更全面的參考AI崗位面試題整理
大模型相關
1.了解Transformer嗎?底層是什麽結構?cuda中如何最佳化?
Transformer是一種基於註意力機制的序列模型,最初由Google的研究團隊提出並套用於機器轉譯任務。與傳統的迴圈神經網路(RNN)和摺積神經網路(CNN)不同,Transformer僅使用自註意力機制來處理輸入序列和輸出序列,因此可以平行計算,極大地提高了計算效率。
底層結構 :
Transformer的底層結構主要包括輸入層、詞嵌入層、編碼器和解碼器層以及輸出層。
- 輸入層:將輸入的句子中的每個詞表示成一個向量,然後輸入到Transformer模型中。
- 詞嵌入層:將輸入層的向量作為輸入,將每個詞轉化成一個更高維度的向量,以便模型可以更好地處理這些資訊。
- 編碼器和解碼器層:Transformer模型的核心部份,它包含了若幹個編碼器和解碼器層,負責將輸入序列編碼成一個稠密的向量表示,然後將這個向量解碼成輸出序列。
- 輸出層:將解碼器層的輸出轉化成輸出序列中的詞的機率分布。
CUDA中如何最佳化 :
在CUDA中最佳化Transformer模型主要涉及以下幾個方面:
- 記憶體最佳化 :由於Transformer模型的計算涉及到大量的張量操作和記憶體存取,因此最佳化記憶體使用對於提高效能至關重要。可以使用半精度(例如float16)將張量保存在記憶體中,以減少記憶體占用。然而,當以較低精度計算梯度時,某些值可能太小,以至於被視為零,這種現象被稱為「溢位」。為了防止「溢位」,原始論文的作者提出了一種梯度縮放方法。PyTorch從1.6的版本開始提供了一個包:torch.cuda.amp,具有使用自動混合精度所需的功能(從降低精度到梯度縮放),自動混合精度作為上下文管理器實作,因此可以隨時隨地的插入到訓練和推理指令碼中。
- 平行計算 :由於Transformer模型的平行計算能力很強,可以利用CUDA的GPU加速計算。透過合理安排執行緒和數據劃分,可以最大化GPU的利用率,提高模型的計算速度。
- 最佳化演算法 :針對Transformer模型的計算特點,可以采用一些最佳化的演算法來進一步提高效能。例如,可以使用矩陣分解、低秩近似等技術來降低計算的復雜度。
- 緩存最佳化 :由於Transformer模型中涉及大量的數據存取,因此最佳化緩存的使用對於提高效能至關重要。可以透過合理安排數據布局、使用緩存友好演算法(如kv cache等)等方式來提高緩存的利用率。
2.對大模型的理解。
大模型是指包含超大規模參數(通常在十億個以上)的神經網路模型,具有以下特征:
- 巨大的規模:大模型包含數十億個參數,模型大小可以達到數百GB甚至更大。這種巨大的模型規模為其提供了強大的表達能力和學習能力。
- 多工學習:大模型通常會一起學習多種不同的NLP任務,如機器轉譯、文本摘要、問答系統等。這可以使模型學習到更廣泛和泛化的語言理解能力。
- 強大的計算資源:訓練大模型通常需要數百甚至上千個GPU,以及大量的時間,通常在幾周到幾個月。這可以加速訓練過程而保留大模型的能力。
- 豐富的數據:大模型需要大量的數據來進行訓練,只有大量的數據才能發揮大模型的參數規模優勢。
大模型在自然語言處理領域得到廣泛套用,並正在徹底改變NLP任務的狀態,催生出更強大、更智慧的語言技術。大模型是AI發展的重要方向之一。同時,大模型也具有在各種自然語言處理任務中表現出色的能力,例如文本分類、情感分析、摘要生成、轉譯等。大模型可以用於自動寫作、聊天機器人、虛擬助手、語音助手、自動轉譯等多個套用領域。
此外,大模型通常包含數十億個參數,這使得它們能夠捕捉到大規模數據中的復雜模式和規律,從而預測出更加準確的結果。這也是為什麽大模型在自然語言處理等領域表現出色,能夠應對更復雜、更龐大的數據集或任務的原因之一。
3.知道Faster Transformer嗎?如何實作的?
FasterTransformer是一個庫,用於實作基於Transformer的神經網路推理的加速引擎。對於大模型,它以分布式方式跨越許多GPU和節點進行推理。FasterTransformer包含Transformer塊的高度最佳化版本的實作,其中包含編碼器Encoder和解碼器Decoder部份。基於FT可以執行完整的編碼器-解碼器架構(如T5大模型)以及僅編碼器模型(如BERT)或僅解碼器模型(如GPT)的推理。
使用cublas最佳化GEMM
矩陣乘法外的kernel:盡可能融合
4.Paged Attention有了解嗎?
Paged Attention是一種對kv cache所占空間的分頁管理策略。這是一種以記憶體空間換取計算開銷的手段,與現今大模型訓練中的recompute中間activation用於bwd的策略(以計算開銷換記憶體空間)相反。
其原理是受作業系統中的分頁(paging)演算法啟發,將序列中的KV緩存劃分為KV塊,每個塊包含固定數量tokens的鍵(K)和值(V)向量。在註意力計算期間,Paged Attention內核分別辨識和獲取不同的KV塊,這些塊在實體記憶體上可能不連續。然後將查詢向量與塊中的鍵向量相乘得到部份註意力得分,再乘以塊中的值向量得到最終註意力輸出。這種設計使得KV塊可以儲存在非連續的實體記憶體中,從而使記憶體管理更加靈活。
Paged Attention極大的節約了keys values matrix的占用空間,可以做更大batch size的推理,目前tensorRT-LLM和vLLM都有這個策略。
深度學習相關
1.cuda中如何寫Softmax?某個參數過大如何解決?
