緩存過程中,很可能會發生執行緒 A 線上程 B 之後操作緩存的情況(因為網路呼叫存在不確定性),這個時候緩存內的值會被更新成 100,發生了緩存和資料庫不一致的情況。
第二天早上你收到了使用者投訴,怎麽辦?人工修改積分值還是刪庫跑路?
凡是處於不同物理位置的兩個操作,如果操作的是相同數據,都會遇到一致性問題,這是分布式系統不可避免的一個痛點。
1 什麽是數據一致性?
數據一致性通常講的主要是數據儲存系統,主從 mysql、分布式儲存系統等,如何保證數據一致性,
比如說主從一致性,副本一致性,保證不同的時間或者相同的請求存取這種主從資料庫時存取的數據是一致性的,不會這次存取是結果 A 下次是結果 B。
2 CAP 定理
說到數據一致性,就必須說 CAP 定理。
CAP 定理是 2000 年由 Brewer 提出的,他認為分布式系統在設計和部署時,面臨 3 個核心問題:
Consistency:一致性。資料庫 ACID 操作是在一個事務中對數據加以約束,使得執行後仍處於一致狀態,而分布式系統在進行更新操作時所有的使用者都應該讀到最新值。
Availability:可用性。每一個操作總是能夠在一定時間內返回結果。結果可以是成功或失敗,一定時間是給定的時間。
Partition Tolerance:分區容忍性。考慮系統效能和可伸縮性,是否可進行數據分區。
CAP 定理認為,一個提供數據服務的儲存系統無法同時滿足數據一致性、數據可用性、分區容忍性。
為什麽?如果采用分區,分布式節點之間就需要進行通訊,涉及到通訊,就會存在某一時刻這一節點只完成一部份業務操作,在通訊完成的這一段時間內,數據就是不一致的。如果要保證一致性,就要 在通訊完成的這段時間內保護數據,使得對存取這些數據的操作都不可用。
反過來思考,如果想保證一致性和可用性,那麽數據就不能夠分區。一個簡單的理解就是所有的數據就必須存放在一個資料庫裏面,不能進行資料庫拆分。這個對於大數據量、高並行的互聯網套用來說,是不可接受的。
3 數據一致性模型
基於 CAP 定理,一些分布式系統透過復制數據來提高系統的可靠性和容錯性,也就是將數據的不同副本存放在不同的機器。常用的一致性模型有:
強一致性: 數據更新完成後,任何後續存取將會返回最新的數據。這在分布式網路環境幾乎不可能實作。
弱一致性:系統不保證數據更新後的存取會得到最新的數據。客戶端獲取最新的數據之前需要滿足一些特殊條件。
最終一致性:是弱一致性的一種特例,保證使用者最終能夠讀取到某操作對系統特定數據的更新。
4 如何保證數據一致性?
針對剛開始的問題,如果加以思考,你可能會發現不管是先寫 MySQL 資料庫,再刪除 Redis 緩存;還是先刪除緩存,再寫庫,都有可能出現數據不一致的情況。
(1)先刪除緩存
1、如果先刪除 Redis 緩存數據,然而還沒有來得及寫入 MySQL,另一個執行緒就來讀取;
2、這個時候發現緩存為空,則去 Mysql 資料庫中讀取舊數據寫入緩存,此時緩存中為臟數據;
3、然後資料庫更新後發現 Redis 和 Mysql 出現了數據不一致的問題。
(2)後刪除緩存
1、如果先寫了庫,然後再刪除緩存,不幸的寫庫的執行緒掛了,導致了緩存沒有刪除;
2、這個時候就會直接讀取舊緩存,最終也導致了數據不一致情況;
3、因為寫和讀是並行的,沒法保證順序,就會出現緩存和資料庫的數據不一致的問題。
解決方案 1:分布式鎖
在平時開發中,利用分布式鎖可能算是比較常見的解決方案了。利用分布式鎖把緩存操作和資料庫操作封裝為邏輯上的一個操作可以保證數據的一致性,具體流程為:
1、每個想要操作緩存和資料庫的執行緒都必須先申請分布式鎖;
2、如果成功獲得鎖,則進行資料庫和緩存操作,操作完畢釋放鎖;
3、如果沒有獲得鎖,根據不同業務可以選擇阻塞等待或者輪訓,或者直接返回的策略。
流程見下圖:
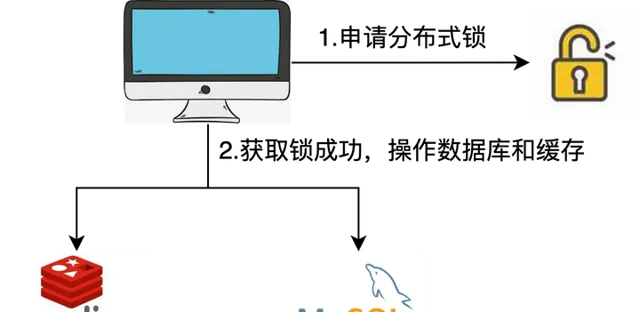
利用分布式鎖是解決分布式事務的一種方案,但是在一定程度上會降低系統的效能,而且分布式鎖的設計要考慮到 down 機和死結的意外情況。
解決方案 2:延遲雙刪
在寫庫前後都進行 redis.del (key) 操作,並且設定合理的超時時間。
虛擬碼如下:
public void write( String key, Object data ){
redis.delKey( key );
db.updateData( data );
Thread.sleep( 500 );
redis.delKey( key );
}
具體步驟:
1、先刪除緩存
2、再寫資料庫
3、休眠 500 毫秒(這個根據讀取的業務時間來定)
4、再次刪除緩存
來看之前的案例在這種方案下的情景:
T1 執行緒線刪除緩存再更新 db , T1 執行緒更新 db 完成之前 T2 執行緒如果讀取到 db 舊的數據,會再把舊的數據寫入 Redis 緩存。
此時 T1 執行緒延遲一段時間後再刪除 Redis 緩存操作。當其他執行緒再讀取緩存為 null 時會查詢 db 最新數據重新進行緩存,保證了 Mysql 和 Redis 緩存的數據一致性。
在此基礎上,緩存也要設定過期時間,來保證最終數據的一致性。 只要緩存過期,就去讀資料庫然後重新緩存。
這種雙刪 + 緩存超時的策略,最差的情況是在緩存過期時間內發生數據存在不一致,而且寫的時候增加了耗時。
但是這種方案還會出現一個問題,如何保證寫入庫後,再次刪除緩存成功?
如果刪除失敗,還有可能出現數據不一致的情況。這時候需要提供一個重試方案。
解決方案 3:異步更新緩存(基於 Mysql binlog 的同步機制)
1、涉及到更新的數據操作,利用 Mysql binlog 進行增量訂閱消費;
2、將訊息發送到訊息佇列;
3、透過訊息佇列消費將增量數據更新到 Redis 上。
這樣的效果是:
讀取 Redis 緩存:熱數據都在 Redis 上;
寫 Mysql:增刪改都是在 Mysql 進行操作;
更新 Redis 數據:Mysql 的數據操作都記錄到 binlog,透過訊息佇列及時更新到 Redis 上。
這樣一旦 MySQL 中產生了新的寫入、更新、刪除等操作,就可以把 binlog 相關的訊息推播至 Redis,Redis 再根據 binlog 中的記錄,對 Redis 進行更新。
其實這種機制,很類似 MySQL 的主從備份機制,因為 MySQL 的主備也是透過 binlog 來實作的數據一致性。
方案 2 中的重試方案就可以借助方案 3,啟動一個訂閱程式訂閱資料庫的 binlog,提取所需要的數據和 key,另起程式碼獲取這些資訊。如果嘗試刪除緩存失敗,就發送訊息給訊息佇列,重新從訊息佇列獲取數據,重試刪除操作。
參考文件:
感謝閱讀~
作者:京東零售 李澤陽來源:京東雲開發者社群 轉載請註明來源