Softmax函式常在神經網路輸出層充當啟用函式,將輸出層的值透過啟用函式對映到0-1區間,將神經元輸出構造成機率分布,用於多分類問題中,Softmax啟用函式對映值越大,則真實類別可能性越大。
softmax的計算過程:
- 先做一個 ReduceMax 求最大值操作,得到輸入每一行的最大值;
- 然後做一個 BroadcastSub 減法操作,拿輸入每一行的各點減去每一行的最大值;
- 然後做一個自然指數Exp 操作,對輸入每一行的各點計算指數;
- 然後做一個 ReduceSum 求和操作,對輸入每一行的各點求得的指數對映做一個求和;
- 最後做一個 BroadcastDiv 除法操作, 拿輸入每一行的各點求得的指數對映除以4中得到的和;
如果某個參數過大,可以使用對數變換或指數變換將其轉化為一個較小的範圍,然後再進行Softmax計算。例如,可以使用
log1p
或
exp
函式進行對數變換或指數變換。
2.Dropout和BatchNorm在訓練和推理時有什麽區別?
訓練時:
推理時:
3.談談無監督學習演算法
無監督學習演算法是一種機器學習演算法,它不需要預先標記的數據來訓練模型。相反,它從無標簽的數據中學習數據的隱藏模式或結構。這種演算法主要用於找出數據的隱藏模式或結構,而不是預測特定的標簽。
以下是幾種常見的無監督學習演算法:
- 聚類演算法:這是最常用的無監督學習演算法之一。它將數據分成幾個組,使得同一組內的數據項相互之間非常相似,而與其他組的數據項非常不同。常見的聚類演算法包括K-均值聚類、層次聚類等。
- 降維演算法:這種演算法被用來降低處理高維數據的復雜性,同時盡量保留其原始數據的特性。常見的降維演算法有主成分分析(PCA)和t-分布鄰域嵌入演算法(t-SNE)等。
- 自編碼器(AutoEncoders):這是一種神經網路,它學習如何有效地編碼輸入資訊,然後如何將這些資訊重建為原始輸入的近似表示。它們被用於降維或者特征學習。
這些演算法在許多領域都有套用,如影像辨識、語音辨識、推薦系統等。
GPU相關
1. 描述一下SM的結構,在寫kernel的時候共享記憶體大小和寄存器檔數量需要註意嗎?
GPU的SM(流式多處理器)結構是圍繞一個流式多處理器(SM)的擴充套件陣列搭建的,透過復制這種結構來實作GPU的硬體並列。每個SM都能支持數百個執行緒並行執行,每個GPU通常有多個SM。
在寫kernel的時候,共享記憶體大小和寄存器檔數量是需要考慮的。
- 共享記憶體大小:共享記憶體是SM中非常重要的元件,它被所有CUDA核心共享。在寫kernel時,需要合理使用共享記憶體,以避免頻繁的記憶體存取和數據拷貝,從而提高程式的效率和效能。如果需要傳遞大量數據到kernel中,或者需要頻繁存取數據,可以考慮使用共享記憶體。
- 寄存器檔數量:寄存器檔是SM中的另一個重要元件,它被CUDA核心使用。每個CUDA核心都有一個完全流水線化的整數算術邏輯單元(ALU)和一個浮點單元(FPU),每個核心都有一個與之相關的寄存器檔。在寫kernel時,需要註意不要使用過多的寄存器檔,因為每個寄存器檔都需要消耗一定的硬體資源。
2. 共享記憶體和寄存器分別應該存放哪些數據,其用量與SM上活躍的執行緒塊的關系?
- 共享記憶體:
3. bank沖突是什麽?描述具體結構,如何解決?
GPU Bank沖突是指在使用GPU進行平行計算時,不同的執行緒或執行緒塊試圖同時存取同一Bank中的不同地址,導致存取沖突。
具體結構方面,GPU的記憶體被劃分為多個Bank,每個Bank可以獨立地服務一個執行緒。當多個執行緒同時存取同一個Bank的不同地址時,就會發生Bank沖突。
解決GPU Bank沖突的方法有多種,以下是一些常見的解決方法:
- 最佳化數據布局:透過合理地布局數據,減少不同執行緒或執行緒塊之間的數據重疊,從而減少Bank沖突的可能性。
- 使用不同的Bank:對於需要同時存取同一Bank的不同地址的情況,可以透過使用不同的Bank來避免沖突。例如,可以使用不同的Bank來儲存不同的數據部份,或者使用不同的Bank來儲存不同的執行緒或執行緒塊的數據。
- 增加Bank數量:透過增加Bank的數量,可以增加每個Bank的獨立性,從而減少Bank沖突的可能性。
- 使用多播機制:當一個warp中的多個執行緒同時存取一個Bank的相同地址時,可以使用多播機制將該地址廣播給這些執行緒,從而避免Bank沖突。
4. 說一下分支沖突,如果warp內有沖突,部份符合if條件,部份符合else條件,是否需要等待?
GPU分支沖突是指在一個warp內部,如果一個執行緒的分支路徑與其他執行緒的分支路徑不同,就會發生分支沖突。當發生分支沖突時,GPU需要等待所有執行緒完成各自的分支路徑,然後再繼續執行。
如果warp內有沖突,部份執行緒符合if條件,部份執行緒符合else條件,那麽GPU需要等待所有執行緒完成各自的分支路徑。這意味著,即使部份執行緒已經滿足條件並可以繼續執行,其他執行緒也需要等待它們完成所有分支路徑後才能繼續執行。
GPU的分支沖突可能會導致效能下降,因為執行緒需要等待其他執行緒完成分支路徑。在編寫GPU程式碼時,需要盡量避免分支沖突的發生。可以透過最佳化數據布局、使用不同的Bank、增加Bank數量、使用多播機制等方法來減少分支沖突的可能性。
5.了解TensorCore的原理嗎?
TensorCore是由深度學習引擎和特殊的硬體電路組成的,它可以執行高精度的矩陣乘法和矩陣加法運算,大大提高了深度學習模型中涉及到的矩陣計算的效率。TensorCore采用了16位元浮點數(FP16)的數據格式,相對於傳統的32位元浮點數(FP32),它在儲存和計算方面都具有更高的效率。
TensorCore的核心原理是混合精度計算。它可以將輸入的FP16格式的矩陣乘法運算拆解成更小的矩陣乘法運算,然後透過一系列的指令和硬體電路將其計算得到的結果合並成最終的結果。這種混合精度計算的方式既保證了計算的精度,又提高了計算的速度和效率。
6.為什麽用float4向量來存取數據?有什麽好處?
使用float4向量來存取數據可以提高GPU編程的效率、節省記憶體空間、方便進行向量運算以及易於擴充套件。
- 高效的記憶體存取:GPU架構通常采用共享記憶體的方式,多個執行緒可以同時存取同一共享記憶體地址。使用float4向量可以充分利用這種並列存取的特性,提高記憶體存取的效率。
- 節省記憶體空間:與單獨使用float型別的變量相比,使用float4向量可以減少記憶體占用。
- 高效的向量運算:GPU支持向量的運算操作,包括加法、減法、乘法、點積等。使用float4向量可以方便地進行這些運算操作,提高計算效率。
7.為什麽使用雙緩沖最佳化?了解cuda流和cuda graph嗎?
使用雙緩沖最佳化是為了解決幀緩沖區讀取和重新整理的效率問題。透過引入兩個緩沖區,即雙緩沖機制,GPU可以預先渲染好一幀放入一個緩沖區內,讓視訊控制器讀取。當下一幀渲染好後,GPU會直接把視訊控制器的指標指向第二個緩衝區。這樣,效率會有很大的提升。
CUDA流表示一個GPU操作佇列,該佇列中的操作將以添加到流中的先後順序而依次執行。可以將一個流看做是GPU上的一個任務,不同任務可以並列執行。使用CUDA流,首先要選擇一個支持裝置重疊(Device Overlap)功能的裝置,支持裝置重疊功能的GPU能夠在執行一個CUDA核函式的同時,還能在主機和裝置之間執行復制數據操作。支持重疊功能的裝置的這一特性很重要,可以在一定程度上提升GPU程式的執行效率。
CUDA Graphs為CUDA中的工作送出提供了一種新模式。圖是一系列操作,例如內核啟動,由依賴關系連線,獨立於其執行定義。這允許一個圖被定義一次,然後重復執行。將圖的定義與其執行分開可以實作許多最佳化:首先,與流相比,GPU啟動成本降低,因為大部份設定都是提前完成的;其次,將整個工作流程呈現給CUDA可以實作最佳化,這可能無法透過流的分段工作送出機制實作。
8.除了MPI,有知道現在用的更多的GPU通訊庫嗎?
除了MPI,現在常用的GPU通訊庫包括NCCL和CUDNN。
NCCL(Nvidia Collective Communications Library)是由Nvidia開發的庫,專為多GPU和多節點環境中的高效通訊而設計。它提供了一組API,用於實作數據平行計算中的集體操作,如廣播、聚合和排序。NCCL在多GPU環境中表現出色,並且與CUDA緊密整合。
CUDNN(CUDA Deep Neural Network Library)是另一個由Nvidia開發的庫,專為深度神經網路套用而設計。它提供了一組API和功能,用於實作高效的GPU加速神經網路計算。CUDNN提供了各種操作函式和演算法,如摺積、池化、啟用函式和損失函式等。它還支持各種神經網路架構,包括摺積神經網路、迴圈神經網路和全連線神經網路等。
這些庫都為GPU通訊提供了高效的解決方案,並支持大規模平行計算。它們與MPI類似,都提供了在分布式機器學習中實作GPU間通訊的工具。
9.在Nsight Computing中,解釋下L1 Cache命中率?
L1 Cache命中率是指程式在L1 Cache中成功找到所需數據的比例。在GPU計算中,由於數據在GPU記憶體和L1 Cache之間頻繁移動,因此L1 Cache命中率對於效能至關重要。
透過關註L1 Cache命中率,可以了解程式中數據存取模式與GPU記憶體和緩存之間的互動情況。如果L1 Cache命中率較低,則意味著程式需要從GPU記憶體中讀取數據,這可能導致效能下降。
10.GPU指令集最佳化方面了解嗎?PTX相關的最佳化了解嗎?
GPU指令集最佳化是提高GPU程式效能的重要手段之一。在GPU編程中,透過選擇合適的指令集和最佳化指令的使用,可以減少記憶體存取、提高計算速度和減少功耗。
PTX(Parallel Thread Execution)是NVIDIA的GPU組合語言,它提供了一套豐富的指令集,用於描述GPU上的平行計算任務。PTX最佳化主要是針對PTX指令的最佳化,包括指令的選擇、排程和執行等方面。
在PTX最佳化方面,可以考慮以下幾個方面:
- 指令選擇:根據具體的計算任務和數據存取模式,選擇合適的PTX指令,以最大化計算效能和效率。
- 指令排程:合理安排指令的執行順序,減少依賴關系和沖突,提高指令的執行效率。
- 記憶體存取最佳化:透過減少記憶體存取次數、提高記憶體存取效率等方式,減少記憶體頻寬的占用,提高計算效能。
- 迴圈展開:透過將迴圈展開為多個叠代並列執行的方式,減少迴圈的開銷,提高計算效能。
11.GEMM是計算密集型還是訪存密集型算子?
GEMM(General Matrix Multiply)是一種常見的矩陣乘法運算,可以套用於深度學習、科學計算、影像處理等領域。在GPU編程中,GEMM通常被視為一個計算密集型算子,因為它涉及到大量的乘法和加法運算。
然而,GEMM也可以被認為是訪存密集型算子,因為它需要從記憶體中讀取大量的數據。在GPU上執行GEMM時,通常會將輸入矩陣和輸出矩陣儲存在GPU的視訊記憶體中,然後透過GPU的平行計算能力來執行矩陣乘法操作。因此,GEMM既涉及到大量的計算操作,也涉及到大量的記憶體存取操作。
在實際套用中,為了提高GEMM的效能,通常會采用一些最佳化技術,如共享緩存、數據重用、矩陣分塊等。這些最佳化技術可以減少記憶體存取次數和等待時間,提高程式的執行效率。因此,雖然GEMM既涉及到計算密集型操作也涉及到訪存密集型操作,但透過最佳化技術可以將其轉化為高效的計算操作。
12.cutlass中如何對GEMM進行最佳化的?
CUTLASS是一個NVIDIA的開源樣版庫,旨在提供一種用較小的成本寫出一個效能不是那麽差的GEMM的能力。CUTLASS內建了針對GEMM的meta schedule,能夠讓計算盡量掩蓋訪存延遲從而達到不錯的效能。
在CUTLASS中,對GEMM進行最佳化的方式主要有以下幾個方面:
- 緩存利用:利用GPU的緩存來減少記憶體存取次數。透過將數據緩存在GPU的緩存中,可以減少從記憶體中讀取數據的次數,從而提高程式的執行效率。
- 數據重用:在GEMM中,經常需要重復使用相同的數據。透過將數據緩存在GPU的視訊記憶體中,可以避免頻繁地從記憶體中讀取相同的數據,從而提高程式的執行效率。
- 矩陣分塊:將大矩陣拆分成小塊,然後分別進行計算。這樣可以減少記憶體存取的次數,並且可以利用GPU的平行計算能力來加速計算。
- 最佳化迴圈結構:透過最佳化迴圈結構,可以減少迴圈次數和分支判斷,從而提高程式的執行效率。
- 最佳化指令使用:透過選擇合適的指令和最佳化指令的使用,可以提高程式的執行效率。例如,選擇適合的乘法和加法指令,避免不必要的記憶體存取和數據轉換等。
13. 知道TensorRT嗎?部署過推理模型嗎?
TensorRT是NVIDIA釋出的深度學習模型推理最佳化器和部署工具。它能夠實作高效能的推理,支持跨平台,包括NVIDIA GPU、CPU和FPGA等。
對於TensorRT的部署,它提供了API和工具,使得開發者能夠將深度學習模型部署到雲端、邊緣和嵌入式裝置上。TensorRT支持多種深度學習框架,包括TensorFlow、PyTorch、MXNet等,同時也支持多種程式語言,如Python、C++等。
在部署推理模型方面,TensorRT可以最佳化模型的計算效能、記憶體使用和能源效率等。它透過多種最佳化技術,如融合乘法運算、剪枝、量化、靜態圖最佳化等,實作高效的推理。同時,TensorRT也提供了多種API和工具,如TensorRT-API、TensorRT-Server等,方便開發者進行模型的部署和推理。
CPU相關
1.對Arm或者x86有什麽了解?
Arm架構是一種精簡指令集(RISC)處理器架構,它的特點是低功耗、低成本和高效能。Arm架構廣泛套用於嵌入式系統設計,如手機、平板電腦、智慧家居等。由於Arm架構的低功耗特點,它非常適合移動通訊領域,符合其主要設計目標為低耗電的特性。
x86架構是一種復雜指令集(CISC)處理器架構,它的特點是支持多種指令集和作業系統,具有較高的相容性和擴充套件性。x86架構廣泛套用於個人電腦、伺服器、工作站等領域。由於x86架構的通用性和擴充套件性,它也適用於各種不同的套用場景,如遊戲、科學計算、人工智慧等。
在效能方面,Arm架構和x86架構各有優缺點。Arm架構具有低功耗和高效能的特點,但它的指令集相對較少,且不支持x86指令集和作業系統。而x86架構則具有較廣泛的指令集和作業系統支持,但它的功耗相對較高,且價格也相對較高。
2.知道CPU的體系結構嗎?介紹一下記憶體結構。
CPU的體系結構包括多個層次,從底層到高層依次是:
- 邏輯部件:包括算術邏輯運算單元(ALU)和移位操作器等,用於執行定點或浮點算術運算操作、移位操作以及邏輯操作,也可執行地址運算和轉換。
- 控制部件:負責控制CPU的操作,包括數據、控制和狀態的匯流排。
- 寄存器部件:包括通用寄存器、控制寄存器和狀態寄存器等。通用寄存器可保存指令執行過程中臨時存放的寄存器運算元和中間(或最終)的操作結果。
至於記憶體結構,通常包括以下幾個層次:
- Cache:快取(Cache)是一種位於CPU和主記憶體(Main Memory)之間的容量小但存取速度高的記憶體,用來存放CPU存取的主記憶體地址對映表及相應的數據,也可以說,快取就是數據與CPU間的一個「緩沖」。在快取中的數據存放是CPU近期存取過的數據,如果CPU再次需要這些數據時,可以直接從快取中讀取,而不需要再從主記憶體中讀取。
- 主記憶體:主記憶體是電腦硬體的一個重要組成部份,也稱記憶體或內儲存器,其作用是存放指令和數據,並能由中央處理器直接隨機存取。
- 外存:外存是指除電腦記憶體及CPU緩存以外的儲存器,此類儲存器一般斷電後仍然能保存數據。常見的外存有硬碟、軟碟、光碟等。
3.設計多CPU系統的時候需要註意什麽?如何保證緩存一致性?
設計多CPU系統時,需要註意以下幾個方面:
- 負載均衡:確保各個CPU之間的負載均衡,避免某些CPU過載而其他CPU處於閑置狀態。
- 通訊延遲:多CPU之間需要進行通訊,因此需要考慮通訊延遲對系統效能的影響。
- 記憶體一致性:多CPU存取同一記憶體區域時,需要保證記憶體一致性,避免出現數據不一致的問題。
為了保證緩存一致性,可以采用以下方法:
- 匯流排鎖:透過匯流排鎖機制,當一個CPU存取某個記憶體區域時,其他CPU無法存取該區域,直到第一個CPU完成存取。
- MESI協定:MESI協定是一種常用的緩存一致性協定,它定義了四種狀態:Modified(修改)、Exclusive(獨占)、Shared(共享)和Invalid(無效),用於表示緩存行在不同CPU之間的狀態。
- MOESI協定:MOESI協定是MESI協定的擴充套件,增加了Owner(擁有)狀態,用於表示緩存行在哪個CPU上。
- 寫回策略:當一個CPU修改某個記憶體區域時,需要將該區域寫回到主記憶體中,其他CPU的緩存行也需要相應地更新。
- 寫分配策略:當一個CPU需要寫入某個記憶體區域時,需要先將該區域分配到緩存中,然後再進行寫入操作。這樣可以保證寫入操作的一致性。
基本功
1.C++虛擬函式,使用場景,繼承時,解構函式設定成虛擬函式。
C++中的虛擬函式主要用於實作多型性,允許子類別重寫父類的函式。使用場景主要包括需要動態繫結函式行為的場合,如:
- 抽象基礎類別:虛擬函式允許衍生類別重寫基礎類別中的虛擬函式,使得在衍生類別中可以定義自己的行為。
- 動態繫結:虛擬函式使得在執行時根據物件的實際型別(子類別型別)確定要呼叫的函式,實作了動態繫結。
- 介面實作:虛擬函式可以用於實作介面,使得衍生類別必須實作介面中的所有虛擬函式,從而實作了多型性。
在繼承時,如果基礎類別的解構函式不是虛擬函式,那麽在衍生類別的物件銷毀時,只會呼叫衍生類別的解構函式,而不會呼叫基礎類別的解構函式。如果基礎類別的解構函式是虛擬函式,那麽在衍生類別的物件銷毀時,會先呼叫衍生類別的解構函式,然後再呼叫基礎類別的解構函式。這樣可以確保物件被正確地銷毀,避免了記憶體泄漏等問題。
因此,為了保證多型性和正確的記憶體管理,通常將基礎類別的解構函式設定為虛擬函式。
2.C++三大特性,動態多型和靜態多型。
C++中的三大特性是封裝、繼承和多型。
- 封裝:封裝是把抽象的數據(變量)和實作的方法(函式)封裝在一起,形成一個物件。這樣做的目的是隔離出影響範圍,讓程式碼更容易理解和維護。
- 繼承:繼承是從已有的類衍生出新的類,新的類能夠繼承現有類的各種內容和行為,並且可以增加新的能力。繼承可以提高程式碼的可重用性,減少程式碼冗余。
- 多型:多型是指允許衍生類別物件以基礎類別的方式表現自己。這是透過虛擬函式實作的,虛擬函式在基礎類別中聲明,在衍生類別中重寫。當透過基礎類別指標或參照呼叫虛擬函式時,會根據物件的實際型別呼叫相應的函式。
至於動態多型和靜態多型,它們都是多型性的表現形式,但實作方式和套用場景有所不同。
- 動態多型:透過虛擬函式實作的多型稱為動態多型。動態多型的實作是在執行時根據物件的實際型別確定要呼叫的函式。這種方式增加了程式的靈活性和可延伸性,因為可以在執行時根據需要選擇合適的函式。 一個類只能有一個虛擬函式表。在編譯時,一個類的虛擬函式表就確定了,這也是為什麽它放在了唯讀數據段中。 虛擬函式表是在編譯時確定的,屬於類而不屬於某個具體的例項。虛擬函式在程式碼段,僅有一份。
- 靜態多型:透過樣版實作的多型稱為靜態多型(例如 奇異遞迴樣版 CRTP ,一種樣版超編程技術,子類別型別作為樣版參數傳入父類,用於在靜態多型的情況下實作類似於虛擬函式的行為,而避免了虛擬函式表的開銷。它透過樣版的繼承和靜態多型性來實作動態多型性的效果。)。靜態多型的實作是在編譯時根據型別參數確定要使用的函式或類。這種方式可以提高程式碼的可重用性和可維護性,因為可以在編譯時檢查型別參數是否匹配,避免了執行時錯誤。
3.多繼承的問題,模版特化和偏特化。
多繼承是C++中的一個特性,它允許一個類從多個基礎類別繼承內容和行為。然而,多繼承也帶來了一些問題,其中最著名的是鉆石問題(Diamond Problem)。
鉆石問題發生在兩個基礎類別都繼承自一個共同的基礎類別,並且衍生類別同時繼承這兩個基礎類別時。在這種情況下,如果兩個基礎類別對衍生類別有不同的成員函式實作,那麽在衍生類別中就會有兩個不同的函式實作可供選擇,導致二義性。
為了解決鉆石問題,C++提供了兩種特化方式:樣版特化和偏特化。
- 樣版特化:樣版特化是一種通用的特化方式,它針對特定的型別進行特化。在樣版特化中,可以為特定的型別定義一個新的函式實作,該實作將覆蓋在基礎類別中的函式實作。這樣可以確保在衍生類別中只使用特化後的函式實作,避免了二義性。例如,假設有兩個基礎類別Base1和Base2都繼承自一個共同的基礎類別Base,並且衍生類別Derived同時繼承了Base1和Base2。如果Base1和Base2都定義了一個名為foo的成員函式,那麽在Derived中就會有兩個不同的foo函式可供選擇。為了解決這個問題,可以定義一個樣版特化,為Derived型別提供一個新的foo函式實作。這樣,在Derived中呼叫foo函式時,將只使用特化後的函式實作,避免了二義性。
- 偏特化:偏特化是一種更具體的特化方式,它只針對特定的類進行特化。在偏特化中,可以為特定的類別定義一個新的函式實作,該實作將覆蓋在該類及其所有衍生類別中的函式實作。這樣可以確保在衍生類別中只使用偏特化後的函式實作,避免了二義性。例如,假設有兩個基礎類別Base1和Base2都繼承自一個共同的基礎類別Base,並且衍生類別Derived1和Derived2都繼承了Base1和Base2。如果Base1和Base2都定義了一個名為foo的成員函式,那麽在Derived1和Derived2中就會有兩個不同的foo函式可供選擇。為了解決這個問題,可以定義一個偏特化,為Derived1和Derived2型別提供一個新的foo函式實作。這樣,在Derived1和Derived2中呼叫foo函式時,將只使用偏特化後的函式實作,避免了二義性。
4.說一下執行緒和行程的區別,執行緒之間共享內容,行程和執行緒通訊。
執行緒和行程的區別:行程可以類比為一個餐廳,而執行緒就是在餐廳裏面工作的員工
執行緒之間共享內容:
行程和執行緒通訊:
5.靜態庫和動態庫的原理,符號表,單例模式。
靜態庫和動態庫的原理:
符號表:
單例模式:
6.快速排序,歸並排序,堆排序時間復雜度一樣,結合CPU的緩存存取來看,哪個效率最高?
快速排序、歸並排序和堆排序的時間復雜度在理論上的平均情況或最壞情況下是相同的,都是O(n log n)。但是,實際效率會受到許多因素的影響,其中之一就是CPU的緩存存取模式。
在現代電腦架構中,CPU的緩存是一個重要的效能因素。由於記憶體存取速度遠遠慢於CPU的處理速度,因此CPU通常會使用多級緩存來儲存最近存取的數據。當數據在緩存中時,存取速度會非常快,這稱為緩存命中。如果數據不在緩存中,則需要從主記憶體中獲取,這稱為緩存未命中,並且會導致顯著的延遲。
考慮到這一點,以下是這三種排序演算法在CPU緩存方面的效能分析:
- 快速排序 :快速排序通常具有優秀的緩存局部性。這是因為它采用分而治之的策略,將數據劃分為較小的子陣列,並在遞迴過程中處理這些子陣列。這些子陣列通常能夠很好地適應緩存的大小,從而減少緩存未命中的次數。
- 歸並排序 :歸並排序在合並步驟中可能會表現出較差的緩存效能。當合並兩個已排序的子陣列時,通常需要不斷地在兩個陣列之間來回切換,這可能導致頻繁的緩存未命中。然而,歸並排序在處理連結串列或外部排序(數據不能完全載入到記憶體中)時可能是一個更好的選擇。
- 堆排序 :堆排序在構建和調整堆的過程中可能會表現出較差的緩存局部性。因為它需要不斷地在堆的頂部和底部之間行動資料,這可能導致非連續的記憶體存取和緩存未命中。
從CPU緩存的角度來看,快速排序通常具有更好的效能。然而,實際效能還會受到其他因素的影響,如數據的分布、輸入規模、硬體特性等。
7.程式碼和檔較多時,如何定位記憶體錯誤的問題?
- 使用偵錯工具 :大多數現代程式語言都有內建的偵錯工具或偵錯程式,可以幫助你定位和解決記憶體錯誤。例如,如果你使用的是C++,你可以使用GDB或Visual Studio的偵錯程式。如果你使用的是Python,你可以使用pdb或PyCharm的偵錯程式。
- 程式碼審查 :仔細審查你的程式碼,尋找可能導致記憶體泄漏或錯誤的常見問題。例如,檢查是否正確地釋放了所有的資源,是否正確地關閉了所有的檔和網路連線,以及是否正確地處理了所有的異常。
- 使用記憶體分析工具 :記憶體分析工具可以幫助你檢視程式執行時的記憶體使用情況。例如,如果你使用的是C++,你可以使用Valgrind、Massif以及ASAN工具。如果你使用的是Python,你可以使用memory_profiler工具。
- 代分碼解 :將復雜的代分碼解成更小的、更易於管理的部份。這樣可以幫助你更容易地找到問題所在。
- 簡化問題 :嘗試簡化你的程式碼,移除可能導致問題的部份。這樣可以幫助你更快地找到問題所在。
- 閱讀錯誤訊息 :當程式崩潰或出現錯誤時,仔細閱讀錯誤訊息。錯誤訊息通常會提供有關問題的詳細資訊,包括錯誤發生的檔和行號。
- 搜尋相關問題 :在搜尋引擎中搜尋你的錯誤訊息,看看是否有其他人遇到過類似的問題,並找到了解決方案。
- 尋求幫助 :如果你無法解決你的問題,可以向你的同事、朋友或線上社群尋求幫助。他們可能能夠提供新的觀點或建議。
手撕演算法題
1.CUDA Reduction或者向量相乘等可以轉化為Reduction的Kernel。
Reduction操作通常用於將一個數據集中的元素進行歸約操作,例如求和、最大值、最小值等。透過將Reduction操作轉化為Kernel函式,可以充分利用GPU的並列處理能力,提高計算效率。
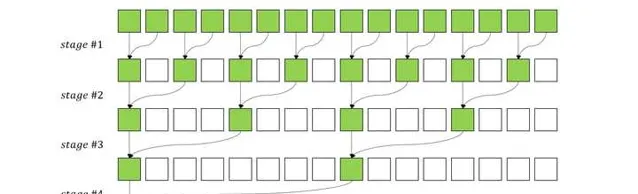
template
<
typename
T
,
int
blockSize
>
__global__
void
reduce_kernel_1
(
const
T
*
data
,
const
size_t
n
,
T
*
result
)
{
__shared__
T
sdata
[
blockSize
];
// 共享記憶體中聲明一個大小為 blockSize 的陣列 sdata。
//獲得當前 thread 在 block 中的索引 tid,以及當前需要處理元素在 data 中的全域索引 globalId。
//再將數據從全域記憶體載入共享記憶體,如果 globalId 超過了陣列大小,則將對應位置的元素設定為 0
int
tid
=
threadIdx
.
x
;
int
globalId
=
threadIdx
.
x
+
blockIdx
.
x
*
blockDim
.
x
;
sdata
[
tid
]
=
globalId
>=
n
?
0
:
data
[
globalId
];
__syncthreads
();
//同步當前 block 中的所有 thread,直到所有數據拷貝完成。
//在每個 stage 中,只有能被 2 * s 整除的 thread 才會參與計算,比如,
//當 s = 1 時,只有 tid = 0, 2, 4, 6, ... 的 thread 參與計算,
//當 s = 2 時,只有 tid = 0, 4, 8, 12, ... 的 thread 參與計算,以此類推。
for
(
int
s
=
1
;
s
<
blockSize
;
s
*=
2
)
{
// 參與計算的兩個元素位置為 tid 和 tid + s,計算結果被賦予 tid 所在位置。
if
(
tid
%
(
2
*
s
)
==
0
)
{
sdata
[
tid
]
+=
sdata
[
tid
+
s
];
}
__syncthreads
();
//在兩次 stage 之間,需要呼叫 __syncthreads() 同步方法確保當前 stage 的所有元素完成計算。
}
//由於每個 stage 之後,s 都會翻倍,因此總的 stage 數量為 log2(blockSize)
//最終規約結果被保存在了 sdata[0],因此只需要 thread #0 將 sdata[0] 的數據加到 result 的第一個位置即可,
//這裏使用 atomicAdd 確保多個 block 不會發生沖突。
if
(
tid
==
0
)
{
atomicAdd
(
&
result
[
0
],
sdata
[
0
]);
}
}
2.CUDA實作陣列排序演算法(雙調排序)
當序列的前半段和後半段都是單調的時候,或者可以透過迴圈移位使前半段和後半段都是單調的時候,該序列就稱作雙調序列.
歸並實作
bool
compare
(
int
a
,
int
b
,
bool
descending
=
true
)
{
return
(
a
<
b
&&
descending
)
||
(
a
>
b
&&
!
descending
);
}
void
mergeSort
(
int
*
a
,
int
n
,
bool
descending
=
true
)
{
int
stride
=
n
>>
1
;
int
t
=
0
;
for
(
int
i
=
0
,
j
=
stride
;
i
<
stride
;
i
++
,
j
++
)
{
if
(
compare
(
a
[
i
],
a
[
j
],
descending
))
// 兩半對應元素組個比較交換
{
t
=
a
[
j
];
a
[
j
]
=
a
[
i
];
a
[
i
]
=
t
;
}
}
if
(
stride
>=
2
)
{
mergeSort
(
a
,
stride
,
descending
);
// 前半段
mergeSort
(
a
+
stride
,
stride
,
descending
);
// 後半段
}
}
void
hBitonicSortRecursive
(
int
*
a
,
int
n
,
bool
descending
)
{
int
stride
=
2
;
int
inter_step
=
1
;
while
(
stride
<=
n
)
{
inter_step
=
(
stride
<<
1
);
// Order
for
(
int
i
=
0
;
i
<
n
;
i
+=
inter_step
)
{
mergeSort
(
a
+
i
,
stride
,
descending
);
}
// Reverse order
for
(
int
i
=
stride
;
i
<
n
;
i
+=
inter_step
)
{
mergeSort
(
a
+
i
,
stride
,
!
descending
);
}
stride
=
inter_step
;
}
迴圈實作
void
hBitonicSort
(
int
*
a
,
int
n
,
bool
descending
)
{
int
t
=
0
;
int
half_stride
=
1
,
hs
=
1
,
s
=
2
;
int
hn
=
n
>>
1
;
for
(
int
stride
=
2
;
stride
<=
n
;
stride
<<=
1
)
{
s
=
stride
;
while
(
s
>=
2
)
{
hs
=
s
>>
1
;
for
(
int
i
=
0
;
i
<
hn
;
i
++
)
{
bool
orange
=
(
i
/
half_stride
)
%
2
==
0
;
int
j
=
(
i
/
hs
)
*
s
+
(
i
%
hs
);
int
k
=
j
+
hs
;
//printf("Stride: %d, s: %d, i: %d, j: %d, k: %d\n", stride, s, i, j, k);
if
((
descending
&&
((
orange
&&
a
[
j
]
<
a
[
k
])
||
(
!
orange
&&
a
[
j
]
>
a
[
k
])))
||
(
!
descending
&&
((
orange
&&
a
[
j
]
>
a
[
k
])
||
(
!
orange
&&
a
[
j
]
<
a
[
k
]))))
{
t
=
a
[
k
];
a
[
k
]
=
a
[
j
];
a
[
j
]
=
t
;
}
}
s
=
hs
;
}
half_stride
=
stride
;
}
}
cuda核實作
__global__
void
gBitonicSort
(
int
*
a
,
int
n_p
,
bool
descending
)
{
unsigned
int
tid
=
threadIdx
.
x
;
int
stride_p
,
half_stride_p
,
s_p
,
hs_p
,
hs
,
i
,
j
,
k
,
t
,
hn
;
bool
orange
;
hn
=
1
<<
(
n_p
-
1
);
half_stride_p
=
0
;
for
(
stride_p
=
1
;
stride_p
<=
n_p
;
stride_p
++
)
{
s_p
=
stride_p
;
while
(
s_p
>=
1
)
{
hs_p
=
s_p
-
1
;
hs
=
1
<<
hs_p
;
for
(
i
=
tid
;
i
<
hn
;
i
+=
blockDim
.
x
)
{
orange
=
(
i
>>
half_stride_p
)
%
2
==
0
;
j
=
((
i
>>
hs_p
)
<<
s_p
)
+
(
i
%
hs
);
k
=
j
+
hs
;
if
((
descending
&&
((
orange
&&
a
[
j
]
<
a
[
k
])
||
(
!
orange
&&
a
[
j
]
>
a
[
k
])))
||
(
!
descending
&&
((
orange
&&
a
[
j
]
>
a
[
k
])
||
(
!
orange
&&
a
[
j
]
<
a
[
k
]))))
{
t
=
a
[
k
];
a
[
k
]
=
a
[
j
];
a
[
j
]
=
t
;
}
}
__syncthreads
();
s_p
=
hs_p
;
}
half_stride_p
++
;
}
}
3.CUDA不考慮共享記憶體,只使用全域記憶體來做向量矩陣乘法,向量是行主序,矩陣乘向量和向量乘矩陣哪種訪存和計算模式更好?說一說哪種用到了歸約?
4.有n個執行緒和n個元素,在logn時間內對n個元素進行排序。
5.leetcode常見面試百題和魔改題。
TODO
-
兩數之和(簡單)
-
合並兩個有序陣列(簡單)
-
移動零(簡單)
-
斐波那契數(簡單)
-
兩數之積(簡單)
-
最長回文子串(簡單)
-
三數之和(簡單)
-
最長遞增子序列(簡單)










